2014年,Netflix团队创建了一种新的角色,叫作混沌工程师(Chaos Enigneer),并开始向工程社区推广。项目目标、业务场景、人员结构、实施方式的不同导致了对于稳定状态行为的定义不太标准。
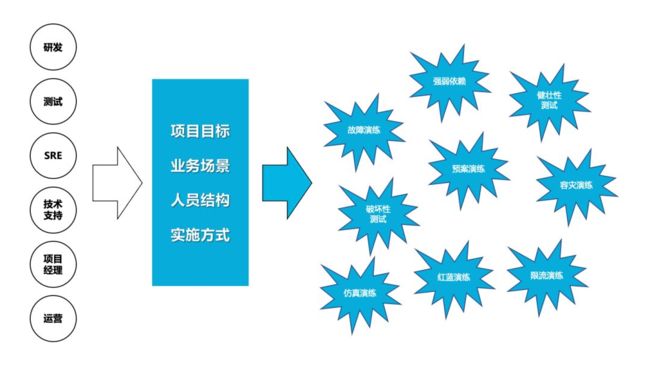
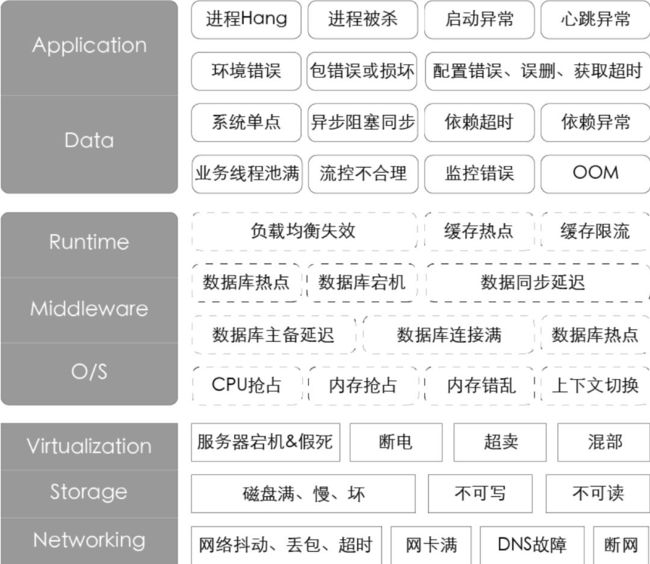
多元化的业务场景、规模化的服务节点及高度复杂的系统架构,每天都会遇到各式各样的故障。这些故障信息就是最真实的混沌工程变量。为了能够更体感、有效率地描述故障,优先分析了P1和P2的故障,提出一些通用的故障场景并按照IaaS层、PaaS层、SaaS层的角度绘制了故障画像。
混沌工程到底是什么?
根据 Netflix 的解释,混沌工程师通过应用一些经验探索的原则,来学习观察系统是如何反应的。这就跟科学家做实验去学习物理定律一样,混沌工程师通过做实验去了解系统。

上图就是混沌工程的典型代表 - 猴子。拜 Netflix 所赐,现在大部分的混沌工程项目都叫做 Monkey,也就是一只讨厌的猴子,在你的系统里面上蹦下窜,不停捣乱,直到搞挂你的系统。
然后,我们需要知道,为什么需要混沌工程。应用混沌工程能提升整个系统的弹性。通过设计并且进行混沌实验,我们可以了解到系统脆弱的一面,在还没出现对用户造成伤害之前,我们就能主动发现这些问题。
混沌工程其实是很重要的,但我之前一直以为混沌工程就是测试,但它们还是有区别的。虽然混沌工程跟传统测试通常都会共用很多测试工具的,譬如都会使用错误注入工具,但混沌工程是通过实践对系统有更新的认知,而传统测试则是使用特定方式对某一块进行特定测试。譬如在传统测试里面,我们可以写一个断言,我们给定特定的条件,产生一个特定的输出,如果不满足断言条件,测试就出错了,这个其实是具有很明确的特性。但混沌工程是试验,而试验会有怎样的新信息生成,我们是不确定的。譬如我们可以进行下面的这些试验:
- 模拟整个 IDC 当掉
- 选择一部分网络连连接注入特定时间的延迟
- 随机让一些函数抛出异常
- 强制 NTP 时间不同步
- 生成 IO 错误
- 榨干 CPU
这些试验到底会有什么样的结果,有些我们可以预料,但有些可能我们就不会预先知道,只有发生了,才会恍然大悟,有一种『喔,这也会出现!』的感叹。
原则
在开始应用混沌工程之前,我们必须确保系统是弹性的,也就是当出现了系统错误我们的整个系统还能正常工作。如果不能确保,我们就需要先考虑提升整个系统的健壮性了,因为混沌工程主要是用来发现系统未知的脆弱一面的,如果我们知道应用混沌工程能导致显而易见的问题,那其实就没必要应用了。
虽然 chaos 有混乱的意思,但混沌工程并不是制造混乱。相反,我们可以认为混沌工程是用经验的方法来定位问题的一门实验学科。譬如,我们可以思考:『如果我们在系统里面注入混乱了,这个系统会怎样?』,或者『我们系统离混乱的边界还有多远?』。所以,为了更好的进行混沌试验,我们需要有一些原则来进行指导。
假定稳定状态
在一个复杂系统里面,我们有特别多的组件,有很多不同的输入输出,我们需要有一个通用的方式来区别系统哪些行为是可以接受的,而哪一些则是不合适的。我们可以认为当系统处于正常操作时候的状态就是稳定状态。
通常我们可以通过自己测试,来确定一个系统的稳定状态,但这个方法当然是比较低效的,另一种更常用的做法就是收集 metric 信息,不光需要系统的 metric,也需要服务自身的 metric,但收集 metric 需要注意实时性的问题,你如果收集一个每月汇总的 metric 信息,其实没啥用,毕竟系统是实时变化的。现在市面上面有很多不错的开源 metric 系统,譬如我们就在用的 Prometheus。
当我们能收集到信息之后,就需要用这些信息去描述一个稳定状态。这个难度比较大,因为不同的业务是不一样的,即使是同一个业务,不同时间也可能变化很大。但也有一些方法,譬如我们可以根据前面一段时间譬如上周的 metric 的曲线得到一个大概合理的稳定状态,也可以自己做很多压力测试,得到相关的数据。
