使用TensorBoard进行超参数优化
在本文中,我们将介绍超参数优化,然后使用TensorBoard显示超参数优化的结果。
深度神经网络的超参数是什么?
深度学习神经网络的目标是找到节点的权重,这将帮助我们理解图像、文本或语音中的数据模式。
要做到这一点,可以使用为模型提供最佳准度和精度的值来设计神经网络参数。
那么,这些被称为超参数的参数是什么呢?
用于训练神经网络模型的不同参数称为超参数。这些超参数像旋钮一样被调优,以提高神经网络的性能,从而产生一个优化的模型。超参数的一个通俗的解释是:用来优化参数的参数。
神经网络中的一些超参数是:
- 隐藏层的数量
- 隐含层中单位或节点的集合的数量
- 学习速率
- DropOut比例
- 迭代次数
- 优化器的选择如SGD, Adam, AdaGrad, Rmsprop等
- 激活函数选择如ReLU, sigmoid, leaky ReLU等
- 批次大小
如何实现超参数优化?
超参数优化是寻找深度学习算法的优化器、学习率、等超参数值,从而获得最佳模型性能的过程。
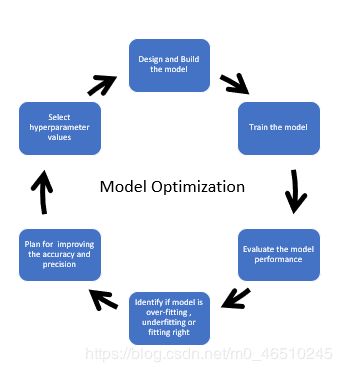
可以使用以下技术执行超参数优化。
- 手动搜索
- 网格搜索:对指定超参数的所有可能组合进行穷举搜索,从而得到笛卡尔积。
- 随机搜索:超参数是随机选择的,不是每一个超参数的组合都被尝试。随着超参数数量的增加,随机搜索是一个更好的选择,因为它可以更快地得到超参数的良好组合。
- 贝叶斯优化:整合关于超参数的先验数据,包括模型的准确性或损失。先验信息有助于确定模型超参数选择的更好近似。
为了在TensorBoard中可视化模型的超参数并进行调优,我们将使用网格搜索技术,其中我们将使用一些超参数,如不同的节点数量,不同的优化器,或学习率等看看模型的准确性和损失。
为什么使用TensorBoard进行超参数优化?
一幅图片胜过千言万语,这也适用于复杂的深度学习模型。深度学习模型被认为是一个黑盒子,你发送一些输入数据,模型做一些复杂的计算,输出结果。
TensorBoard是Tensorflow的一个可视化工具包,用于显示不同的指标、参数和其他可视化,帮助调试、跟踪、微调、优化和共享深度学习实验结果
TensorBoard可以跟踪模型在每个训练迭代的精度和损失;
还有不同的超参数值。不同超参数值的跟踪精度将帮助您更快地微调模型。
我们将使用猫和狗数据集使用TensorBoard可视化标量、图形和分布。
https://www.kaggle.com/c/dogs-vs-cats/data
导入所需的库
导入TensorFlow和TensorBoard HParams插件以及Keras库来预处理图像和创建模型。
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
import datetime
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
import numpy as np
加载TensorBoard notebook扩展
# Load the TensorBoard notebook extension
%load_ext tensorboard
创建图像分类的深度学习模型
为训练设置关键参数
BASE_PATH = 'Data\\dogs-vs-cats\\train\\'
TRAIN_PATH='Data\\dogs-vs-cats\\train_data\\'
VAL_PATH='Data\\dogs-vs-cats\\validation_data\\'batch_size = 32
epochs = 5
IMG_HEIGHT = 150
IMG_WIDTH = 150
对训练图像进行缩放和不同的增强
train_image_generator = ImageDataGenerator(
rescale=1./255,
rotation_range=45,
width_shift_range=.15,
height_shift_range=.15,
horizontal_flip=True,
zoom_range=0.3)
重新调节验证数据
validation_image_generator = ImageDataGenerator(rescale=1./255)
为训练和验证生成成批的规范化数据
train_data_gen = train_image_generator.flow_from_directory(
