一个简单三层神经网络BP算法的公式推导
一个简单的三层神经网络BP算法的公式推导
- 神经网络表示
- 梯度下降法
- 前向误差传播
- 反向误差传播
神经网络表示
让我们来看一个最简单的神经网络,该神经网络只有三层,分别是输入层,隐藏层和输出层。
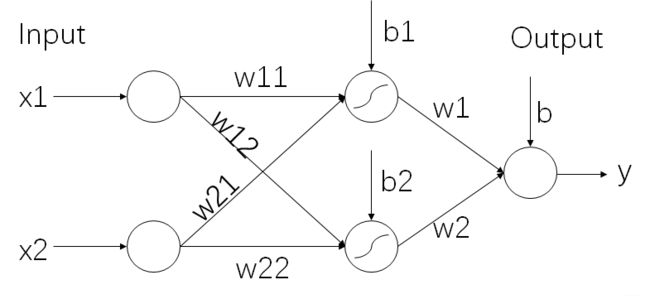
为了表示方便,我们把线性函数和非线性函数分开,神经网络可以画成如下:
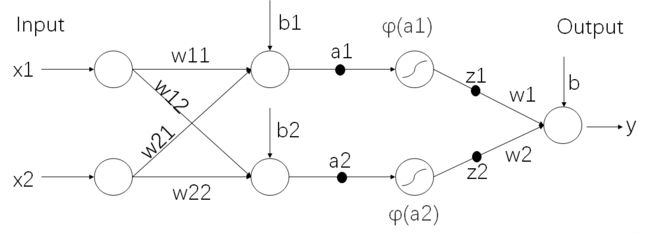
其中φ(x)表示激活函数,我们知道神经网络算法就是为了拟合一个函数从而实现分类或回归等任务。由于前面只使用了线性函数,只能拟合线性函数,但在实际上很多任务的函数形态都是非线性的,所以激活函数的作用就是为了增加函数的非线性,这样就可以拟合任意函数了。
言归正传,整个函数可以写成:
a 1 = w 11 x 1 + w 12 x 2 + b 1 a 2 = w 21 x 1 = w 22 x 2 + b 2 z 1 = φ ( a 1 ) z 2 = φ ( a 2 ) y = w 1 z 1 + w 2 z 2 + b \begin{aligned} a_1&=w_{11}x_1+w_{12}x_2+b_1 \\ a_2&=w_{21}x_1=w_{22}x_2+b_2 \\ z_1&=\varphi(a_1) \\ z_2&=\varphi(a_2) \\ y&=w_1z_1+w_2z_2+b \end{aligned} a1a2z1z2y=w11x1+w12x2+b1=w21x1=w22x2+b2=φ(a1)=φ(a2)=w1z1+w2z2+b
梯度下降法
然后定义损失函数: E = 1 2 ( y − Y ) 2 E = \frac{1}{2}(y-Y)^2 E=21(y−Y)2。其中Y为真实的label,y为预测值,现在我们的任务就是希望通过数据集,不断训练学习到一个函数使得这个损失函数最小。也就是要求 m i n E minE minE时的 w , b w,b w,b参数。
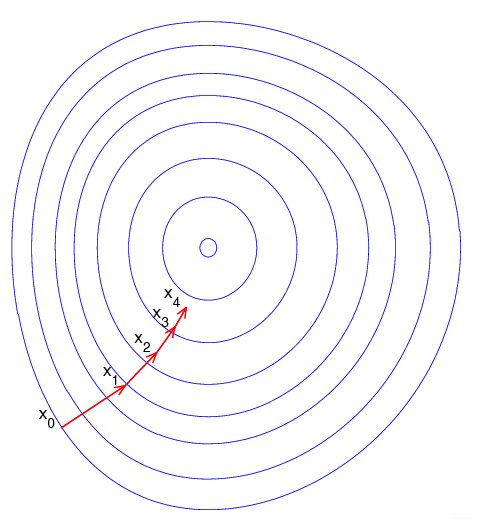
要求 m i n E minE minE时的 w , b w,b w,b参数,在神经网络算法中分为两个步骤,前向误差传播和反向误差传播,其中核心都是使用了梯度下降法。
使用梯度下降法,可以求解最小二乘问题,这还得从Taylor级数多起,对于多元函数 f ( x ) = f ( x 1 , x 2 , x 3 . . . ) f(x)=f(x_1,x_2,x_3...) f(x)=f(x1,x2,x3...)而言,它的梯度(也就是所有偏导数写成向量的形式),可以写成
f ( x ) ′ = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , ∂ f ∂ x 3 . . . ) f(x)'=(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\frac{\partial f}{\partial x_3}...) f(x)′=(∂x1∂f,∂x2∂f,∂x3∂f...)