当有了 metric 以及知道稳定状态对应的 metric 是怎样之后,我们就可以通过这些来考虑混沌实验了。思考当我们注入不同的事件到系统中的时候,稳定状态会如何变化,然后我们就会开始做实验来验证这个假设。
变更真实世界事件
在真实的世界中,我们可能遇到各种各样的问题,譬如:
- 硬件故障
- 网络延迟和隔离
- 资源耗尽
- 拜占庭错误
- 下游依赖故障
做混沌试验的时候需要模拟这些故障,来看系统的状态。但从成本上面考虑,我们并不需要模拟所有的故障,仅仅需要考虑那些会比较频繁发生,而且模拟之后会很有效果的。在 TiDB 里面,我们主要就是模拟的网络,文件系统的故障,但现在看起来还是不够,后面会逐渐的添加更多。
在生产中进行试验
要看混沌试验有没有效果,在真实生产环境中进行验证是最好的方法。但我相信大部分的厂商还没这么大的魄力,这方面 Netflix 就做的很猛,他们竟然能够直接停掉 Amazon 上面的一个 Zone。
如果不能再生产环境中试验,一个可选的方法就是做 shadow,也就是通常的录制生产环境的流量,然后在测试中重放。或者模拟生产环境,自己造数据测试。
自动化持续执行
最开始执行混沌试验,我们可能就是人工进行,试验进行的过程中,看 metric,试验结束之后,通过收集的 metric 在对比,看系统的状态。这个过程后面完全可以做成自动化的,也就是定期执行,或者系统发布的时候执行等。
如果能做到自动化执行试验,已经很不错了,但我们可以做的更多,甚至有可能根据系统的状态自动化的生成相关的试验,这个 Netflix 已经做了很多研究,但我们这边还处于初级阶段,没考虑过自动化生成的问题。
最小化影响范围
在进行混沌试验的时候,一定要注意影响的范围,如果没预估好,把整个服务搞挂了,导致所有的用户都没法使用,这个问题还是很严重的。
通常都会使用一种 Canary 的方法,也就是类似 A/B 测试,或者灰度发布这种的,在 Canary 集群这边做很多试验。也就是说,如果真的搞坏了,那也只是一小部分用户被搞坏了,损失会小很多。
在 Canary 里面还有一个好处,因为我们知道整个系统的稳定状态,即使不做混沌测试,也可以观察 Canary 里面的状态是不是跟之前的稳定状态一致的,如果不一致,那也可能有问题。
实践
上面我们说了相关的原则,那么如何开始进行一次混沌试验呢?其实很简单,只要做到如下步骤就可以:
- 选择一个假设
- 选择试验的范围
- 明确需要观察的 metric 指标
- 通知相关的团队
- 执行试验
- 分析结果
- 增大试验的范围
- 自动化
譬如对于 TiDB 来说,譬如我们可以选择验证网络隔离对系统的影响,我们会:
- 假设一台机器的网络隔离对整个系统不会造成影响
- 将一个用户一台 TiKV 进行网络隔离
- 观察 QPS,latency,等指标
- 通知负责这个用户的 OPS 同学
- 断网
- 一段时间之后分析 metric
- 在多个集群测试
- 将这个流程自动化
上面只是一个简单的例子,实际还会复杂很多,但通过这种方式做了操作了很多次之后,大家都会更加熟悉自己的系统。
混沌成熟度模型
这里在简单说说混沌成熟度模型,Netflix 总结了两个维度,一个是复杂度,一个就是接受度。前者表示的是混沌工程能有多复杂,而后者则表示的是混沌工程被团队的接受程度。
复杂度分为几个阶段:
-
初级
- 试验没有在生产中进行
- 进程被收工管理
- 结果只反映系统 metric,没有业务的
- 只有简单的事件进行试验
-
简单
- 试验可以在类生产环境中进行
- 能自动启动执行,但需要人工监控和终止
- 结果能反应一些聚合的业务 metric
- 一些扩展的事件譬如网络延迟可以进行试验
- 结果可以手工汇总和聚合
- 试验是预先定义好的
- 有一些工具能进行历史对照
-
复杂
- 试验直接在生产环境中进行
- 启动,执行,结果分析,终止都是自动完成
- 试验框架集成在持续发布
- 业务 metrics 会在实验组和控制组进行比较
- 一些组合错误或者服务级别影响的事件可以进行试验
- 结果一直可以追踪
- 有工具可以更好的交互式的对比试验和控制组
-
高级
- 试验在每个开发步骤和任意环境都进行
