python笔记:jieba分词与wordcloud词云的使用
python笔记:jieba分词
运用jieba对三国演义进行分词,统计出现人物次数排行前十的人物:
首先加载文件
txt = open('三国演义.txt','r',encoding='utf-8').read()

如果文件报错,出现UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc8 in position 0异常,这里解决办法有两种,一种是改变encoding ,将utf-8改为gb18030 ,或者将文件另存为,书将编码改为UTF-8
words = jieba.lcut(txt) #jieba库的精确模式
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word]= counts.get(word,0)+1
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
创建一个空的字典counts,索引word中的单词,从而进行对出现词语的统计,reverse=True:将其由大到小排列,从而得出结果
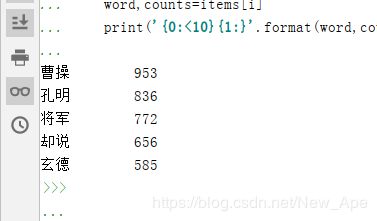
for i in range(10):
word,counts=items[i]
print('{0:<10}{1:}'.format(word,counts))
构建循环体系,将出现的字符串前十个提取出来,这样就基本完成用jieba库对文件的分词
想要获取人物名称,从而获得在三国演义中名字出现次数前十的人,因此需要对数据进行一定量的修正清洗,如古代的玄德和刘备都是表示这刘备,因此进行处理
for word in words:
if len(word) == 1:
continue
elif word=='诸葛亮' or word =='孔明曰':
rword ='孔明'
elif word=='关公' or word =='云长':
rword ='关羽'
elif word=='玄德' or word =='玄德曰':
rword ='刘备'
elif word=='孟德' or word == '丞相':
rword ='曹操'
elif word =='都督' :
rword ='周瑜'
else:
rword = word
counts[rword]= counts.get(rword,0)+1
del1 = {'将军','却说','二人','不可','荆州','不能','如此','商议','如何','主公','军士','左右','军马','引兵','次日','大喜','东吴','于是','今日','不敢','魏兵','陛下','天下'\
,'一人'}
for word in del1:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
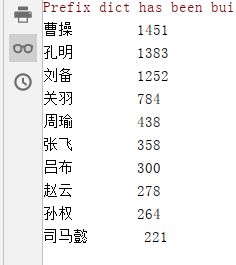
for i in range(10):
word,counts=items[i]
print('{0:<10}{1:}'.format(word,counts))
获取到这些排在前列却又不是人名的词语,从而进行清除,然后打印输入,就可以获得结果
接下来进行词云展示,并改变图像模型展现出词语次数比较多的图像
import wordcloud
import jieba
from scipy.misc import imread
mask = imread('20150722083827844.jpg') #加载要改变的模板图像
f = open('a.txt','r',encoding='utf-8')
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = ' '.join(ls)
w =wordcloud.WordCloud(font_path='msyhbd.ttf',mask =mask,
width=1000,height=700,background_color='white') #mask设置图像形状
w.generate(txt)
w.to_file('a.png')

如果在加载imread的时候出现错误如下:
ImportError: cannot import name ‘imread’ from ‘scipy.misc’
那么就cmd然后执行语句
pip install scipy==1.21
就可以了