zookeeper的选举机制
zookeeper是一个分布式的协调系统协调系统。zookeeper保证了数据在ZK之间数据的事务性的一致性。其中zookeeper提供了分布式的锁服务,用于协调分布式应用程序。zookeeper的应用主要有储存元数据信息和选举机制。例如在hadoop中可以利用zookeeper选取namenode的active状态,可以在znode下储存对应的信息,来决定哪台nameNode是active状态的。在HBase中,zookeeper负责储存region的信息以及Master的选取。在Storm中负责储存数据的元数据信息。
选举机制中的概念
1.服务器ID
比如说三台服务器,1、2、3------》以为着编号越大,在选举算法中的权重越大
2.数据ID
数据的ID越大说明数据越新,在选举算法中权重越大
3.逻辑时钟
也可以说投票的次数,同一轮投票中逻辑时钟是一样的,每投完一次票这个逻辑时钟就会增加,然后接受到其他服务器中返回的信息相比,根据不同的值做出不同的判断。
4.选举状态
LOOKING:竞选状态
FOLLOWING:随从状态,同步leader状态,参与投票
OBASERVING:观察状态,同步leader状态,不参与投票
LEADING:领导者状态
在投票完成后将服务器ID、数据ID、逻辑时钟、选举状态同步到所有的zookeeper服务器中
选举流程图
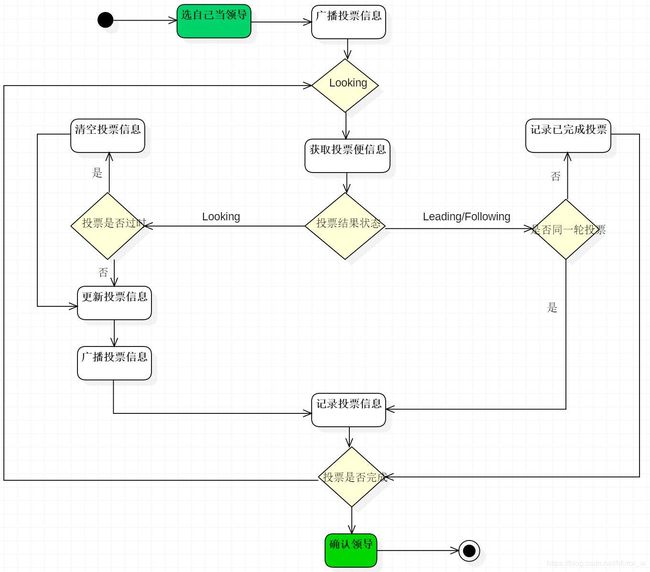 https://blog.csdn.net/Mirror_w
https://blog.csdn.net/Mirror_w
选举经典例子
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟
源码分析
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
选举源码
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}选举算法
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException {
//...
try {
HashMap recvset = new HashMap();
HashMap outofelection = new HashMap();
int notTimeout = finalizeWait;
synchronized(this){
//给自己投票
logicalclock.incrementAndGet();
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
//将投票信息发送给集群中的每个服务器
sendNotifications();
//循环,如果是竞选状态一直到选举出结果
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
//没有收到投票信息
if(n == null){
if(manager.haveDelivered()){
sendNotifications();
} else {
manager.connectAll();
}
//...
}
//收到投票信息
else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) {
switch (n.state) {
case LOOKING:
// 判断投票是否过时,如果过时就清除之前已经接收到的信息
if (n.electionEpoch > logicalclock.get()) {
logicalclock.set(n.electionEpoch);
recvset.clear();
//更新投票信息
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
updateProposal(getInitId(),
getInitLastLoggedZxid(),
getPeerEpoch());
}
//发送投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//忽略
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
//更新投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if (termPredicate(recvset,
new Vote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){
recvqueue.put(n);
break;
}
}
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(proposedLeader,
proposedZxid, proposedEpoch);
leaveInstance(endVote);
return endVote;
}
}
break;
case OBSERVING:
//忽略
break;
case FOLLOWING:
case LEADING:
//如果是同一轮投票
if(n.electionEpoch == logicalclock.get()){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//判断是否投票结束
if(termPredicate(recvset, new Vote(n.leader,
n.zxid, n.electionEpoch, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, n.electionEpoch)) {
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
//记录投票已经完成
outofelection.put(n.sid, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
if (termPredicate(outofelection, new Vote(n.leader,
IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
&& checkLeader(outofelection, n.leader, IGNOREVALUE)) {
synchronized(this){
logicalclock.set(n.electionEpoch);
self.setPeerState((n.leader == self.getId()) ?
ServerState.LEADING: learningState());
}
Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
//忽略
break;
}
} else {
LOG.warn("Ignoring notification from non-cluster member " + n.sid);
}
}
return null;
} finally {
//...
}
} 判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