函数
内置函数在线程间共享,每个内置函数的调用使用一个独立的实例进行处理
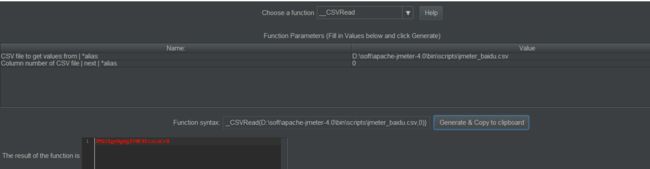
__CSVRead
CSV file to get values from | *alias 指${__CSVRead(,)}中()内的第一个参数,指定具体csv文件的路径
CSV文件列号| next| *alias 指${__CSVRead(,)}中()内的第二个参数,调用csv文件中的第几列参数,第一列为0,第二列为1,依此类推
Jmeter执行的时候,如果线程Number of threads=1读取第一行的数字,Number of threads不等于1,顺序读取,如果线程组多于文件中的行数,则循环读取 (与Loop Count数没有关系)
生成函数操作参见下图:
jmx中的引用参见下图:
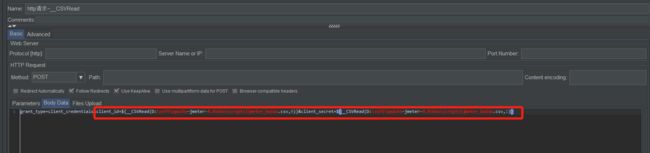
直接在需要变量的地方将函数赋值过去即可
__BeanShell(bean shell)
使用beanshell脚本进行类java的数据处理后,通过vars在jmx中进行传递
定时器:BeanShell Timer
前置处理器:BeanShell PreProcessor : 数据预处理(从jmeter中读取数据data1,data2,经过beanshell转换,在通过其他变量data3输出到jmeter中)
采样器:BeanShell Sampler ,相当于执行类似java类测试,response结果为bean shell中return的结果
后置处理器:BeanShell PostProcessor
断言:BeanShell断言
监听器:BeanShell Listener
以BeanShell Sampler为例进行描述
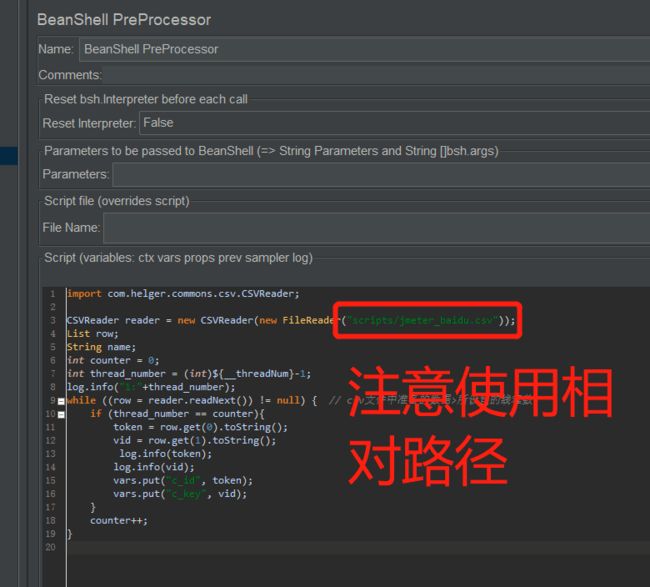
使用java的CSVReader读取csv文件,
int thread_number = (int)${__threadNum}-1; 通过内置的${__threadNum}获取线程组的线程数
通过vars.put(key,value) 将value通过key存入jmeter中,通过vars.get(key)拿到数据返回给jmeter
示例代码如下:
import com.helger.commons.csv.CSVReader;
CSVReader reader = new CSVReader(new FileReader("scripts/test.csv"));
List row;
String name;
int counter = 0;
int thread_number = (int)${__threadNum}-1;
log.info("1:"+thread_number);
while ((row = reader.readNext()) != null) { //要求设置的线程数要小于准备的测试数据
if (thread_number == counter){
c_id = row.get(1).toString();
vars.put("c_id", c_id);
}
counter++;
}
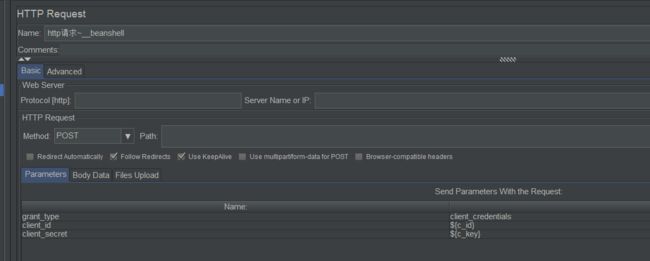
注意:beanshell中读csv文件要使用相对路径(${JMETER_HOME}/bin目录下的路径),绝对路径会出现问题;vars.put中涉及的key不需要之前就通过User Defined Variable先进行定义,只是为了方便监听各类结果才预先定义的(添加Debug PostProcessor),图示如下:
Bean Shell常用内置变量
JMeter在它的BeanShell中内置了变量,用户可以通过这些变量与JMeter进行交互,其中主要的变量及其使用方法如下:
log:用来记录日志文件,写入到jmeber.log文件,使用方法:log.info(“This is log info!”);
ctx(JmeterContext)通过它来访问context,具体参考:org.apache.jmeter.threads.JMeterContext。
vars - (JMeterVariables):操作jmeter变量,提供读取/写入访问变量的方法。这个变量实际引用了JMeter线程中的局部变量容器(本质上是Map),它是测试用例与BeanShell交互的桥梁,常用方法:
a) vars.get(String key):从jmeter中获得变量值
b) vars.put(String key,String value):数据存到jmeter变量中
c) vars.putObject("OBJ1",new Object());
更多方法可参考:org.apache.jmeter.threads.JMeterVariables