- 设计,执行和提前终止这些全部都是自动化的
- 框架跟 A/B 或者其他试验系统整合
- 一个事件譬如更改使用模式和返回值或者状态变更开始进行试验
- 试验包括动态作用域和影响,可以找到突变点
- 通过试验结果能保护资产流失
- 容量预测可以通过试验分析提前得出
- 试验结果可以区分不同服务的临界状态
而接受度也有几个阶段:
-
在暗处
- 相关项目不被批准
- 很少系统被覆盖
- 很少或者没有团队有意识
- 早期接受者不定期的进行试验
-
有投入
- 试验被被官方批准
- 部分资源被用于实践
- 多个团队有兴趣并投入
- 少部分关键服务不定期进行试验
-
接受
- 有专门的 team 进行混沌工程
- 应急响应被集成到框架,从而可以创建回归试验
- 多数关键系统定期进行混沌试验
- 一些试验验证会在应急响应或者游戏时间被临时执行
-
文化
- 所有关键服务都有频繁的混沌试验
- 大多数非关键服务定期进行
- 混沌试验已经是工程师的日常工作
- 默认所有系统组件都必须参与,如果不想进行,需要有正当的理由
混沌工程是不是与你有关?
Netflix工程师创建了Chaos Monkey,使用该工具可以在整个系统中在随机位置引发故障。正如GitHub上的工具维护者所说,“Chaos Monkey会随机终止在生产环境中运行的虚拟机实例和容器。”通过Chaos Monkey,工程师可以快速了解他们正在构建的服务是否健壮,是否可以弹性扩容,是否可以处理计划外的故障。
2012年,Netflix开源了Chaos Monkey。今天,许多公司(包括谷歌,亚马逊,IBM,耐克等),都采用某种形式的混沌工程来提高现代架构的可靠性。 Netflix甚至将其混沌工程工具集扩展到包括整个“Simian Army(中文可以译为猿军)”,用它攻击自己的系统。
混沌工程属于一门新兴的技术学科,行业认知和实践积累比较少,大多数IT团队对它的理解还没有上升到一个领域概念。阿里电商域在2010年左右开始尝试故障注入测试的工作,希望解决微服务架构带来的强弱依赖问题。
混沌工程,是一种提高技术架构弹性能力的复杂技术手段。Chaos工程经过实验可以确保系统的可用性。混沌工程旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。
它,被描述为“在分布式系统上进行实验的学科,目的是建立对系统承受生产环境中湍流条件能力的信心。”。
Chaos Engineering is the discipline of experimenting on a systemin order to build confidence in the system’s capabilityto withstand turbulent conditions in production.
它也可以视为流感疫苗,故意将有害物质注入体内以防止未来疾病,这似乎很疯狂,但这种方法也适用于分布式云系统。混沌工程会将故障注入系统以测试系统对其的响应。这使公司能够为宕机做准备,并在宕机发生之前将其影响降至最低。
如何知道系统是否处于稳定状态呢?通常,团队可以通过单元测试、集成测试和性能测试等手段进行验证。但是,无论这些测试写的多好,我们认为都远远不够,因为错误可以在任何时间发生,尤其是对分布式系统而言,此时就需要引入混沌工程(Chaos Engineering)。
故障演练:目标是沉淀通用的故障模式,以可控成本在线上重放,以持续性的演练和回归方式运营来暴露问题,不断推动系统、工具、流程、人员能力的不断前进。
Chaos Engineering is a helpful tool in understanding your system’s unknowns, but it is not the means to an end for achieving resilience. Instead, it helps to instill higher confidence in the ability to cope and be resilient in the face of inevitable failures.