该函数的Taylor级数为:
f ( x ) = f ( x 0 ) + f ( x 0 ) ′ ( x − x 0 ) + 1 2 ( x − x 0 ) T H ( x − x 0 ) + O ( ∣ x − x 0 ∣ 3 ) f(x)=f(x_0)+f(x_0)'(x-x_0)+\frac{1}{2}(x-x_0)^TH(x-x_0)+O(|x-x_0|^3) f(x)=f(x0)+f(x0)′(x−x0)+21(x−x0)TH(x−x0)+O(∣x−x0∣3)
其中H为Hessian矩阵,由于二次项以及之后的高次项影响较小,求导麻烦,一般计算时会忽略。所以可写成这样:
f ( x ) = f ( x 0 ) + f ( x 0 ) ′ ( x − x 0 ) f(x)=f(x_0)+f(x_0)'(x-x_0) f(x)=f(x0)+f(x0)′(x−x0)
上述式子表示在 x = x 0 x=x_0 x=x0这个位置上, f ( x ) f(x) f(x)函数可以近似写成右侧形式。
由于梯度方向是函数增长最快的方向,目标函数f(x)往往是误差函数,往往我们还会定义学习率 η \eta η,每次下降一点点,若 η \eta η太大会导致当前位置跳到另一侧较高点,迭代多次出现震荡,无法收敛。
于是,我们可以把刚刚的泰勒级数写成更新式:
x 1 k + 1 = x 1 k − η ∂ f ∂ x 1 x k x_1^{k+1}=x_1^{k}-\eta \frac{\partial f}{\partial x_1}x^{k} x1k+1=x1k−η∂x1∂fxk
∂ f ∂ x 1 \frac{\partial f}{\partial x_1} ∂x1∂f为当前点对所有需要学习参数的偏导的集合。
随机定义需要学习的9个参数值:{ w 11 , w 12 , w 21 , w 22 , w 1 , w 2 , b 1 , b 2 , b w_{11},w_{12},w_{21},w_{22},w_1,w_2,b_{1},b_2,b w11,w12,w21,w22,w1,w2,b1,b2,b}
采用sigmoid作为非线性激活函数。
f ( n e t ) = 1 1 + e − n e t f(net) = \frac{1}{1+e^{-net}} f(net)=1+e−net1
其导数为:
f ( n e t ) ′ = f ( n e t ) ( 1 − f ( n e t ) ) f(net)'=f(net)(1-f(net)) f(net)′=f(net)(1−f(net))
前向误差传播
神经网络根据输入x1,x2得到输出y,可以列出以下式子:
y = f ( w 11 x 1 + w 21 x 2 + b 1 ) ∗ w 1 + f ( w 12 x 1 + w 22 x 2 + b 2 ) ∗ w 2 + b y=f({w_{11}x_1+w_{21}x_2+b1})*w_1+f({w_{12}x_1+w_{22}x_2+b2})*w_2+b y=f(w11x1+w21x2+b1)∗w1+f(w12x1+w22x2+b2)∗w2+b
由于随机定义了需要学习的参数,输出y与真实标签Y有一定的差距。
令 E ( w ) = 1 2 ( y − Y ) 2 = 1 2 ( f ( w 11 x 1 + w 21 x 2 + b 1 ) ∗ w 1 + f ( w 12 x 1 + w 22 x 2 + b 2 ) ∗ w 2 + b − Y ) 2 E(w)=\frac{1}{2}(y-Y)^2=\frac{1}{2}(f({w_{11}x_1+w_{21}x_2+b1})*w_1+f({w_{12}x_1+w_{22}x_2+b2})*w_2+b-Y)^2 E(w)=21(y−Y)2=21(f(w11x1+w21x2+b1)∗w1+f(w12x1+w22x2+b2)∗w2+b−Y)2,要求得E(x)最小。
使用F(x)对各个参数求偏导令为0,再进行迭代,定义一个学习率,进行迭代。
∂ E ∂ w 11 , ∂ E ∂ w 12 , ∂ E ∂ w 21 , ∂ E ∂ w 22 , ∂ E ∂ b 1 , ∂ E ∂ b 2 , ∂ E ∂ b \frac{\partial E}{\partial w_{11}},\frac{\partial E}{\partial w_{12}},\frac{\partial E}{\partial w_{21}},\frac{\partial E}{\partial w_{22}},\frac{\partial E}{\partial b_{1}},\frac{\partial E}{\partial b_{2}}, \frac{\partial E}{\partial b} ∂w11∂E,∂w12∂E,∂w21∂E,∂w22∂E,∂b1∂E,∂b2∂E,∂b∂E
