hive详细笔记(八)-Hive之列转行和行转列(附带讲解视频 )
1 行转列
1.1 函数
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。 将某列数据转换成数组
1.1.1 concat字符串的拼接
0: jdbc:hive2://linux01:10000> desc fromatted concat ;
FAILED: SemanticException [Error 10001]: Table not found fromatted
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found fromatted (state=42S02,code=10001)
0: jdbc:hive2://linux01:10000> desc formatted concat ;
FAILED: SemanticException [Error 10001]: Table not found concat
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Table not found concat (state=42S02,code=10001)
0: jdbc:hive2://linux01:10000> desc function concat ;
OK
+----------------------------------------------------+
| tab_name |
+----------------------------------------------------+
| concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data bin1, bin2, ... binN |
+----------------------------------------------------+示例 实现字符串的拼接
0: jdbc:hive2://linux01:10000> select concat("a" , "-->","b","-->","c")
. . . . . . . . . . . . . . .> ;
OK
+------------+
| _c0 |
+------------+
| a-->b-->c |
+------------+
concat的执行时机时行数据 将查询的表中的一行中的多个字段拼接
0: jdbc:hive2://linux01:10000> select concat(ename,":",job,":",sal) from tb_emp;
OK
+--------------------------+
| _c0 |
+--------------------------+
| SMITH:CLERK:800.0 |
| ALLEN:SALESMAN:1600.0 |
| WARD:SALESMAN:1250.0 |
| JONES:MANAGER:2975.0 |
| MARTIN:SALESMAN:1250.0 |
| BLAKE:MANAGER:2850.0 |
| CLARK:MANAGER:2450.0 |
| SCOTT:ANALYST:3000.0 |
| KING:PRESIDENT:5000.0 |
| TURNER:SALESMAN:1500.0 |
| ADAMS:CLERK:1100.0 |
| JAMES:CLERK:950.0 |
| FORD:ANALYST:3000.0 |
| MILLER:CLERK:1300.0 |
| HUGUANYU:HANGGE:18000.0 |
+--------------------------+1.1.2 CONCAT_WS(separator, str1, str2,...)
concat_ws 比 concat 可以自定字段的分隔符
- concat_ws (参数一(分隔符) , str1 , str2....)
- concat_ws (参数一(分隔符) , 数组)
示例
0: jdbc:hive2://linux01:10000> select concat_ws("_" , "tom","cat" ,"jim" ,"jerry") ;
OK
+--------------------+
| _c0 |
+--------------------+
| tom_cat_jim_jerry |
+--------------------+
0: jdbc:hive2://linux01:10000> select concat_ws(":" , ename ,job , sal) from tb_emp ;
FAILED: SemanticException [Error 10016]: Line 1:36 Argument type mismatch 'sal': Argument 4 of function CONCAT_WS must be "string or array", but "double" was found.
Error: Error while compiling statement: FAILED: SemanticException [Error 10016]: Line 1:36 Argument type mismatch 'sal': Argument 4 of function CONCAT_WS must be "string or array", but "double" was found. (state=42000,code=10016) 需要类型转换 将double转换成string 语法
cast(变量 AS 数据类型) 强制类型转换
cast(sal as string)
select concat_ws(":" , ename ,job , cast(sal as string)) from tb_emp ;
OK
+--------------------------+
| _c0 |
+--------------------------+
| SMITH:CLERK:800.0 |
| ALLEN:SALESMAN:1600.0 |
| WARD:SALESMAN:1250.0 |
| JONES:MANAGER:2975.0 |
| MARTIN:SALESMAN:1250.0 |
| BLAKE:MANAGER:2850.0 |
| CLARK:MANAGER:2450.0 |
| SCOTT:ANALYST:3000.0 |
| KING:PRESIDENT:5000.0 |
| TURNER:SALESMAN:1500.0 |
| ADAMS:CLERK:1100.0 |
| JAMES:CLERK:950.0 |
| FORD:ANALYST:3000.0 |
| MILLER:CLERK:1300.0 |
| HUGUANYU:HANGGE:18000.0 |
+--------------------------+1.1.3 COLLECT_SET(col) 将内容收集成set集合
desc function collect_set ;
OK
+----------------------------------------------------+
| tab_name |
+----------------------------------------------------+
| collect_set(x) - Returns a set of objects with duplicate elements eliminated |
+----------------------------------------------------+对表中的某个字段列操作
select deptno from tb_emp ;
OK
+---------+
| deptno |
+---------+
| 20 |
| 30 |
| 30 |
| 20 |
| 30 |
| 30 |
| 10 |
| 20 |
| 10 |
| 30 |
| 20 |
| 30 |
| 20 |
| 10 |
| 50 |
+---------+
select conllect_set(deptno) from tb_emp ;--->去重重复元素的数组
+----------------+
| _c0 |
+----------------+
| [20,30,10,50] |
+----------------+collect_list(col) 不会去重数据
select collect_list(deptno) as deptno_list from tb_emp ;
+-------------------------------------------------+
| deptno_list |
+-------------------------------------------------+
