Python数据分析实战项目-共享单车骑行数据分析
背景介绍
随着我国的经济迅速发展,城市人口急剧增加,随之带来的是一系列的问题,交通拥堵,环境受到破坏,发展公共交通可以完美的解决现在我们面临的这些问题,自行车具有机动灵活、低碳环保的优点,如果自行车可以取代现在的机动车,那么道路就不会那么拥挤,人们的出行效率就会大大提升,汽车废气的排放量也将大大的减少,环境的质量也会提升。同时,为了完美的解决从地铁站到公司、从公交站到家的“最后一公里”路程,共享单车应运而生.
共享单车有效的解决了“走路累,公交挤,开车堵,打车贵”的苦恼。一夜之间,北上广深、甚至部分二线城市,共享单车大街小巷随处可见。继2016年9月26日ofo单车宣布获得滴滴快车数千万美元的战略投资,双方将在共享单车领域展开深度合作之后,摩拜单车也于2017年1月完成D轮2.15亿美元(约合人民币15亿元)的融资,国内共享单车更加火爆,最近一张手机截屏蹿红网络。在这张截图上,24个共享单车应用的图标霸满了整个手机屏幕,真的是“一图说明共享单车的激烈竞争”。而在街头,仿佛一夜之间,共享单车已经到了“泛滥”的地步,各大城市路边排满各种颜色的共享单车。共享经济的不断发展逐渐的改变着人们的日常生活,共享精神也逐渐深入人心。
数据来源(已更新)
链接:https://pan.baidu.com/s/131t5FRozchsOf2PVyWhK8w
提取码:ipdb
复制这段内容后打开百度网盘手机App,操作更方便哦
python源代码
# 1.导包操作:科学计算包numpy,pandas,可视化matplotlib,seaborn
import numpy as np # 导入numpy并重命名为np
import pandas as pd # 导入pandas并重命名为pd
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
from datetime import datetime
import calendar
import matplotlib.pyplot as plt
import seaborn as sn
# weekday方法:日期--》星期值(整数,下标从0开始)
# strptime方法:字符串--》日期
# day_name方法:星期值--》星期(字符串)
# month_name方法:月份值--》月份(字符串)
# month方法:日期--》月份值(整数)(1-12)
# map方法:根据对应字典产生映射
# 2. 数据采集/查看和处理
def collect_and_process_data():
# 2.1 数据读取
bikedata = pd.read_csv('train.csv')
# 2.2 数据查看
print(bikedata.shape) # 查看数据
print(bikedata.head(5)) # 查看数据的前5行
print(bikedata.dtypes) # 查看数据类型
# 2.3数据提取
# 2.3.1提取年月日
# 对datetime这一列应用匿名函数:
# x表示datetime这一列数据
# x.split()以空格符分割,返回字符串列表
# x.split()[0]取出列表的第一个元素
bikedata['date'] = bikedata.datetime.apply(lambda x: x.split()[0]) # 添加一列:date
# 2.3.2提取小时
bikedata['hour'] = bikedata.datetime.apply(lambda x: x.split()[1].split(':')[0])
# 2.3.3 在年月日的基础上提取星期几(格式化字符串)
bikedata['weekday'] = bikedata.date.apply(
lambda dateString: calendar.day_name[datetime.strptime(dateString, '%Y/%m/%d').weekday()])
# 2.3.4 在年月日的基础上提取月份值
bikedata['month'] = bikedata.date.apply(
lambda dateString: calendar.month_name[datetime.strptime(dateString, "%Y/%m/%d").month])
# 2.4 数据转换
# 2.4.1 将season转换为英文季节值
bikedata['season'] = bikedata.season.map({1: 'spring', 2: 'summer', 3: 'fall', 4: 'winter'})
# 2.4.2 将以下变量转化成分类变量
print(bikedata)
varlist = ['hour', 'weekday', 'month', 'season', 'holiday', 'workingday']
for x in varlist:
bikedata[x] = bikedata[x].astype('category') # astype 改变数据类型
print(bikedata.dtypes)
# 2.4.3删除无意义的列
bikedata.drop('datetime', axis=1, inplace=True)
# 2.5数据清洗
# 2.5.1查看数据缺失
print(bikedata.describe())
# 2.5.2查看是否有异常值
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches(12, 12) # 重设大小,单位:英寸
# v垂直 h水平
# 绘制箱型图
sn.boxplot(data=bikedata, y='count', orient='v', ax=axes[0][0])