混沌工程、故障注入和故障测试在关注点和工具中都有很大的重叠。
混沌工程和其他方法之间的主要区别在于,混沌工程是一种生成新信息的实践,而故障注入是测试一种情况的一种特定方法。当想要探索复杂系统可能出现的不良行为时,注入通信延迟和错误等失败是一种很好的方法。但是我们也想探索诸如流量激增,激烈竞争,拜占庭式失败,以及消息的计划外或不常见的组合。如果一个面向消费者的网站突然因为流量激增而导致更多收入,我们很难称之为错误或失败,但我们仍然对探索系统的影响非常感兴趣。同样,故障测试以某种预想的方式破坏系统,但没有探索更多可能发生的奇怪场景,那么不可预测的事情就可能发生。
混沌工程以实验发现系统性弱点。这些实验通常遵循四个步骤:
1.定义并测量系统的“稳定状态”。首先精确定义指标,表明您的系统按照应有的方式运行。 Netflix使用客户点击视频流设备上播放按钮的速率作为指标,称为“每秒流量”。请注意,这更像是商业指标而非技术指标;事实上,在混沌工程中,业务指标通常比技术指标更有用,因为它们更适合衡量用户体验或运营。
2.创建假设。与任何实验一样,您需要一个假设来进行测试。因为你试图破坏系统正常运行时的稳定状态,你的假设将是这样的,“当我们做X时,这个系统的稳定状态应该没有变化。”为什么用这种方式表达?如果你的期望是你的动作会破坏系统的稳定状态,那么你会做的第一件事会是修复问题。混沌工程应该包括真正的实验,涉及真正的未知数。
3.模拟现实世界中可能发生的事情,目前有如下混沌工程实践方法:模拟数据中心的故障、强制系统时钟不同步、在驱动程序代码中模拟I/O异常、模拟服务之间的延迟、随机引发函数抛异常。通常,您希望模拟可能导致系统不可用或导致其性能降低的场景。首先考虑可能出现什么问题,然后进行模拟。一定要优先考虑潜在的错误。 “当你拥有非常复杂的系统时,很容易引起出乎意料的下游效应,这是混沌工程寻找的结果之一,”“因此,系统越复杂,越重要,它就越有可能成为混沌工程的候选对象。”
4.证明或反驳你的假设。将稳态指标与干扰注入系统后收集的指标进行比较。如果您发现测量结果存在差异,那么您的混沌工程实验已经成功 - 您现在可以继续加固系统,以便现实世界中的类似事件不会导致大问题。或者,如果您发现稳定状态可以保持,那么你对该系统的稳定性大可放心。
各式各样的故障。这些故障信息就是最真实的混沌工程变量。
如果你是一名系统架构师、测试人员、SRE 人员,那你需要关注混沌工程。
那么,企业如何确定自己是否适合混沌工程?满足一下部分特征的企业,都适合实施混沌工程:
对于资损或 SLA 有极高要求的行业(金融、电商、医疗、游戏、公共等)
有较大的系统改造(比如:系统重构、微服务化、容器化、迁云)
业务发展快,稳定性积淀少
人员流动快,或 SRE 团队规模较小
对于使用混沌工程的团队,我建议:
要先从文化上让团队认可实施混沌工程的必要性和方法论。
重点关注实验方案的评估,明确定义系统稳态和终止条件。
尝试通过一些简单的场景开始尝试,增加大家对系统和过程的信心。
与其他团队进行合作,通过混沌工程配合其他稳定性手段,达成整体目标(如:监控发现率、故障改进覆盖率、系统自愈有效性等)。
下面我要说的很重要。
在使用混沌工程之前,我们需要准备三点:
思想上要准备好。要意识到系统故障是可以通过周期性的引入一些实验变量来提前暴露和解决的。不论是否实施混沌工程,系统的隐患或 Bug 都客观存在。
系统稳态和实验方案的仔细评估。对于实验方案进行推演,如果已经可以预想到一些问题,那么修正后再进行新的实验。
提升系统的可观测性。对于系统稳态,要有配套的监控或观测工具,否则会影响混沌工程的实施效果。
你知道的,实践出真知。
作为第一批吃螃蟹的,我们也做了将近十年了,阿里在故障模拟、爆炸半径的控制、产品化方面出了一些成绩。业务方基本可以做到很低成本使用我们的产品,DevOps 同学基本已经可以实现自助演练。
从 2016 年到现在,看到大家对领域的认可度逐年变高,演练覆盖的应用规模和发现问题的数量已经翻了几倍,帮助业务方识别了很多潜在故障和改进点,很多高速发展的领域,比如新零售,也是通过实施混沌工程来快速的落地和改进稳定性,我还挺高兴的。
虽然混沌工程在行业内没有一个比较广的认知,但除去 Netflix 和阿里之外,国内外也有不少公司在做这个。
比如,国外有 Gremlin、ChaosIQ 这样专门实施 Resilience as a Service 的商业公司。像一些中、大型公司也都有实施混沌工程团队,比如 Linkedin、Uber、Google 等等。
混沌工程原则 (PRINCIPLES OF CHAOS ENGINEERING)
http://principlesofchaos.org/
混沌工程是在分布式系统上进行实验的学科, 目的是建立对系统抵御生产环境中失控条件的能力以及信心。
大规模分布式软件系统的发展正在改变软件工程。作为一个行业,我们很快采用了提高开发灵活性和部署速度的实践。紧随着这些优点的一个迫切问题是:我们对投入生产的复杂系统有多少信心?
