牛客网sql练习题解(22-32)
文章目录
- 简介
- NO.22
- NO.23
- NO.24
- NO.25
- NO.26
- NO.27
- NO.28
- NO.29
- NO.30
- NO.31
- NO.32
简介
往期文章:
牛客网sql练习题解 (1-11)
牛客网sql练习题解(12-21)
牛客网sql练习题解(22-32)
牛客网sql练习题解(34-42)
NO.22

这里面有一个小技巧即使怎么获得当前salary的排名,也就是子查询中的写法,这是一个比较常用的方法。值得记住。
select s.emp_no, s.salary, tmp.rank as rank
from salaries s inner join (
select distinct s1.salary, count(distinct s2.salary) as rank
from salaries s1, salaries s2
where s1.to_date = '9999-01-01' and s2.to_date = '9999-01-01'
and s1.salary <= s2.salary
group by s1.salary
) as tmp
on s.salary = tmp.salary
where s.to_date = '9999-01-01'
order by s.salary desc, s.emp_no;

NO.23
select de.dept_no, de.emp_no, s.salary
from dept_emp de, salaries s, employees e
where de.emp_no = s.emp_no and s.emp_no = e.emp_no
and s.to_date = '9999-01-01' and s.emp_no not in (
select emp_no from dept_manager
where to_date = '9999-01-01'
);

NO.24

select de.emp_no,dm.emp_no as manager_no, s1.salary as emp_salary, s2.salary as manager_salary
from dept_emp de, dept_manager dm, salaries s1, salaries s2
where de.emp_no = s1.emp_no and de.dept_no = dm.dept_no and dm.emp_no = s2.emp_no and
s1.salary > s2.salary and
s1.to_date = '9999-01-01' and
s2.to_date = '9999-01-01';
NO.25

这里注意一下group by的连用吧,就是对多个col进行group by,注意加逗号啊
select d.dept_no, d.dept_name, t.title, count(*) as "count"
from departments d, dept_emp de, titles t
where d.dept_no = de.dept_no and de.emp_no = t.emp_no
and de.to_date = '9999-01-01'
and t.to_date = '9999-01-01'
group by d.dept_no, d.dept_name, t.title
order by d.dept_no;
NO.26

这道题的关键就是strftime函数的使用
strftime函数可以YYYY-MM-DD HH:MM:SS格式的日期字符串转换成其他形式的字符串。
strftime的语法是
strftime(格式,日期/时间, 修正符号、修正符号…)
还有我使用了cast函数,
用法是:
cast(col1 as 类型)
用于类型转化
select s1.emp_no, s2.from_date, (s2.salary - s1.salary) as salary_growth
from salaries s1, salaries s2
where s1.emp_no = s2.emp_no
and (cast(STRFTIME('%Y', s2.from_date) as tinyint) - cast(STRFTIME('%Y', s1.from_date) as tinyint) = 1
or cast(STRFTIME('%Y', s2.to_date) as tinyint) - cast(STRFTIME('%Y', s1.to_date) as tinyint) = 1
)
and salary_growth > 5000
order by salary_growth desc;
NO.27

select c.name, count(fc.film_id)
from film f, category c, film_category fc
where f.description like '%robot%'
and c.category_id = fc.category_id
and fc.film_id = f.film_id
and c.category_id in (
select category_id
from film_category
group by category_id
having count(film_id) >= 5
)
group by c.category_id;
我觉得这一道题问的很模糊,反正我一开始写错了就是因为理解错了,这里注意一下like的用法吧,别的没什么重点。
NO.28

常规操作
select f.film_id, f.title
from film f
where f.film_id not in (
select f1.film_id
from film f1 join film_category fc1
on f1.film_id = fc1.film_id
);

附赠一个方法二不用子查询:
select f.film_id, f.title
from film f left join film_category fc
on f.film_id = fc.film_id
where fc.category_id is NULL;
这里需要注意is NULL,可不是= NULL
NO.29

这题比较简单,唯一我觉得稍微注意一些的,把子查询放在where会比较好一些,当然放在from里面也没有错误。
select f.title, f.description
from film f inner join film_category fc
on f.film_id = fc.film_id
where fc.category_id in (
select category_id
from category
where name = 'Action'
);
NO.30
这题应该是系统有bug,至少我做的时候有bug,跳过。
NO.31

这题简单明了,我喜欢,就是考察一个知识点,就是字符串的连接。
这和数据库的版本和环境有关系,
MySql支持CONCAT方法:
select CONCAT(CONCAT(last_name, " "), first_name) as Name
-- select CONCAT(last_name," ",first_name) as name from employees
from employees;
但是这是sqlite的环境:
select (last_name || " " || first_name) as Name
from employees;

NO.32
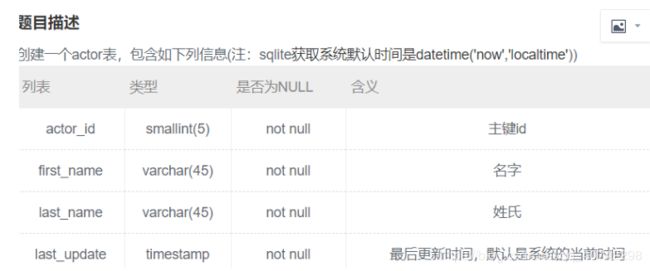
这怎么越做越回去呢??
create table actor(
actor_id smallint(5) not null,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update timestamp not null default (datetime('now', 'localtime')),
primary key(actor_id)
);
简单记录,不喜勿喷
大家共勉~