| [20,30,30,20,30,30,10,20,10,30,20,30,20,10,50] |
+-------------------------------------------------+1.2 行转列
结果如下:
射手座,A 娜娜|凤姐
白羊座,A 孙悟空|猪八戒
白羊座,B 宋宋
数据
孙悟空 白羊座 A
娜娜 射手座 A
宋宋 白羊座 B
猪八戒 白羊座 A
凤姐 射手座 A
1.2.1 建表导入数据
create table if not exists tb_star(
name string ,
star string ,
dname string
)
row format delimited fields terminated by "\t" ;
load data local inpath "/hive/data/star.txt" into table tb_star ;
0: jdbc:hive2://linux01:10000> select * from tb_star ;
OK
+---------------+---------------+----------------+
| tb_star.name | tb_star.star | tb_star.dname |
+---------------+---------------+----------------+
| 孙悟空 | 白羊座 | A |
| 娜娜 | 射手座 | A |
| 宋宋 | 白羊座 | B |
| 猪八戒 | 白羊座 | A |
| 凤姐 | 射手座 | A |
+---------------+---------------+----------------+1.2.2 代码实现方式一
1) 先将星座和部门拼接 concat_ws
select
concat_ws("," , star , dname) as star_and_dname ,
name
from
tb_star ;
+-----------------+-------+
| star_and_dname | name |
+-----------------+-------+
| 白羊座,A | 孙悟空 |
| 射手座,A | 娜娜 |
| 白羊座,B | 宋宋 |
| 白羊座,A | 猪八戒 |
| 射手座,A | 凤姐 |
+-----------------+-------+
2) 分组 收集姓名
with t1 as
(select
concat_ws("," , star , dname) as star_and_dname ,
name
from
tb_star)
select
star_and_dname,
collect_set(name)
from
t1
group by star_and_dname ;
+-----------------+----------------+
| star_and_dname | _c1 |
+-----------------+----------------+
| 射手座,A | ["娜娜","凤姐"] |
| 白羊座,A | ["孙悟空","猪八戒"] |
| 白羊座,B | ["宋宋"] |
+-----------------+----------------+
3) 获取结果
select
star_and_dname ,
concat_ws("|" ,name_arr )
from
(select
star_and_dname,
collect_set(name) as name_arr
from
(select
concat_ws("," , star , dname) as star_and_dname ,
name
from
tb_star) t
group by star_and_dname) t2 ;
+-----------------+----------+
| star_and_dname | _c1 |
+-----------------+----------+
| 射手座,A | 娜娜|凤姐 |
| 白羊座,A | 孙悟空|猪八戒 |
| 白羊座,B | 宋宋 |
+-----------------+----------+1.2.3 代码实现方式二
select
concat(star , "," , dname) ,
concat_ws("|" , collect_set(name))
from
tb_star
group by star , dname
;
+--------+----------+
| _c0 | _c1 |
+--------+----------+
| 射手座,A | 娜娜|凤姐 |
| 白羊座,A | 孙悟空|猪八戒 |
| 白羊座,B | 宋宋 |
+--------+----------+2 列转行
2.1 关键函数
- split(str , 分隔符) 返回一个数组
0: jdbc:hive2://linux01:10000> select split("hello,jim,yonggge,tom,cat" , ",") ;
OK
+----------------------------------------+
| _c0 |
+----------------------------------------+
| ["hello","jim","yonggge","tom","cat"] |
+----------------------------------------+- explode() 炸裂函数 将数组中的每个元素显示在每行中
0: jdbc:hive2://linux01:10000> select explode (split("hello,jim,yonggge,tom,cat" , ",")) ;
OK
+----------+
| col |
+----------+
| hello |
| jim |
| yonggge |
| tom |
| cat |
+----------+- lateral view 侧窗口函数
2.2 示例
2.2.1 数据和需求
数据
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
需求 获取如下结构
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难
2.2.2 建表导入数据
create table tb_movie(
name string ,
types string
)
row format delimited fields terminated by "\t" ;
load data local inpath "/hive/data/movie.txt" into table tb_movie ;
+----------------+-----------------+
| tb_movie.name | tb_movie.types |
+----------------+-----------------+
| 《疑犯追踪》 | 悬疑,动作,科幻,剧情 |
| 《Lie to me》 | 悬疑,警匪,动作,心理,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
+----------------+-----------------+2.2.3 实现
1 将类型转换成数组
select
split(types , ",") types_arr
from
tb_movie ;
2 炸裂
select
explode(split(types , ",")) f_type
from
tb_movie ;
+---------+
| f_type |
+---------+
| 悬疑 |
| 动作 |
| 科幻 |
| 剧情 |
| 悬疑 |
| 警匪 |
| 动作 |
| 心理 |
| 剧情 |
| 战争 |
| 动作 |
| 灾难 |
+---------+
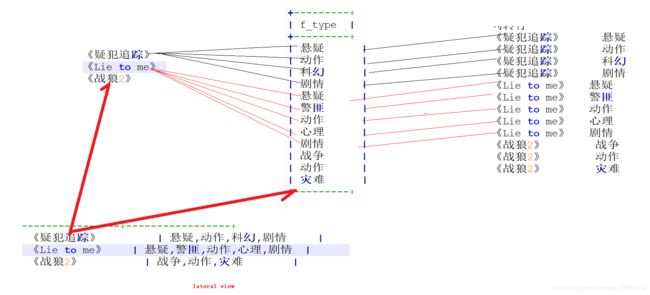
3 使用侧窗口函数拼接
select
name ,
f_type
from
tb_movie
lateral view
explode(split(types ,",")) t as f_type ;
+--------------+---------+
| name | f_type |
+--------------+---------+
| 《疑犯追踪》 | 悬疑 |
| 《疑犯追踪》 | 动作 |
| 《疑犯追踪》 | 科幻 |
| 《疑犯追踪》 | 剧情 |
| 《Lie to me》 | 悬疑 |
| 《Lie to me》 | 警匪 |
| 《Lie to me》 | 动作 |
| 《Lie to me》 | 心理 |
| 《Lie to me》 | 剧情 |
| 《战狼2》 | 战争 |
| 《战狼2》 | 动作 |
| 《战狼2》 | 灾难 |
+--------------+---------+