比如说
∂ E ∂ b 1 = f ( w 11 x 1 + w 21 x 2 + b 1 ) ( 1 − f ( w 11 x 1 + w 21 x 2 + b 1 ) ) ∗ w 1 = 0 {\frac{\partial E}{\partial b_{1}}}=f({w_{11}x_1+w_{21}x_2+b1})(1-f({w_{11}x_1+w_{21}x_2+b1}))*w_1=0 ∂b1∂E=f(w11x1+w21x2+b1)(1−f(w11x1+w21x2+b1))∗w1=0
再使用梯度下降法更新:
参考sigmoid的导数: f ( n e t ) ′ = f ( n e t ) ( 1 − f ( n e t ) ) f(net)'=f(net)(1-f(net)) f(net)′=f(net)(1−f(net)),以此类推。
反向误差传播
回到刚才的误差准则函数: E ( w ) = 1 2 ( y − Y ) 2 E(w) = \frac{1}{2}(y-Y)^2 E(w)=21(y−Y)2。这一次,要进行反向传播,那么先从输出开始看。
后向传播要做的事情,实际还是求出偏导数 ∂ E ∂ w , ∂ E ∂ b \frac{\partial E}{\partial w}, \frac{\partial E}{\partial b} ∂w∂E,∂b∂E,来进行迭代。
怕大家忘了,重新搬出这张图:
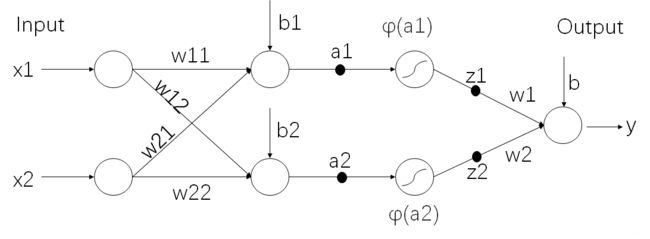
下面涉及到公式就比较复杂了,但是不要慌,实际就是使用了链式法则来求,只要根据上图来,耐心地看完,就应该能看懂。
根据神经网络图,有:
∂ E ∂ y = ( y − Y ) \frac{\partial E}{\partial y}=(y-Y) ∂y∂E=(y−Y)
∂ E ∂ a 1 = d E d y ∂ y ∂ z 1 ∂ z 1 ∂ a 1 = ( y − Y ) ∗ w 1 ∗ f ( a 1 ) ′ \frac{\partial E}{\partial a_1}=\frac{dE}{dy}\frac{\partial y}{\partial z_1}\frac{\partial z_1}{\partial a_1}=(y-Y)*w_1*f(a_1)' ∂a1∂E=dydE∂z1∂y∂a1∂z1=(y−Y)∗w1∗f(a1)′
∂ E ∂ a 2 = d E d y ∂ y ∂ z 2 ∂ z 2 ∂ a 2 = ( y − Y ) ∗ w 1 ∗ f ( a 2 ) ′ \frac{\partial E}{\partial a_2}=\frac{dE}{dy}\frac{\partial y}{\partial z_2}\frac{\partial z_2}{\partial a_2}=(y-Y)*w_1*f(a_2)' ∂a2∂E=dydE∂z2∂y∂a2∂z2=(y−Y)∗w1∗f(a2)′
于是可以算出所有待求偏导数:
∂ E ∂ b = ∂ E ∂ y ∂ y ∂ b = ( y − Y ) ∗ 1 \frac{\partial E}{\partial b}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial b}=(y-Y)*1 ∂b∂E=∂y∂E∂b∂y=(y−Y)∗1
∂ E ∂ w 1 = ∂ E ∂ y ∂ y ∂ w 1 = ( y − Y ) ∗ z 1 \frac{\partial E}{\partial w_1}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial w_1}=(y-Y)*z_1 ∂w1∂E=∂y∂E∂w1∂y=(y−Y)∗z1
∂ E ∂ w 2 = ∂ E ∂ y ∂ y ∂ w 2 = ( y − Y ) ∗ z 2 \frac{\partial E}{\partial w_2}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial w_2}=(y-Y)*z_2 ∂w2∂E=∂y∂E∂w2∂y=(y−Y)∗z2