即使分布式系统中的所有单个服务都正常运行, 这些服务之间的交互也会导致不可预知的结果。 这些不可预知的结果, 由影响生产环境的罕见且破坏性的事件复合而成,令这些分布式系统存在内在的混沌。
我们需要在异常行为出现之前,在整个系统内找出这些弱点。这些弱点包括以下形式:
- 当服务不可用时的不正确回滚设置;
- 不当的超时设置导致的重试风暴;
- 由于下游依赖的流量过载导致的服务中断;
- 单点故障时的级联失败等。
我们必须主动的发现这些重要的弱点,在这些弱点通过生产环境暴露给我们的用户之前。我们需要一种方法来管理这些系统固有的混沌, 通过增加的灵活性和速率以提升我们对生产环境部署的信心, 尽管系统的复杂性是由这些部署所导致的。
我们采用基于经验和系统的方法解决了分布式系统在规模增长时引发的问题, 并以此建立对系统抵御这些事件的能力和信心。通过在受控实验中观察分布式系统的行为来了解它的特性,我们称之为混沌工程。
混沌工程实践
为了具体地解决分布式系统在规模上的不确定性,可以把混沌工程看作是为了揭示系统弱点而进行的实验。这些实验遵循四个步骤:
- 首先,用系统在正常行为下的一些可测量的输出来定义“稳定状态”。
- 其次,假设这个在控制组和实验组都会继续保持稳定状态。
- 然后,在实验组中引入反映真实世界事件的变量,如服务器崩溃、硬盘故障、网络连接断开等。
- 最后,通过控制组和实验组之间的状态差异来反驳稳定状态的假说。
破坏稳态的难度越大,我们对系统行为的信心就越强。如果发现了一个弱点,那么我们就有了一个改进目标。避免在系统规模化之后被放大。
高级原则
以下原则描述了应用混沌工程的理想方式,这些原则基于上述实验过程。对这些原则的匹配程度能够增强我们在大规模分布式系统的信心。
建立一个围绕稳定状态行为的假说
要关注系统的可测量输出, 而不是系统的属性。对这些输出在短时间内的度量构成了系统稳定状态的一个代理。 整个系统的吞吐量、错误率、延迟百分点等都可能是表示稳态行为的指标。 通过在实验中的系统性行为模式上的关注, 混沌工程验证了系统是否正常工作, 而不是试图验证它是如何工作的。
多样化真实世界的事件
混沌变量反映了现实世界中的事件。 我们可以通过潜在影响或估计频率排定这些事件的优先级。考虑与硬件故障类似的事件, 如服务器宕机、软件故障 (如错误响应) 和非故障事件 (如流量激增或伸缩事件)。 任何能够破坏稳态的事件都是混沌实验中的一个潜在变量。
在生产环境中运行实验
系统的行为会依据环境和流量模式都会有所不同。 由于资源使用率变化的随时可能发生, 因此通过采集实际流量是捕获请求路径的唯一可靠方法。 为了保证系统执行方式的真实性与当前部署系统的相关性, 混沌工程强烈推荐直接采用生产环境流量进行实验。
持续自动化运行实验
手动运行实验是劳动密集型的, 最终是不可持续的。所以我们要把实验自动化并持续运行,混沌工程要在系统中构建自动化的编排和分析。
最小化爆炸半径
在生产中进行试验可能会造成不必要的客户投诉。虽然对一些短期负面影响必须有一个补偿, 但混沌工程师的责任和义务是确保这些后续影响最小化且被考虑到。
混沌工程是一个强大的实践, 它已经在世界上一些规模最大的业务系统上改变了软件是如何设计和工程化的。 相较于其他方法解决了速度和灵活性, 混沌工程专门处理这些分布式系统中的系统不确定性。 混沌工程的原则为我们大规模的创新和给予客户他们应得的高质量的体验提供了信心。
在生产中进行试验可能会造成不必要的客户投诉,但混沌工程师的责任和义务是确保这些后续影响最小化且被考虑到。对于实验方案和目标进行充分的讨论是减少用户影响的最重要的手段。但是从实际的实施角度看,最好还是通过一些技术手段去最小化影响。Chaos Engineering和Fault Injection Test的核心区别在于:是否可以进一步减小故障的影响,比如微服务级别、请求级别甚至是用户级别。在MonkeyKing演进的中期阶段,已经可以实现请求级别的微服务故障注入。虽然那个时候演练实施的主要位置在测试环境,但初衷也是为了减少因为注入故障而导致的环境不稳定问题。除了故障注入,流量路由和数据隔离技术也是减少业务影响的有效手段。

chaos-engineering 的一些开源工具
开源工具:
kube-monkey、PowerfulSeal、ChaosIQ,提供了一些容器层面的故障注入能力。详细可以看:https://github.com/dastergon/awesome-chaos-engineering
近期阿里会开源一款混沌工程测试工具 ChaosBlade,提供基础资源、应用服务、容器等多维度的故障模拟能力。
商业化工具:
Gremlin 提供一款商用的故障注入平台,部分功能免费,目前在公测中。
阿里云 - 应用高可用服务(AHAS):AHAS 供了基于混沌工程原则的完整的实现,除了提供常见的故障注入能力,默认也打通了一些常见的云服务,提升系统的可观测性和自动化能力。目前免费公测中(支持非阿里云机器公网使用)。
随着企业云化,一定会有越来越多的公司开始关注和实施混沌工程。我希望可以有更多的公司分享思考和实践,并结合领域场景产出一些最佳的实践。
居安思危,思则有备,有备无患。这是《左传·襄公十一年》说的。
此前,有人认为,混沌工程是一种在故障发生之前发现故障的技术,但也是一种心态。
我觉得这句话还是有道理的。混沌工程是一种验证系统对非预期情况防御有效性的实验思想,任何依照”混沌工程原则”进行的探索,都是有效实践。
系统架构可能会很复杂,比如采用了微服务、Docker、K8s,甚至函数计算类似的技术,需要实验项目也涉及很多门类。为了更有效地实施混沌工程,就需要借助一些场景丰富、操作简便、模型标准的工具或技术了。