batch_size = batch_size,
directory=TRAIN_PATH,
shuffle=True,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='categorical')
val_data_gen = validation_image_generator.flow_from_directory(batch_size = batch_size,
directory=VAL_PATH,
target_size=(IMG_HEIGHT, IMG_WIDTH),
class_mode='categorical')
为网格搜索(Grid Search)设置超参数
我们通过列出超参数的不同值或取值范围,使用了四个超参数来运行我们的实验。
对于离散超参数,将尝试所有可能的参数组合,对于实值参数,只使用下界和上界。
第一层的单元数量:256和512
dropout比例:范围在0.1到0.2之间。所以dropout比例是0。1和0。2。
优化器:adam, SGD, rmsprop
优化器的学习率:0.001,0.0001和0.0005,
我们还将准确率显示在TensorBoard 上
## Create hyperparameters
HP_NUM_UNITS=hp.HParam('num_units', hp.Discrete([ 256, 512]))
HP_DROPOUT=hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_LEARNING_RATE= hp.HParam('learning_rate', hp.Discrete([0.001, 0.0005, 0.0001]))
HP_OPTIMIZER=hp.HParam('optimizer', hp.Discrete(['adam', 'sgd', 'rmsprop']))METRIC_ACCURACY='accuracy'
创建和配置日志文件
log_dir ='\\logs\\fit\\' + datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
with tf.summary.create_file_writer(log_dir).as_default():
hp.hparams_config(
hparams=
[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER, HP_LEARNING_RATE],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
创建、编译和训练模型
超参数不是硬编码的,但从hparams字典为不同的参数:HP_DROPOUT , HP_NUM_UNITS ,HP_OPTIMIZER ,HP_LEARNING_RATE。
函数返回最后一个批次的验证准确性。
def create_model(hparams):
model = Sequential([
Conv2D(64, 3, padding='same', activation='relu',
input_shape=(IMG_HEIGHT, IMG_WIDTH ,3)),
MaxPooling2D(),
#setting the Drop out value based on HParam
Dropout(hparams[HP_DROPOUT]),
Conv2D(128, 3, padding='same', activation='relu'),
MaxPooling2D(),
Dropout(hparams[HP_DROPOUT]),
Flatten(),
Dense(hparams[HP_NUM_UNITS], activation='relu'),
Dense(2, activation='softmax')])
#setting the optimizer and learning rate
optimizer = hparams[HP_OPTIMIZER]
learning_rate = hparams[HP_LEARNING_RATE]
if optimizer == "adam":
optimizer = tf.optimizers.Adam(learning_rate=learning_rate)
