关于SQL解析,为何编程语言解析器ANTLR更胜一筹?

本文转载自:DBAplus社群
作者介绍
杜红军,京东数科软件工程师,多年中间件开发及系统设计经验,对Spring、MyBatis等相关开源技术有深入了解。目前在Sharding-Sphere团队负责SQL解析开发工作。
相对于其他编程语言来说,SQL是比较简单的。不过,它依然是一门完善的编程语言,因此对SQL的语法进行解析,与解析其他编程语言(如:Java语言、C语言、Go语言等)并无本质区别。
一、概念
谈到SQL解析,就不得不谈一下文本识别。文本识别是根据给定的规则把输入文本的各个部分识别出来,再按照特定的数据格式输出。以树形结构输出是最常见的方式,这就是通常所说的抽象语法树(AST)。
作为一个开发者,文本识别每天都和我们打交道。在编写完代码之后,编译器在编译时首先需要根据程序的语法对代码做解析,即文本识别,并生成中间代码。
SQL解析和程序代码解析类似,它按照SQL语法对SQL文本进行解析,识别出文本中各个部分然后以抽象语法树的形式输出。SQL也是一门编程语言,它并不比其他编程语言的语法简单。一个复杂的建表语句占用20多k字节也是正常的。
无论是对SQL进行解析,还是对其他编程语言的语法进行解析,都需要专门的解析器。从零开发则需要较长的时间,而且各种数据库的SQL方言不尽相同,这并不是一套能够完全通用的SQL解析引擎。在各种第三方类库十分完善的现今,找寻一个利器,比从零开发这种刀耕火种的方式好得多。开源的SQL解析器有JSQLParser、FDB和Druid等,用于语法解析的主要有ANTLR、JavaCC等。
JSQLParser是一个通用的SQL解析器,它提供一站式的SQL解析能力,将SQL转化为语法树,并提供树访问接口供程序遍历语法树。虽然使用便利,但它也有一些缺点:
无法根据所需的语法生成解析器。对于数据分片所需要的语法来说,它不如ANTLR这样能够根据自己需求书写语法规则的方式轻量级;
只支持部分常用的标准SQL语法,像ALTER TABLE、ALTER INDEX、DCL以及各类数据库的方言支持的力度不足;
它采用Visitor模式将抽象语法树完全封装,外围程序无法直接访问抽象语法树,在无需完全遍历树时,代码比较繁琐。
FDB和Driuid与JSQLParser同类型。它们无需自定义SQL语法,可以拿来即用,但缺乏自定义语法的灵活度。
相对来说,ANTLR则好一些。它并非为SQL解析专门定制的解析器,而是通用的编程语言解析器。它只需编写名为G4的语法文件,即可自动生成解析的代码,并且以统一的格式输出,处理起来非常简单。由于G4文件是通过开发者自行定制的,因此由ANTLR所生成的代码也更加简洁和个性化。在编写仅适用于数据分片的语法规则时,可以简化大量无需关注的SQL语法。对于SQL审计等SQL解析的需求,完全可以用ANTRL编写另外一份语法规则,可以达到因地制宜的效果。JavaCC与ANTLR类似,都属于自定义语法类型的解析器。
无论采用哪种解析器,解析过程都是一致的,它分为词法解析(Lexer)和语法解析(Parser)两部分。
先通过词法解析器将SQL拆分为一个个不可再分的词法单元(Token)。在SQL语法中,通常将词法单元分为关键字、标识符、字面量、运算符和分界符。
关键字:数据库引擎所用到的特殊词,为保留字符,不能用做标识符;
标识符:在SQL语法中是表名称、列名称等。对应于编程语言则是包名、类名、方法名、变量名、属性名等等;
字面量:包括字符串和数值;
运算符:包括加减乘除、位运算、逻辑运算等;
分界符:逗号、分号、括号等。
词法解析器每次读取一个字符,在当前字符与之前的字符所属分类不一致时,即完成一个词法单元的识别。例如,读取SELECT时,第一个字符是’S’,满足关键字和标示符的规则,第二个字符’E’也同样满足,以此类推,直到第7个字符是空格时,则不满足该规则,那么就完成了一个词法单元的识别。SELECT既是SQL规范定义的关键字,又同时满足标识符规则,因此当一个词法单元是标识符时,解析器需要有优先级的判断,需要先确定它是否为关键字。其他的规则相对简单,如:以数字开头的字符则根据数值规则的字面量读取字符;以双引号或单引号开头的则根据字符串规则的字面量读取字符;运算符或分界符就更易识别。举例说明,以下SQL:
识别之后的词法单元为:
关键字:SELECT、FROM、WHERE
标识符:id、name、product
字面量:10
运算符:>
分界符:,和;
语法解析器每次从词法解析器中获取一个词法单元。如果满足规则,则继续下一个词法单元的提取和匹配,直至字符串结束;若不满足规则,便提示错误并结束本次解析。
语法解析难点在于规则的循环处理以及分支选择,还有递归调用和复杂的计算表达式等。
在处理循环规则时,当匹配完成一个规则时,匹配规则需要循环地再次匹配当前规则,当其不再是当前的规则定义时,才可以继续进行后续规则的匹配。以CREATE TABLE语句为例。每张表可以包含多列,每个列都可能需要定义名称、类型、精度等参数。
当一个规则中存在多条分支路径时,则需要超前搜索,语法解析器必须和每个可能的分支进行匹配来确定正确的路径。以ALTER TABLE语句为例。
修改表名语法为:
删除列的语法为:
两个语句均以ALTER TABLE开头,它们合并在一起的语法为:
匹配完成tableName之后的2个分支选项,需要超前搜索来确定正确的分支。
在选择分支时,可能会出现一个分支是另一个分支的子集。此时,当成功匹配短路径时,需要进一步匹配长路径,在无法匹配长路径时,再选取短路径,这称之为贪婪匹配。如果不使用贪婪匹配的算法,则最长的分支规则便永远不能被匹配了。
当词法单元不满足一个可选规则时,则需要与下个规则做匹配,直至匹配成功或与下个非可选规则匹配失败。在CREATE TABLE语句中,定义列时存在很多可选项,比如是否为空、是否主键、是否存在约束条件等。
语法解析器最终将SQL转换为抽象语法树。例如以下SQL:
解析之后的为抽象语法树见下图:
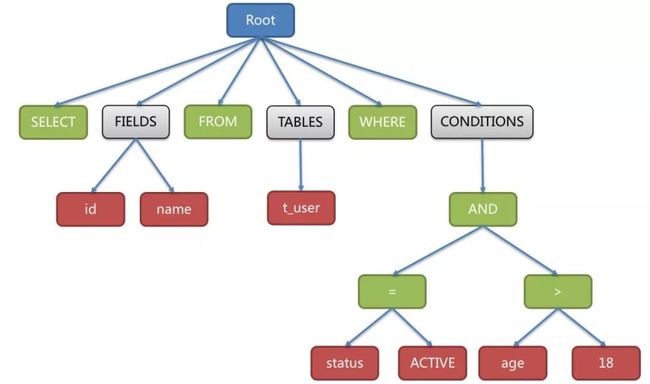
为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分。
语法解析要比词法解析复杂一些,词法解析的规则相对简单,定义好词法单元的规则即可,极少出现分支选择;而且只需超前搜索一个字符即可确定词法单元。但它却是解析的基础,如果分词出现错误,语法解析则很难正确处理。
生成抽象语法树的第三方工具有很多,ANTLR是不错的选择。它将开发者定义的规则生成抽象语法树的Java代码并提供访问者接口。相比于代码生成,手写抽象语法树在执行效率方面会更加高效,但是工作量也比较大。在性能要求高的场景中,可以考虑定制化抽象语法树。
二、ANTLR
ANTLR是Another Tool for Language Recognition的简写,是一个用Java语言编写的识别器工具。它能够自动生成解析器,并将用户编写的ANTLR语法规则直接生成目标语言的解析器,它能够生成Java、Go、C等语言的解析器客户端。
ANTLR所生成的解析器客户端将输入的文本生成抽象语法树,并提供遍历树的接口,以访问文本的各个部分。ANTLR的实现与前文所讲述的词法分析与语法分析是一致的。词法分析器根据语法规则做词法单元的拆分;语法分析器对词法单元做语义分析,并对规则进行优化以及消除左递归等操作。
ANTLR语法规则的主要工作是定义词法解析规则和语法解析规则。ANTLR约定词法解析规则以大写字母开头,语法解析规则以小写字母开头。下面简单介绍一下ANTLR的规则。
首先需要定义Grammar类型及名称,名称必须和文件名一样。有Lexer、Parser、Tree和Combine这4种语法类型。
Lexer定义词法分析规则;
Parser 定义语法分析规则;
Tree用于遍历语法分析树;
Combine既可以定义语法分析规则,也可定义词法分析规则,规则名称遵循上述规则;
Import 用于导入语法规则。使用Import语法规则分类,可以使语法规则更加清晰;并且可以采用面向对象的思想设计规则文件,使其具有多态及继承的思想。值得注意的是,当前规则的优先级高于导入规则。
规则名称及内容以冒号分隔,分号结尾。例如:
规则的名称是NUM,以大写字母开头,因此是词法分析的规则;规则的内容是[0-9]+,表示所有的整数。
ANTLR规则基于BNF范式,用’|’表示分支选项,’*’表示匹配前一个匹配项0次或者多次,’+’ 表示匹配前一个匹配项至少一次。