混沌工程技术会随着其他技术发展而演进,混沌工程会与融入到每个领域的最佳实践中。
今年开始,我开始在一些场合将自己称呼为” 混沌工程布道师”。
布道师,听起来好像有点“忽悠”。
不过,你知道皮埃罗·斯加鲁菲(PieroScaruffi)吗?这位全球人工智能及认知科学专家,被誉为永远站在时代前面的硅谷精神布道者,我很敬佩他。推动技术传播,推动技术落地,推动行业变革,这就是布道者的意义之所在。
Chaos Monkey - A resiliency tool that helps applications tolerate random instance failures.
The Simian Army - A suite of tools for keeping your cloud operating in top form.
orchestrator - MySQL replication topology management and HA.
kube-monkey - An implementation of Netflix's Chaos Monkey for Kubernetes clusters.
Gremlin Inc. - Failure as a Service.
Pumba - Chaos testing and network emulation for Docker containers (and clusters).
Chaos Toolkit - A chaos engineering toolkit to help you build confidence in your software system.
ChaoSlingr - Introducing Security Chaos Engineering. ChaoSlingr focuses primarily on the experimentation on AWS Infrastructure to proactively instrument system security failure through experimentation.
PowerfulSeal - Adds chaos to your Kubernetes clusters, so that you can detect problems in your systems as early as possible. It kills targeted pods and takes VMs up and down.
drax - DC/OS Resilience Automated Xenodiagnosis tool. It helps to test DC/OS deployments by applying a Chaos Monkey-inspired, proactive and invasive testing approach.
Wiremock - API mocking (Service Virtualization) which enables modeling real world faults and delays
MockLab - API mocking (Service Virtualization) as a service which enables modeling real world faults and delays.
Pod-Reaper - A rules based pod killing container. Pod-Reaper was designed to kill pods that meet specific conditions that can be used for Chaos testing in Kubernetes.
Muxy - A chaos testing tool for simulating a real-world distributed system failures.
Toxiproxy - A TCP proxy to simulate network and system conditions for chaos and resiliency testing.
Blockade - Docker-based utility for testing network failures and partitions in distributed applications.
chaos-lambda - Randomly terminate ASG instances during business hours.
Namazu - Programmable fuzzy scheduler for testing distributed systems.
Chaos Monkey for Spring Boot - Injects latencies, exceptions, and terminations into Spring Boot applications
Byte-Monkey - Bytecode-level fault injection for the JVM. It works by instrumenting application code on the fly to deliberately introduce faults like exceptions and latency.
