感知机(一)——原理篇
判别模型
线性分类模型
文章目录
- 模型
- 策略
- 算法
模型
感知机是根据输入实例的特征向量 x x x对其进行二类分类的线性分类模型,由输入空间到输出空间的函数为:
(*) f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w·x+b)\tag{*} f(x)=sign(w⋅x+b)(*)
其中 w w w和 b b b为感知机模型参数, w w w称作权值或权值向量, b b b称作偏置;
w ⋅ x w·x w⋅x表示二者的内积,Eg. w = ( w ( 1 ) , w ( 2 ) ) T , x = ( x ( 1 ) , x ( 2 ) ) T w=(w^{(1)},w^{(2)})^{T}, x=(x^{(1)},x^{(2)})^{T} w=(w(1),w(2))T,x=(x(1),x(2))T,则 w ⋅ x = w ( 1 ) x ( 1 ) + w ( 2 ) x ( 2 ) w·x=w^{(1)}x^{(1)}+w^{(2)}x^{(2)} w⋅x=w(1)x(1)+w(2)x(2);
s i g n sign sign为符号函数, s i g n ( x ) = { + 1 , x ≥ 0 − 1 , x < 0 sign(x)=\left\{ \begin{array}{rcl} +1, & x\geq 0 \\ -1, & x<0\\ \end{array} \right. sign(x)={+1,−1,x≥0x<0
线性方程 w ⋅ x + b = 0 w·x+b=0 w⋅x+b=0 对应于输入空间(特征空间)中的分离超平面,这个超平面将特征空间划分为两个部分,位于两部分的点分别为正、负两类。
其中 w w w是超平面的法向量, b b b是超平面的截距。
策略
损失函数极小化,在假设空间中选取使损失函数最小的模型参数 w , b w,b w,b
(A) min w , b L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) \mathop{\min}\limits_{w,b} L(w,b)=-\sum\limits_{x_i\in M}y_i(w·x_i+b)\tag{A} w,bminL(w,b)=−xi∈M∑yi(w⋅xi+b)(A)
损失函数的几何意义:误分类点到分离超平面的总距离
损失函数的推导过程:
点到直线的距离公式
给定直线方程为 A x ′ + B y ′ + C = 0 Ax'+By'+C=0 Ax′+By′+C=0,点 P P P的坐标为 ( x 0 ′ , y 0 ′ ) (x_0',y_0') (x0′,y0′),则点到直线的距离为
d = ∣ A x 0 ′ + B y 0 ′ + C ∣ A 2 + B 2 d=\frac{|Ax_0'+By_0'+C|}{\sqrt{A^2+B^2}} d=A2+B2∣Ax0′+By0′+C∣
令 w = ( A , B ) T , x 0 = ( x 0 ′ , y 0 ′ ) T , b = C w=(A,B)^T,x_0=(x_0',y_0')^T,b=C w=(A,B)T,x0=(x0′,y0′)T,b=C,则空间中某一点到平面的距离为
d = ∣ w ⋅ x 0 + b ∣ A 2 + B 2 = ∣ w ⋅ x 0 + b ∣ ∣ ∣ w ∣ ∣ = 1 ∣ ∣ w ∣ ∣ ∣ w ⋅ x 0 + b ∣ d=\frac{|w·x_0+b|}{\sqrt{A^2+B^2}}=\frac{|w·x_0+b|}{||w||}=\frac{1}{||w||}|w·x_0+b| d=A2+B2∣w⋅x0+b∣=∣∣w∣∣∣w⋅x0+b∣=∣∣w∣∣1∣w⋅x0+b∣
其中 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣是指 w w w的 L 2 L_2 L2范数。
范数
参考文献:范数、L1范数和L2范数的基本概念
范数,是具有“长度”概念的函数,它常被用来度量某个向量空间中的每个向量的长度或大小。
若 x = [ x 1 , x 2 , ⋅ ⋅ ⋅ , x n ] T x=[x_1,x_2,···,x_n]^T x=[x1,x2,⋅⋅⋅,xn]T,那么向量 x x x的p范数为
∣ ∣ x ∣ ∣ p = ( ∣ x 1 ∣ p + ∣ x 2 ∣ p + ⋅ ⋅ ⋅ + ∣ x n ∣ p ) 1 p ||x||_p=(|x_1|^p+|x_2|^p+···+|x_n|^p)^{\frac{1}{p}} ∣∣x∣∣p=(∣x1∣p+∣x2∣p+⋅⋅⋅+∣xn∣p)p1