∂ E ∂ w 11 = ∂ E ∂ y ∂ y ∂ z 1 ∂ z 1 ∂ a 1 ∂ a 1 ∂ w 11 = ( y − Y ) ∗ w 1 ∗ f ( a 1 ) ′ ∗ x 1 \frac{\partial E}{\partial w_{11}}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_1}\frac{\partial z_1}{\partial a_1}\frac{\partial a_1}{\partial w_{11}}=(y-Y)*w_1*f(a_1)'*x_1 ∂w11∂E=∂y∂E∂z1∂y∂a1∂z1∂w11∂a1=(y−Y)∗w1∗f(a1)′∗x1
∂ E ∂ w 12 = ∂ E ∂ y ∂ y ∂ z 1 ∂ z 1 ∂ a 1 ∂ a 1 ∂ w 12 = ( y − Y ) ∗ w 1 ∗ f ( a 1 ) ′ ∗ x 1 \frac{\partial E}{\partial w_{12}}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_1}\frac{\partial z_1}{\partial a_1}\frac{\partial a_1}{\partial w_{12}}=(y-Y)*w_1*f(a_1)'*x_1 ∂w12∂E=∂y∂E∂z1∂y∂a1∂z1∂w12∂a1=(y−Y)∗w1∗f(a1)′∗x1
∂ E ∂ b 1 = ∂ E ∂ y ∂ y ∂ z 1 ∂ z 1 ∂ a 1 ∂ a 1 ∂ b 1 = ( y − Y ) ∗ w 1 ∗ f ( a 1 ) ′ ∗ 1 \frac{\partial E}{\partial b_1}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_1}\frac{\partial z_1}{\partial a_1}\frac{\partial a_1}{\partial b_1}=(y-Y)*w_1*f(a_1)'*1 ∂b1∂E=∂y∂E∂z1∂y∂a1∂z1∂b1∂a1=(y−Y)∗w1∗f(a1)′∗1
∂ E ∂ w 21 = ∂ E ∂ y ∂ y ∂ z 1 ∂ z 1 ∂ a 1 ∂ a 1 ∂ w 21 = ( y − Y ) ∗ w 1 ∗ f ( a 1 ) ′ ∗ x 2 \frac{\partial E}{\partial w_{21}}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_1}\frac{\partial z_1}{\partial a_1}\frac{\partial a_1}{\partial w_{21}}=(y-Y)*w_1*f(a_1)'*x_2 ∂w21∂E=∂y∂E∂z1∂y∂a1∂z1∂w21∂a1=(y−Y)∗w1∗f(a1)′∗x2
∂ E ∂ w 22 = ∂ E ∂ y ∂ y ∂ z 2 ∂ z 2 ∂ a 2 ∂ a 2 ∂ w 22 = ( y − Y ) ∗ w 2 ∗ f ( a 2 ) ′ ∗ x 2 \frac{\partial E}{\partial w_{22}}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_2}\frac{\partial z_2}{\partial a_2}\frac{\partial a_2}{\partial w_{22}}=(y-Y)*w_2*f(a_2)'*x_2 ∂w22∂E=∂y∂E∂z2∂y∂a2∂z2∂w22∂a2=(y−Y)∗w2∗f(a2)′∗x2
∂ E ∂ b 2 = ∂ E ∂ y ∂ y ∂ z 2 ∂ z 2 ∂ a 2 ∂ a 2 ∂ b 2 = ( y − Y ) ∗ w 1 ∗ f ( a 2 ) ′ ∗ 1 \frac{\partial E}{\partial b_2}=\frac{\partial E}{\partial y}\frac{\partial y}{\partial z_2}\frac{\partial z_2}{\partial a_2}\frac{\partial a_2}{\partial b_2}=(y-Y)*w_1*f(a_2)'*1 ∂b2∂E=∂y∂E∂z2∂y∂a2∂z2∂b2∂a2=(y−Y)∗w1∗f(a2)′∗1
求出偏导数之后,进行迭代就完事了。
上面显示了一个简单的三层神经网络的前向传播与后向传播的公式推导,一般进行学习的时候,会把一个batch的数据往学习器里送,先进行一次前向传播,再进行一次后向传播,当训练完所有训练集,称之为一个epoch。有机会给大家推导一下一般形式的三层BP神经网络~