props - (JMeterProperties - classJava.util.Properties):操作jmeter属性,该变量引用了JMeter的配置信息,可获取Jmeter属性,它的使用方法与vars类似,但是只能put进去String类型的值,而不能是一个对象。对应于java.util.Properties。
a) props.get("START.HMS"); 注:START.HMS为属性名,在文件jmeter.properties中定义
b) props.put("PROP1","1234");
prev - (SampleResult):获取前面的sample采样的结果,常用方法:
a) getResponseDataAsString():获取响应信息
b) getResponseCode() :获取响应code
更多方法可参考:org.apache.jmeter.samplers.SampleResult
sampler - (Sampler):gives access to the current sampler 访问当前采样
如果编写beanshell的过程依赖三方的jar包,需要先导入: 指定要用的jar包的位置:测试计划→浏览(Add direction or jar to classpath)→需要使用的jar包
__regexFunction
包含6个参数,具体截图如下

函数参数描述如下:
第1个参数:必须项,用于解析服务器响应数据的正则表达式,它会找到所有匹配项;
如果希望将表达式中的某部分应用在模板字符串中,一定记得为其加上圆括号。例如,
接的值存放到第一个匹配组合中(这里只有一个匹配组合)。又如,
name="(.*)"value="(.*)">,在这个例子中,链接的name作为第一个匹配组合,链接的value会
作为第二个匹配组合,这些组合可以用在测试人员的模板字符串中。
第2个参数:必须项,模板字符串,函数会动态填写字符串的部分内容。要在字符串中引用正则表达式捕获的匹配组合,请使用语法:[groupnumber][groupnumber]。例如11或者22,模板可以是任何字符串。
第3个参数:非必须项,默认值为1,用于指定JMeter使用第几次匹配;对于找到多个匹配项的详情,有4种选择选择可以设置:
n 整数,使用第几个匹配项,如“1”对应第一个匹配,“2”对应第二个匹配,以此类推;
n RAND,随机选择一个匹配项;
n ALL,使用所有匹配项,为每个匹配项创建一个模板字符串,并将它们连接在一起
n 0到1之间的浮点值,根据公式(总匹配数目*指定浮点值)计算使用第几个匹配项,计算值向最近的整数取整
第4个参数:非必须项,第3个参数中选择了“ALL”,那么这第4个参数会被插入到重复的模板值之间否
第5个参数:非必须项,如果没有找到匹配项返回的默认值否
第6个参数:非必须项,重用函数解析值的引用名,参见上面内容否
第7个参数:非必须项,变量名称。如果指定了这一参数,那么该变量的值就会作为函数的输入,而不再使用前面的采样结果作为搜索对象
Regular Expression Extractor
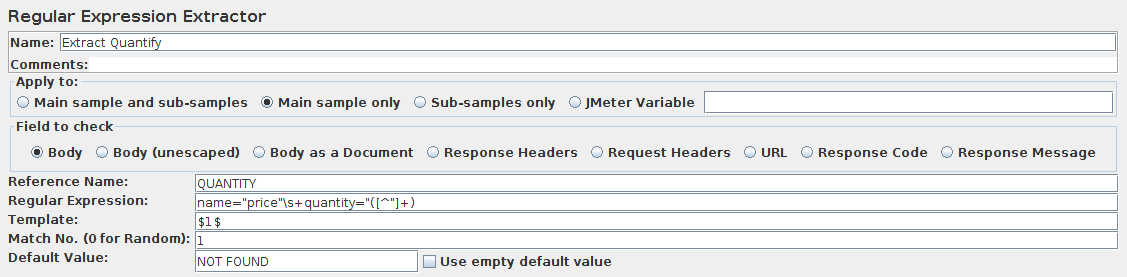
(1)Field to check
Body:响应的body,不包含头信息
Body (unescaped):响应的body HTML中的转义字符被替换(不到万不得已尽量不用)
Body as a Document :通过Tika抽取的多类document对应的文本信息, 会影响性能
Request Headers: 不出现在非http的采样器中
Response Headers : 不出现在非http的采样器中
URL: 请求的URL
Response Code: 响应状态码
Response Message : 响应消息
(2)Reference Name
抽取的表达式对应的变量名. 包含匹配的多个组,访问具体的组:通过 [refname]_g#, 其中[refname] 为reference name栏设置的变量名, #是组序号, 0是全部匹配, 1匹配第一个组
(3)Regular Expression
正则表达式,用于匹配响应数据. 至少包含一个 "()"来捕获字符串的一部分.不要使用 / /将表达式括起来,除非你整整想要匹配这些字符
(4)Template
用于引用具体匹配出来的组,'$1$' 对应group 1, '$2$' 对应group 2, $0$ 对饮匹配的整个表达式
(5)Match No. (默认0 for Random) ,包含如下取值:
0 随机,
正数n 第n个(
refName 表示Template的取值 一定意义上与refName_gn等价
refName_gn, where n=0,1,2 表示具体匹配到的第n组字符串, g0:整个串
refName_g 表示匹配到的group组数 ,与正则表达式中()括号的个数相关)