L 0 L_0 L0范数:指向量中非零元素的个数
L 1 L_1 L1范数:各个元素的绝对值之和, ∣ ∣ x ∣ ∣ 1 = ∣ x 1 ∣ + ∣ x 2 ∣ + ⋅ ⋅ ⋅ + ∣ x n ∣ ||x||_1=|x_1|+|x_2|+···+|x_n| ∣∣x∣∣1=∣x1∣+∣x2∣+⋅⋅⋅+∣xn∣
L 2 L_2 L2范数:每个元素的平方和再开方, ∣ ∣ x ∣ ∣ 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + ⋅ ⋅ ⋅ + ∣ x n ∣ 2 ) 1 2 = ( ∣ x 1 ∣ 2 + ∣ x 2 ∣ 2 + ⋅ ⋅ ⋅ + ∣ x n ∣ 2 ) ||x||_2=(|x_1|^2+|x_2|^2+···+|x_n|^2)^{\frac{1}{2}}=\sqrt{(|x_1|^2+|x_2|^2+···+|x_n|^2)} ∣∣x∣∣2=(∣x1∣2+∣x2∣2+⋅⋅⋅+∣xn∣2)21=(∣x1∣2+∣x2∣2+⋅⋅⋅+∣xn∣2)
L + ∞ L_{+\infty} L+∞范数:指向量中绝对值最大的元素 , ∣ ∣ x ∣ ∣ ∞ = m a x 1 ≤ i ≤ n ∣ x i ∣ ||x||_\infty=\mathop{max}\limits_{1\leq i\leq n} |x_i| ∣∣x∣∣∞=1≤i≤nmax∣xi∣
L − ∞ L_{-\infty} L−∞范数:指向量中绝对值最小的元素 , ∣ ∣ x ∣ ∣ ∞ = m i n 1 ≤ i ≤ n ∣ x i ∣ ||x||_\infty=\mathop{min}\limits_{1\leq i\leq n} |x_i| ∣∣x∣∣∞=1≤i≤nmin∣xi∣
关于范数在深度学习中的作用参考:深度学习——L0、L1及L2范数
数据集的线性可分性
如果存在某个超平面S能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有 y i = + 1 y_i=+1 yi=+1的实例 i i i,有 w ⋅ x i + b > 0 w·x_i+b>0 w⋅xi+b>0,对所有 y i = − 1 y_i=-1 yi=−1的实例 i i i,有 w ⋅ x i + b < 0 w·x_i+b<0 w⋅xi+b<0,则称数据集T为线性可分数据集;否则,称数据集T线性不可分。
由数据集的线性可分性的定义可得,对于误分类数据 ( x i , y i ) (x_i,y_i) (xi,yi),有当 w ⋅ x i + b > 0 w·x_i+b>0 w⋅xi+b>0时, y i = − 1 y_i=-1 yi=−1;当 w ⋅ x i + b < 0 w·x_i+b<0 w⋅xi+b<0时, y i = + 1 y_i=+1 yi=+1. 即有 − y i ( w ⋅ x i + b ) > 0 -y_i(w·x_i+b)>0 −yi(w⋅xi+b)>0,从而推得 ∣ w ⋅ x 0 + b ∣ = − y i ( w ⋅ x i + b ) |w·x_0+b|=-y_i(w·x_i+b) ∣w⋅x0+b∣=−yi(w⋅xi+b). 因此,误分类点 x i x_i xi到超平面 S S S的距离为:
d = 1 ∣ ∣ w ∣ ∣ ∣ w ⋅ x i + b ∣ = − 1 ∣ ∣ w ∣ ∣ y i ( w ⋅ x i + b ) d=\frac{1}{||w||}|w·x_i+b|=-\frac{1}{||w||}y_i(w·x_i+b) d=∣∣w∣∣1∣w⋅xi+b∣=−∣∣w∣∣1yi(w⋅xi+b)
那么,所有误分类点到超平面 S S S的距离为:
− 1 ∣ ∣ w ∣ ∣ ∑ x i ∈ M y i ( w ⋅ x i + b ) -\frac{1}{||w||}\sum\limits_{x_i\in M}y_i(w·x_i+b) −∣∣w∣∣1xi∈M∑yi(w⋅xi+b)
而 ∣ ∣ w ∣ ∣ 2 = ( ∣ w 1 ∣ 2 + ∣ w 2 ∣ 2 + ⋅ ⋅ ⋅ + ∣ w n ∣ 2 ) ||w||_2=\sqrt{(|w_1|^2+|w_2|^2+···+|w_n|^2)} ∣∣w∣∣2=(∣w1∣2+∣w2∣2+⋅⋅⋅+∣wn∣2),不考虑 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1(为标量??),得到感知机学习的损失函数为:
