数学之路(2)-数据分析-R基础(22)
19)read.table和scan读取文件
read.table比scan更强大,在文件有文件头的情况下,指定header=TRUE可以将文件头做为变量名。
> read.table("h:/my_docs/eqweek.csv",header=TRUE,sep=",")->earthquake
> earthquake DateTime.Latitude.Longitude.Depth.Magnitude.MagType.NbStations.Gap.Distance.RMS.Source.EventID.Version
1 2013-05-20T23:57:12.000+00:00,63.45,-148.291,5.5,1.6,Ml,,,,0.8,ak,ak10720946,1.3691E+12
2 2013-05-20T23:52:59.000+00:00,61.337,-152.069,81.4,2.1,Ml,,,,1.15,ak,ak10720941,1.36909E+12
3 2013-05-20T23:49:15.100+00:00,19.99,-155.426,38.2,2.2,Md,,133,0.1,0.11,hv,hv60501711,1.3691E+12
4 2013-05-20T23:46:36.000+00:00,60.498,-142.974,4.2,2.3,Ml,,,,0.43,ak,ak10720934,1.36909E+12
..........................
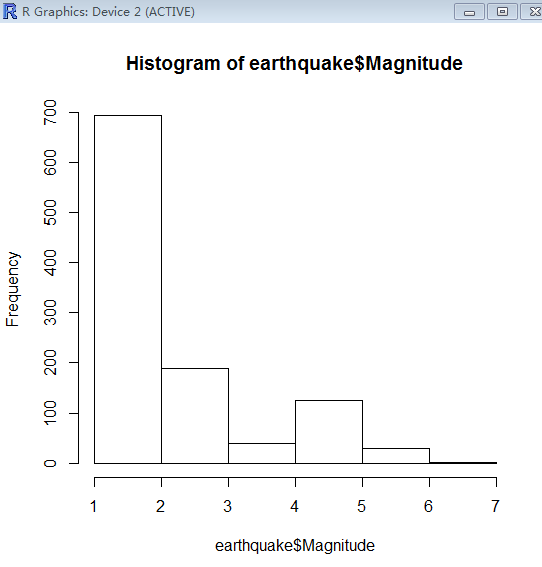
然后我们提取震级数据,绘制直方图,看一下截止2013.5.20为止的最近一周全球地震震级的分布情况,从图中可以看出,大部分的震级都在1-2级以内,地球还是比较安全的~
> hist(earthquake$Magnitude,5)
Scan按更详细的设置读取文件,更加接近于底层。其调用格式为:
scan(file = "", what = double(), nmax = -1, n = -1, sep = "",
quote = if(identical(sep, "\n")) "" else "'\"", dec = ".",
skip = 0, nlines = 0, na.strings = "NA",
flush = FALSE, fill = FALSE, strip.white = FALSE,
quiet = FALSE, blank.lines.skip = TRUE, multi.line = TRUE,
comment.char = "", allowEscapes = FALSE,
fileEncoding = "", encoding = "unknown", text)
我们读取近一个星期的全球地震数据
> scan(file="h:/my_docs/eqweek.csv",skip=1,sep=",",what=list("",0,0,0,mag=0,"",0,0,0,0,"","",0))->eq
Read 1075 records
分5个区间统计分布频率
> table(factor(cut(eq$mag,5)))
(0.995,2.1] (2.1,3.2] (3.2,4.3] (4.3,5.4] (5.4,6.51]
693 200 46 126 10
>
可使用edit()函数编辑数据集后存为另一个数据集
t(eq)->eq2