elif optimizer == "sgd":
optimizer = tf.optimizers.SGD(learning_rate=learning_rate)
elif optimizer=='rmsprop':
optimizer = tf.optimizers.RMSprop(learning_rate=learning_rate)
else:
raise ValueError("unexpected optimizer name: %r" % (optimizer_name,))
# Comiple the mode with the optimizer and learninf rate specified in hparams
model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy'])
#Fit the model
history=model.fit_generator(
train_data_gen,
steps_per_epoch=1000,
epochs=epochs,
validation_data=val_data_gen,
validation_steps=1000,
callbacks=[
tf.keras.callbacks.TensorBoard(log_dir), # log metrics
hp.KerasCallback(log_dir, hparams),# log hparams
])
return history.history['val_accuracy'][-1]
对于模型的每次运行,使用超参数和最终批次精度记录hparams都会被纪律。我们需要将最后一个批次的验证精度转换为标量值。
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = create_model(hparams)
#converting to tf scalar
accuracy= tf.reshape(tf.convert_to_tensor(accuracy), []).numpy()
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
用不同的超参数值运行模型
这里的实验使用网格搜索,并测试第一层单元数的所有可能的超参数组合,Dropout比例、优化器及其学习率,以及准确度用于准确性。
session_num = 0for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
for learning_rate in HP_LEARNING_RATE.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
HP_LEARNING_RATE: learning_rate,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
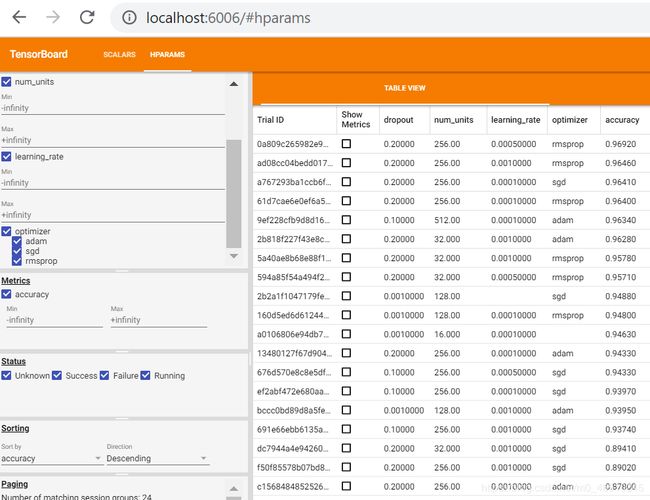
在HParams中可视化结果
python -m tensorboard.main --logdir="logs/hparam_tuning"
当按精度降序排序时,可以看到最优化的模型是256台,dropout比例为0.2,rmsprop优化器学习率为0.0005。
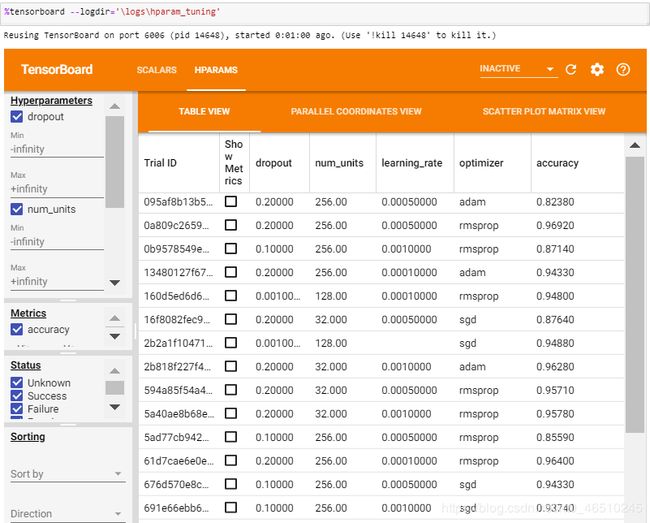
在jupyter notebook中可以使用以下命令查看
%tensorboard --logdir='\logs\hparam_tuning'
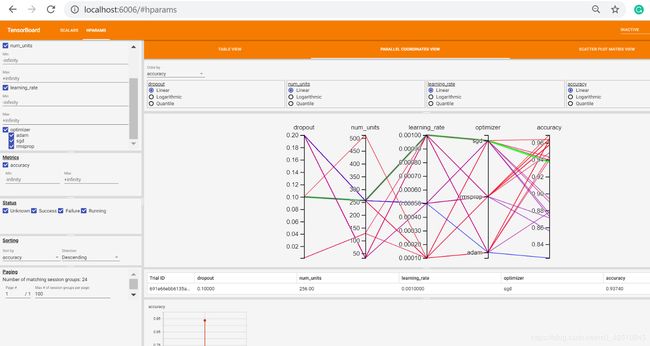
在Tensorboard中使用Parallel Coordinates视图,显示每个超参数的单独运行情况并显示精度,查找最优化的超参数,以获得最佳的模型精度
总结
Tensorboard为超参数调优提供了一种可视化的方式来了解哪些超参数可以用于微调深度学习模型以获得最佳精度,更多的操作可以查看官方文档:
https://www.tensorflow.org/tensorboard/hyperparameter_tuning_with_hparams
作者:Renu Khandelwal
deephub翻译组