(B) L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum\limits_{x_i\in M}y_i(w·x_i+b)\tag{B} L(w,b)=−xi∈M∑yi(w⋅xi+b)(B)
算法
感知机学习算法是误分类驱动的,采用随机梯度下降法不断地极小化目标函数(A),每次随机选取一个误分类点使其梯度下降。
原始形式
输入:
训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x N , y N ) } T=\left\{ (x_1,y_1),(x_2,y_2),···,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),⋅⋅⋅,(xN,yN)},其中 x i ∈ R n , y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋅ ⋅ ⋅ , N x_i\in R^n,y_i \in \left\{-1,+1\right\},i=1,2,···,N xi∈Rn,yi∈{−1,+1},i=1,2,⋅⋅⋅,N;
学习率 η ( 0 < η ≤ 1 ) \eta\ (0<\eta \leq1) η (0<η≤1)
输出:
w , b w, b w,b;
感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) f(x)=sign(w·x+b) f(x)=sign(w⋅x+b)
Step1: 选取初值 w 0 , b 0 w_0, b_0 w0,b0
Step2: 在训练集中随机选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
Step3: 如果 y i ( w ⋅ x i + b ) ≤ 0 y_i(w·x_i+b)\leq 0 yi(w⋅xi+b)≤0, 更新 w , b w, b w,b
(1) w ← w + η y i x i w \leftarrow w+\eta y_ix_i\tag{1} w←w+ηyixi(1) (2) b ← b + η y i b \leftarrow b+\eta y_i\tag{2} b←b+ηyi(2)
Step4: 转至Step2,直到训练集中没有误分类点
解析
关于Step3的参数更新的公式:
损失函数见式(B),其梯度由以下两式给出
∇ w L ( w , b ) = − ∑ x i ∈ M y i x i \nabla_wL(w,b)=-\sum\limits_{x_i\in M}y_ix_i ∇wL(w,b)=−xi∈M∑yixi ∇ b L ( w , b ) = − ∑ x i ∈ M y i \nabla_bL(w,b)=-\sum\limits_{x_i\in M} y_i ∇bL(w,b)=−xi∈M∑yi
对 w , b w,b w,b沿梯度方向进行更新,即
w ← w + η y i x i w \leftarrow w+\eta y_ix_i w←w+ηyixi b ← b + η y i b \leftarrow b+\eta y_i b←b+ηyi
其中 η ( 0 < η ≤ 1 ) \eta (0<\eta\leq1) η(0<η≤1)是步长,也称学习率。
梯度
参考文献:方向导数与梯度
函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,它的模为方向导数的最大值。即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
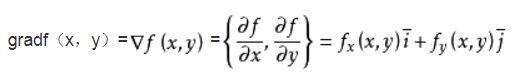
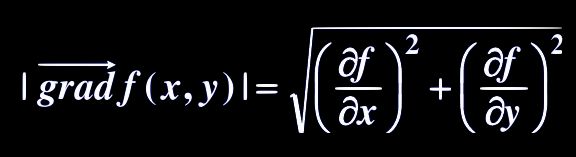
对偶形式
输入:
训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋅ ⋅ ⋅ , ( x N , y N ) } T=\left\{ (x_1,y_1),(x_2,y_2),···,(x_N,y_N)\right\} T={(x1,y1),(x2,y2),⋅⋅⋅,(xN,yN)},其中 x i ∈ R n , y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋅ ⋅ ⋅ , N x_i\in R^n,y_i \in \left\{-1,+1\right\},i=1,2,···,N xi∈Rn,yi∈{−1,+1},i=1,2,⋅⋅⋅,N;