sn.boxplot(data=bikedata, x='season', y="count", orient='v', ax=axes[0][1])
sn.boxplot(data=bikedata, x='hour', y="count", orient='v', ax=axes[1][0])
sn.boxplot(data=bikedata, x='workingday', y="count", orient='v', ax=axes[1][1])
# 设置横坐标、纵坐标、标题
axes[0][0].set(ylabel="骑行人数", title="骑行人数")
axes[0][1].set(ylabel="骑行人数", xlabel="季节", title="各季节骑行人数")
axes[1][0].set(ylabel="骑行人数", xlabel="时间段", title="各时间段骑行人数")
axes[1][1].set(ylabel="骑行人数", xlabel="是否工作日", title="工作日和非工作日骑行人数")
plt.savefig('collect_and_process_data.png') # 保存图片
plt.show() # 显示图片
# 2.5.3剔除异常数据
print(np.abs(bikedata["count"] - bikedata["count"].mean()))
print(3 * bikedata["count"].std())
print(np.abs(bikedata["count"] - bikedata["count"].mean()) <= (3 * bikedata["count"].std()))
processed_data = bikedata[np.abs(bikedata["count"] - bikedata["count"].mean()) <= (3 * bikedata["count"].std())]
print(processed_data)
processed_data.to_csv('processed_data.csv')
return processed_data
# 3. 数据分析与可视化(不同月份的骑行月份分析)
def Data_Analysis_and_Visualization_month(bikedata):
fig, axes = plt.subplots()
fig.set_size_inches(12, 20)
sortOrder = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October",
"November", "December"]
# 判断每个月份有几条记录,并按由大到小顺序排序
monthAggregated = pd.DataFrame(bikedata.groupby("month")["count"].mean()).reset_index()
# print(monthAggregated)
monthSorted = monthAggregated.sort_values(by="count", ascending=False) # 按月份从小到大排序
# print(monthSorted)
# 绘制柱状图
sn.barplot(data=monthSorted, x="month", y="count", order=sortOrder)
axes.set(xlabel="月份", ylabel="平均骑行人数", title="不同月份的骑行人数")
plt.savefig('result_month.png')
# plt.show()
# 4. 数据分析与可视化(不同时间的骑行时间)
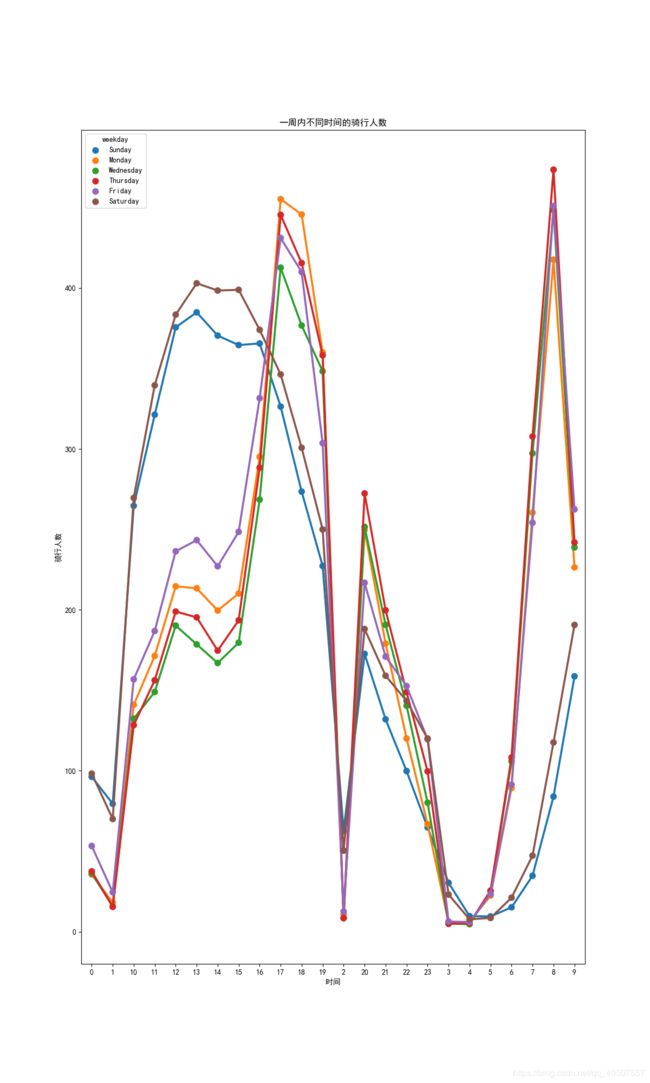
def Data_Analysis_and_Visualization_hour(bikedata):
fig, ax = plt.subplots()
fig.set_size_inches(12, 20)
hueOrder = ['Sunday', 'Monday', 'Wednesday', 'Thursday', 'Friday', 'Saturday']
# 一周内不同时间的骑行人数
hourAggregated = pd.DataFrame(bikedata.groupby(['hour', 'weekday'])['count'].mean()).reset_index()
print(hourAggregated)
# 绘制折线图
sn.pointplot(x=hourAggregated['hour'], y=hourAggregated['count'], hue=hourAggregated['weekday'], hue_order=hueOrder,
data=hourAggregated)
ax.set(xlabel='时间', ylabel='骑行人数', title='一周内不同时间的骑行人数')
plt.savefig('result_hour.png')
plt.show()
# 主函数
def main():
# 数据采集/查看和处理
processed_data = collect_and_process_data()
# 数据分析与可视化:月份
Data_Analysis_and_Visualization_month(processed_data)
# 数据分析与可视化:小时
Data_Analysis_and_Visualization_hour(processed_data)
# 主程序
if __name__ == '__main__':
main()
分析结果
数据查看

数据分析与可视化(骑行月份分析)

数据分析与可视化(骑行时间分析)