GomJabbar - ChaosMonkey for your private cloud
阿里开源混沌工程工具 ChaosBlade
https://github.com/chaosblade-io/chaosblade

ChaosBlade: 一个简单易用且功能强大的混沌实验实施工具
项目介绍
ChaosBlade 是阿里巴巴开源的一款遵循混沌工程原理和混沌实验模型的实验注入工具,帮助企业提升分布式系统的容错能力,并且在企业上云或往云原生系统迁移过程中业务连续性保障。
Chaosblade 是内部 MonkeyKing 对外开源的项目,其建立在阿里巴巴近十年故障测试和演练实践基础上,结合了集团各业务的最佳创意和实践。
ChaosBlade 不仅使用简单,而且支持丰富的实验场景,场景包括:
- 基础资源:比如 CPU、内存、网络、磁盘、进程等实验场景;
- Java 应用:比如数据库、缓存、消息、JVM 本身、微服务等,还可以指定任意类方法注入各种复杂的实验场景;
- C++ 应用:比如指定任意方法或某行代码注入延迟、变量和返回值篡改等实验场景;
- Docker 容器:比如杀容器、容器内 CPU、内存、网络、磁盘、进程等实验场景;
- 云原生平台:比如 Kubernetes 平台节点上 CPU、内存、网络、磁盘、进程实验场景,Pod 网络和 Pod 本身实验场景如杀 Pod,容器的实验场景如上述的 Docker 容器实验场景;
将场景按领域实现封装成一个个单独的项目,不仅可以使领域内场景标准化实现,而且非常方便场景水平和垂直扩展,通过遵循混沌实验模型,实现 chaosblade cli 统一调用。目前包含的项目如下:
- chaosblade:混沌实验管理工具,包含创建实验、销毁实验、查询实验、实验环境准备、实验环境撤销等命令,是混沌实验的执行工具,执行方式包含 CLI 和 HTTP 两种。提供完善的命令、实验场景、场景参数说明,操作简洁清晰。
- chaosblade-spec-go: 混沌实验模型 Golang 语言定义,便于使用 Golang 语言实现的场景都基于此规范便捷实现。
- chaosblade-exec-os: 基础资源实验场景实现。
- chaosblade-exec-docker: Docker 容器实验场景实现,通过调用 Docker API 标准化实现。
- chaosblade-operator: Kubernetes 平台实验场景实现,将混沌实验通过 Kubernetes 标准的 CRD 方式定义,很方便的使用 Kubernetes 资源操作的方式来创建、更新、删除实验场景,包括使用 kubectl、client-go 等方式执行,而且还可以使用上述的 chaosblade cli 工具执行。
- chaosblade-exec-jvm: Java 应用实验场景实现,使用 Java Agent 技术动态挂载,无需任何接入,零成本使用,而且支持卸载,完全回收 Agent 创建的各种资源。
- chaosblade-exec-cplus: C++ 应用实验场景实现,使用 GDB 技术实现方法、代码行级别的实验场景注入。
使用文档
你可以从 Releases 地址下载最新的 chaosblade 工具包,解压即用。如果想注入 Kubernetes 相关故障场景,需要安装 chaosblade-operator,详细的中文使用文档请查看 chaosblade-help-zh-cn。
chaosblade 支持 CLI 和 HTTP 两种调用方式,支持的命令如下:
- prepare:简写 p,混沌实验前的准备,比如演练 Java 应用,则需要挂载 java agent。例如要演练的应用名是 business,则在目标主机上执行
blade p jvm --process business。如果挂载成功,返回挂载的 uid,用于状态查询或者撤销挂载。 - revoke:简写 r,撤销之前混沌实验准备,比如卸载 java agent。命令是
blade revoke UID - create: 简写是 c,创建一个混沌演练实验,指执行故障注入。命令是
blade create [TARGET] [ACTION] [FLAGS],比如实施一次 Dubbo consumer 调用 xxx.xxx.Service 接口延迟 3s,则执行的命令为blade create dubbo delay --consumer --time 3000 --service xxx.xxx.Service,如果注入成功,则返回实验的 uid,用于状态查询和销毁此实验使用。 - destroy:简写是 d,销毁之前的混沌实验,比如销毁上面提到的 Dubbo 延迟实验,命令是
blade destroy UID - status:简写 s,查询准备阶段或者实验的状态,命令是
blade status UID或者blade status --type create - server:启动 web server,暴露 HTTP 服务,可以通过 HTTP 请求来调用 chaosblade。例如在目标机器xxxx上执行:
blade server start -p 9526,执行 CPU 满载实验:curl "http:/xxxx:9526/chaosblade?cmd=create%20cpu%20fullload"
以上命令帮助均可使用 blade help [COMMAND] 或者 blade [COMMAND] -h 查看,也可查看新手指南,或者上述中文使用文档,快速上手使用。
快速体验
如果想不下载 chaosblade 工具包,快速体验 chaosblade,可以拉取 docker 镜像并运行,在容器内体验。
操作步骤如下:
下载镜像:
docker pull chaosbladeio/chaosblade-demo
启动镜像:
docker run -it --privileged chaosbladeio/chaosblade-demo