学习率 η ( 0 < η ≤ 1 ) \eta\ (0<\eta \leq1) η (0<η≤1)
输出:
α , b \alpha, b α,b;
感知机模型 f ( x ) = s i g n ( ∑ j = 1 N α j y j x j ⋅ x + b ) f(x)=sign(\sum\limits_{j=1}^N\alpha_jy_jx_j·x+b) f(x)=sign(j=1∑Nαjyjxj⋅x+b),其中 α = ( α 1 , α 2 , ⋅ ⋅ ⋅ , α N ) T \alpha=(\alpha_1,\alpha_2,···,\alpha_N)^T α=(α1,α2,⋅⋅⋅,αN)T
Step1: 设置初值 α ← 0 , b ← 0 \alpha \leftarrow 0, b\leftarrow 0 α←0,b←0
Step2: 在训练集中随机选取数据 ( x i , y i ) (x_i,y_i) (xi,yi)
Step3: 如果 y i ( ∑ j = 1 N α j y j x j ⋅ x i + b ) ≤ 0 y_i(\sum\limits_{j=1}^N\alpha _jy_jx_j·x_i+b)\leq 0 yi(j=1∑Nαjyjxj⋅xi+b)≤0,
(3) α i ← α i + η \alpha _i \leftarrow \alpha _i+\eta\tag{3} αi←αi+η(3) (4) b ← b + η u i b \leftarrow b+\eta u_i\tag{4} b←b+ηui(4)
Step4: 转至Step2,直到训练集中没有误分类点
解析
对偶形式的基本思想:将 w w w和 b b b表示为实例x_i和标记 y i y_i yi的线性组合的形式,通过求解其系数 ( α ) (\alpha) (α)而求得 w w w和 b b b。
在感知机学习算法的原始形式中假设初始值 w 0 , b 0 w_0, b_0 w0,b0均为0;
对误分类点 ( x i , y i ) (x_i,y_i) (xi,yi)通过式(1)(2)逐步更新 w , b w,b w,b,则经过 n n n次更新后, w , b w,b w,b关于 ( x i , y i ) (x_i,y_i) (xi,yi)的增量分别为 α i y i x i \alpha _iy_ix_i αiyixi和 α i y i \alpha _iy_i αiyi,其中 α i = n i η \alpha_i=n_i\eta αi=niη;
则最后学习到的 w w w和 b b b分别表示为:
(5) w = ∑ i = 1 N α i y i x i w=\sum\limits_{i=1}^N\alpha_iy_ix_i\tag{5} w=i=1∑Nαiyixi(5) (6) b = ∑ i = 1 N α i y i b=\sum\limits_{i=1}^N\alpha_iy_i\tag{6} b=i=1∑Nαiyi(6)
其中 α i ≥ 0 , i = 1 , 2 , ⋅ ⋅ ⋅ , N \alpha_i\geq0,i=1,2,···,N αi≥0,i=1,2,⋅⋅⋅,N;当 η = 1 \eta=1 η=1时, α i \alpha_i αi表示第 i i i个实例点由于误分类而进行更新的次数。
将式(5)代入式(*),即将感知机模型化为
(C) f ( x ) = s i g n ( ∑ j = 1 N α j y j x j ⋅ x + b ) f(x)=sign(\sum\limits_{j=1}^N\alpha_jy_jx_j·x+b)\tag{C} f(x)=sign(j=1∑Nαjyjxj⋅x+b)(C)
这样将参数由 w , b w,b w,b变为 α , b \alpha,b α,b,参数更新过程也得到简化,由(1)(2)变为(3)(4);另外,训练实例仅以内积 ( x j ⋅ x i ) (x_j·x_i) (xj⋅xi)的形式存在,可以预先将其计算出来以矩阵的形式存储,这就是Gram矩阵。
G = [ x i ⋅ x j ] N × N G=[x_i·x_j]_{N\times N} G=[xi⋅xj]N×N
参考文献
[1] 李航. 统计学习方法(第2版). 北京:清华大学出版社,2017.