大数据学习(十)mapjoin reducejoin
目的
我们一开始有两个数据,一个是学生表

另一个是选课表
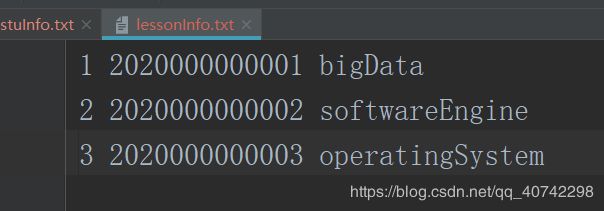
注:实际情况中学生表是一个比较小的表,二选课表是大表
我们通过mapreduce程序实现将选课表中的学号换成姓名。得到新的数据
mapjoin
目录结构
这一次并不需要用到reduce阶段,但是在reducejoin中会使用。我们先看相对简单的mapjoin。
先看代码
mapClass
package mapJoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: Braylon
* @Date: 2020/1/26 14:38
* @Version: 1.0
*/
public class mapClass extends Mapper<LongWritable, Text, Text, NullWritable> {
Map<String, String> globalMap = new HashMap<>();
//setup方法在被Mapreduce框架只执行一次,在执行map任务之前,进行相关变量或者资源的初始化工作。
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("D:\\idea\\HDFS\\src\\main\\java\\mapJoin\\stuInfo.txt")), "UTF-8"));
String tmp;
while (StringUtils.isNotEmpty(tmp = reader.readLine())) {
String[] arr = tmp.split(" ");
globalMap.put(arr[0], arr[1]);
}
reader.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text k = new Text();
String line = value.toString();
String[] split = line.split(" ");
String id = split[0];
String sid = split[1];
String lesson = split[2];
String name = globalMap.get(sid);
String valueOut = id + "\001" + name + "\001" + lesson;
k.set(valueOut);
context.write(k, NullWritable.get());
}
}
这里重要的知识点其实只有两个,其他的大家可以参考我原来的blog。
- 首先是map阶段的输入和输出的数据类型,也就是r
前两个不必多说,分别是游标(行号)和读取每一行的字符串,后两个是map阶段的输出类型,也就是我们输出的就是最终的结果valueOut = id + “\001” + name + “\001” + lesson(是个字符串),然后最后一个不需要,所以就用NullWritable。
- 重写了setup方法,这个方法,setup方法在被Mapreduce框架只执行一次,在执行map任务之前,进行相关变量或者资源的初始化工作。
简单来说就是,这次的逻辑需要用到两个文件,所以需要先读取学生 表的文件信息,再在map阶段进行替换生成新的数据组合。
driver类
package mapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @Author: Braylon
* @Date: 2020/1/26 14:57
* @Version: 1.0
*/
public class driver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
args = new String[]{"lessonInfo.txt", "out"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(driver.class);
job.setMapperClass(mapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.addCacheFile(new URI("file:////D:/idea/HDFS/src/main/java/mapJoin/stuInfo.txt"));
job.setNumReduceTasks(0);//不需要reduce
job.waitForCompletion(true);
}
}
这个需要说的就是一个:
- job.addCacheFile(new URI(“file:////stuInfo.txt”));
这个很重要,字面理解就是将这个文件增加到了缓存,主要原因就是,这是一个小文件,在多次的读取的情况下会大大增加程序的效率。这在实际应用中也是一个比较重要的技巧。
reduceJoin
上一个是比较简单的join程序,并且没有用到reduce阶段
下面我们同样解决上述问题,但是我们发现在实际的应用中往往是很多的文件进行处理和信息的读取组合,怎么可能都在setup阶段呢,所以我们有更有针对性的处理方法。
目录结构

代码:
databean类
package reduceJoin;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/26 15:52
* @Version: 1.0
*/
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class dataBean implements Writable {
private String sid;
private String name;
private String lid;
private String lName;
private Integer flag;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(sid);
dataOutput.writeUTF(name);
dataOutput.writeUTF(lid);
dataOutput.writeUTF(lName);
dataOutput.writeInt(flag);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.sid = dataInput.readUTF();
this.name = dataInput.readUTF();
this.lid = dataInput.readUTF();
this.lName = dataInput.readUTF();
this.flag = dataInput.readInt();
}
@Override
public String toString() {
return lid + "\001" + name + "\001" + lName + "\n";
}
}
序列化的知识点大家可以看前面的blog
这里其实没什么可说的
map类
package reduceJoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/26 15:51
* @Version: 1.0
*/
public class mapClass extends Mapper<LongWritable, Text, Text, dataBean> {
Text k = new Text();
dataBean bean = new dataBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
FileSplit filesplit = (FileSplit) context.getInputSplit();
String fName = filesplit.getPath().getName();
if (fName.startsWith("stuInfo")) {
String[] field = value.toString().split(" ");
bean.setFlag(0);
bean.setSid(field[0]);
bean.setName(field[1]);
bean.setLid("");
bean.setLName("");
} else if (fName.startsWith("lessonInfo")) {
String[] field = value.toString().split(" ");
bean.setFlag(1);
bean.setSid(field[1]);
bean.setName("");
bean.setLid(field[0]);
bean.setLName(field[2]);
}
k.set(bean.getSid());
context.write(k, bean);
}
}
知识点:
- FileSplit filesplit = (FileSplit) context.getInputSplit();
这样做的原因就是可以知道读取的数据隶属的文件名,这样就可以通过流程控制进行不同文件的数据处理。
reduce类
package reduceJoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
/**
* @Author: Braylon
* @Date: 2020/1/26 16:10
* @Version: 1.0
*/
public class reduceClass extends Reducer<Text, dataBean, dataBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<dataBean> values, Context context) throws IOException, InterruptedException {
ArrayList<dataBean> dataBeans = new ArrayList<>();
dataBean bean = new dataBean();
for (dataBean b0 : values) {
if (b0.getFlag().equals(0)) {
try {
BeanUtils.copyProperties(bean, b0);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
} else if (b0.getFlag().equals(1)) {
dataBean tmpBean = new dataBean();
try {
BeanUtils.copyProperties(tmpBean,b0);
dataBeans.add(tmpBean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
for (dataBean b0 : dataBeans) {
b0.setName(bean.getName());
context.write(b0,NullWritable.get());
}
}
}
知识点:
- 这里有一个逻辑问题可能比较绕人,
首先我们定义了一个arraylist来存储每一个选课表的实体,注意这个list中的每个对象都是缺少name属性的。然后我们定义了一个dataBean对象,来存储学生表的信息,但是为什么这个就是不是一个list呢,因为学生表一定是唯一的也就是说,对于唯一的学号一定只有一个dataBean对象有name属性。
然后我们for循环将每一个选课表对象增加name属性。
driver类
package reduceJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @Author: Braylon
* @Date: 2020/1/26 16:19
* @Version: 1.0
*/
public class driverClass {
public static void main(String[] args) throws IOException {
args = new String[]{"resource", "out"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(driverClass.class);
job.setMapperClass(mapClass.class);
job.setReducerClass(reduceClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(dataBean.class);
job.setOutputKeyClass(dataBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
try {
job.waitForCompletion(true);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
注意这里我写的args的输入不再是一个单独的txt文件而是一个有很多txt文件的文件夹。