进入镜像之后,可阅读 README.txt 文件实施混沌实验,Enjoy it。
面向云原生
chaosblade-operator 项目是针对云原生平台所实现的混沌实验注入工具,遵循混沌实验模型规范化实验场景,把实验定义为 Kubernetes CRD 资源,将实验模型映射为 Kubernetes 资源属性,很友好的将混沌实验模型与 Kubernetes 声明式设计结合在一起,依靠混沌实验模型便捷开发场景的同时,又可以很好的结合 Kubernetes 设计理念,通过 kubectl 或者编写代码直接调用 Kubernetes API 来创建、更新、删除混沌实验,而且资源状态可以非常清晰的表示实验的执行状态,标准化实现 Kubernetes 故障注入。除了使用上述方式执行实验外,还可以使用 chaosblade cli 方式非常方便的执行 kubernetes 实验场景,查询实验状态等。具体请阅读:云原生下的混沌工程实践
编译
此项目采用 golang 语言编写,所以需要先安装最新的 golang 版本,最低支持的版本是 1.11。Clone 工程后进入项目目录执行以下命令进行编译:
make
如果在 mac 系统上,编译当前系统的版本,请执行:
make build_darwin
如果想在 mac 系统上,编译 linux 系统版本,请执行:
make build_linux
也可以选择性编译,比如只需要编译 cli、os 场景,则执行:
make build_with cli os
# 如果是 mac 系统,执行
make build_with cli os_darwin
# 如果是 mac 系统,想选择性的编译 linux 版本的 cli,os,则执行:
ARGS="cli os" make build_with_linux
缺陷&建议
欢迎提交缺陷、问题、建议和新功能,所有项目(包含其他子项目)的问题都可以提交到Github Issues
你也可以通过以下方式联系我们:
- 钉钉群(推荐):23177705
- Gitter room: https://gitter.im/chaosblade-io/community
- 邮箱:[email protected]
- Twitter: chaosblade.io
参与贡献
我们非常欢迎每个 Issue 和 PR,即使一个标点符号,如何参加贡献请阅读 CONTRIBUTING 文档,或者通过上述的方式联系我们。
企业登记
我们开源此项目的初衷是降低混沌工程在企业中落地的门槛,所以非常看重该项目在企业的使用情况,欢迎大家在此 ISSUE 中登记,登记后会被邀请加入企业邮件组,探讨混沌工程在企业落地中遇到的问题和分享落地经验。
未来规划
- 增强云原生领域场景
- Golang 应用混沌实验场景
- NodeJS 应用混沌实验场景
- 故障演练控制台
- 完善 ChaosBlade 各项目的开发文档
- 完善 chaosblade 工具的英文文档
License
Chaosblade 遵循 Apache 2.0 许可证,详细内容请阅读 LICENSE
参考资料
https://github.com/chaosblade-io/chaosblade
https://www.sohu.com/a/301663472_355140
https://www.jianshu.com/p/4bd4f88e24e4
https://blog.csdn.net/b0Q8cpra539haFS7/article/details/86698060
https://zhuanlan.zhihu.com/p/90294032
https://www.infoq.cn/article/EEKM947YbboGtD_zQuLw
https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice/
https://www.oschina.net/news/105679/alibaba-opensource-chaosblade
https://github.com/dastergon/awesome-chaos-engineering
Kotlin开发者社区

专注分享 Java、 Kotlin、Spring/Spring Boot、MySQL、redis、neo4j、NoSQL、Android、JavaScript、React、Node、函数式编程、编程思想、"高可用,高性能,高实时"大型分布式系统架构设计主题。
High availability, high performance, high real-time large-scale distributed system architecture design。
分布式框架:Zookeeper、分布式中间件框架等
分布式存储:GridFS、FastDFS、TFS、MemCache、redis等
分布式数据库:Cobar、tddl、Amoeba、Mycat
云计算、大数据、AI算法
虚拟化、云原生技术
分布式计算框架:MapReduce、Hadoop、Storm、Flink等
分布式通信机制:Dubbo、RPC调用、共享远程数据、消息队列等
消息队列MQ:Kafka、MetaQ,RocketMQ
怎样打造高可用系统:基于硬件、软件中间件、系统架构等一些典型方案的实现:HAProxy、基于Corosync+Pacemaker的高可用集群套件中间件系统
Mycat架构分布式演进
大数据Join背后的难题:数据、网络、内存和计算能力的矛盾和调和
Java分布式系统中的高性能难题:AIO,NIO,Netty还是自己开发框架?
高性能事件派发机制:线程池模型、Disruptor模型等等。。。
合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。不积跬步,无以至千里;不积小流,无以成江河。