负数:用于循环遍历 结合ForEach Controller使用 (结合ForEach Controller使用时的必填字段)
针对ForEach Controller,如果使用用户定义的变量,需要变量前缀一致,且是在ForEach Controller下一层添加User Defined Variables ;同名出现的变量名,取第一个;后面的数字可以乱序但是不能间断;注意,start index 是不包含的,所以对于正则表达式提取出来的,要从0开始
(6)关于正则表达式的构造
参看官方文档,其中 ()截取子串 .匹配任意次任意字符 + 大于0次匹配 ?第一次匹配成功就停止继续匹配
(7)Default Value
没有匹配结果时的默认值;主要用于调试
jmx样例中的:http请求~Regular Expression Extractor 依赖上一个请求后的Regular Expression Extractor -access_token即可
__eval
支持在一个变量中插入变量或者函数
_ StringFromFile
从文件中读取字符串,赋值给jmeter变量
第一个参数: 指定文件路径,可以是绝对路径,也可使用相对路径(基于$JMETER_HOME/bin目录)
第二个参数: 指定传递给jmeter进行保存的变量名
第3个参数、4个参数:分别指定起始行、结束行;如果不指定,默认第三个参数是文件第一行,默认第四个参数是文件最后一行
函数每调用一次,读取一行(一行中无论什么字符都会读出来)
示例:
读取jmeter_strfromfile.csv文件中的一行数据存于strfile,jmx可以通过${strfile}使用
${__StringFromFile(D:\soft\apache-jmeter-4.0\bin\scripts\jmeter_strfromfile.csv,strfile,,)}
__Random
生成随机数
第一个参数:随机数下限
第二个参数:随机数上限
第三个参数:在jmeter中保存该随机数的变量名
两个${__Random(,,)}中间加上字符.实现浮点数的随机生成
示例:
insert into jmeter_tab(name,fenshu) values ('${__StringFromFile(D:\soft\apache-jmeter-4.0\bin\scripts\jmeter_strfromfile.csv,strfile,,)}',${__Random(50,100,grade)}.${__Random(0,999,grade)});
备注: 随机数只是数字,通过拼接双引号,变成字符串, 通过拼接‘’ 可以作为varchar插入mysql中
_counter
计数器,
第一个参数:True:局部计数器 FALSE: 全局计数器
第二个参数: 计数器在jmeter中存储的变量名
示例:
${__counter(TRUE,inner_cnt)}
计数器Counter
属于config element:
(1)启动(start):给定计数器的起始值,第一次迭代时,会把该值赋给计数器
(2)递增(Increment):每次迭代后,给计数器增加的值
(3)最大值(Maximum) :计数器的最大值,如果超过最大值,重新设置为初始值(Start),默认的最大值为Long.MAX_VALUE,2^63-1
(4)数字格式(Number format) :可选格式,比如000,格式化为001,002。默认格式为Long.toString(),可当作数字使用
(5)引用名称(Reference Name) :在jmeter中存储或被引用的名称
(6)每用户独立的跟踪计数器(Track Counter Independently for each User):如果不勾选,即全局的,比如用户#1 获取值为1,用户#2获取值为2;勾选,每个用户有自己的值,比如用户#1 获取值为1,用户#2获取值还是为1;每次线程组迭代重置计数器(Reset counter on each Thread Group Iteration) :可选,仅勾选与每用户独立的跟踪计数器时可用,如果勾选了,每次线程组迭代,都会重置计数器的值。当线程组是在一个循环控制器内时比较有用
_intSum
计算多个整数的和,可以是计算正整数和负整数的和,它有N个参数,最少有3个参数,最多不限。最后一个参数是函数名称,前面的其它参数是要求和的整数
变量
(1) 大小写敏感
(2)首位空格自动剔除
(3)作用于线程
(4)不能在变量里面嵌套变量,如${Var${N}}, 不过可以通过${__V(Var${N})}替代实现,也可以通过${__BeanShell(vars.get("Var${N}")}实现
属性
作用于整个测试计划
借助__P or __property来引用
部分不带参数的内部变量,如${__machineIP},可以直接在jmx请求名字中拼接来进行测试