语法其它部分,读者感兴趣的话请查阅官方文档。
ANTLR生成SQL解析器,首先就是要定义SQL的词法解析器和语法解析器,下面一一介绍。
与之前的SQL解析原理相同,ANTLR的词法解析同样是将SQL拆分为词法单元。ANTLR解析词法规则时,并不理解规则的具体含义,不清楚哪些规则是关键字定义,哪些规则是标识符定义,它会根据读取顺序为每个规则编号,编号靠前的规则将优先匹配,匹配成功则直接返回该词法单元。在设计词法拆分规则时,需要将标识符规则放置在关键字规则之后,确保关键字匹配失败后,再去匹配标识符。
ANTLR采用状态转换表实现字符的匹配。它将词法拆分规则转换为表格,每次读取一个字符,根据当前字符类型及当前状态查询该表,并判断读入字符是否匹配规则。如果规则匹配,则接受该字符,并继续读取下个字符;如果规则不匹配,则拒绝接受该字符。此时,若当前状态是成功匹配某一词法单元的可接受状态,则返回该词法单元;反之则提示错误。以此类推,如果接受该字符,则继续读取下一字符。直至成功返回一个词法单元或匹配失败提示错误。
举例说明,以下是一个简易的查询语句词法拆分规则:
lexer grammar SelectLexer;
SELECT: [Ss] [Ee] [Ll] [Ee] [Cc] [Tt];
FROM: [Ff] [Rr] [Oo] [Mm];
WHERE: [Ww] [Hh] [Ee] [Rr] [Ee];
LEFT: [Ll][Ee][Ff][Tt];
RIGHT: [Rr][Ii][Gg][Hh][Tt];
INNER: [Ii][Nn][Nn][Ee][Rr];
JOIN: [Jj] [Oo] [Ii] [Nn];
ON : [Oo][Nn];
BETWEEN: [Bb] [Ee] [Ee] [Rr] [Ee];
AND: [Aa] [Nn] [Dd];
OR:[Oo][Rr];
GROUP: [Gg] [Rr] [Oo] [Uu] [Pp];
BY:[Bb] [Yy];
ORDER: [Oo] [Rr] [Dd] [Ee] [Rr];
ASC:[Aa][Ss][Cc];
DESC:[Dd][Ee][Ss][Cc];
IN: [Ii][Nn];
ID: [a-zA-Z0-9]+;
WS: [ ] + ->skip;
它定义了大小写不敏感的从SELECT到IN的关键字规则以及标识符规则ID,标识符规则放在最后。WS规则表示遇到空格、制表符、换行符跳过。输入字符中任何字符,在词法分析器中都要找到对应的规则,否则会提示失败。如果去掉WS规则,对于包含空格的SQL将会得到以下的错误提示。

错误原因是第1行的第6、第10以及第11个字符是回车换行符,词法规则找不到对应的规则。
ANTLR的语法解析用于定义组成语句的短语规则。语法规则由各个数据库厂商提供,因此,在SQL解析时,只需要将它们转换为ANTLR的语法规则即可。需要注意的是,SQL表达式的规则定义十分复杂。不仅包括常见的数学表达式和布尔表达式,还包括函数调用以及各数据库的私有日期表达式、Window函数、Case语句等。
ANTLR同样采用状态转换表的方式检查词法单元是否满足语法规则。语法分析器调用词法分析器获取词法单元并其检查是否符合规则。当遇到多个选项分支时,则采用贪婪匹配原则,优先走完最长路径的分支。如果分支中有多个规则满足条件,按顺序匹配。
以如下规则举例说明:
grammar Test;
ID: [a-zA-Z0-9]+;
WS: [ ] + ->skip;
testAll:test1 |test2|test3|test21;
test1:ID;
test2:ID ID;
test21:ID ID;
test3:ID ID ID;
test4:test1+;
使用testAll规则做如下测试:
当输入的参数为“a1 a2 a3”时,使用test3分支,而并未使用(test1 a1) (test1 a2) (test1 a3)或(test2 a1 a2) (test1 a3)这种匹配模式;
当输入的参数为“a1 a2”时,虽然test21规则也能够匹配,但前面有test2规则匹配,因此使用test2规则;
当输入的参数为“a1 a2 #”,由于无法匹配‘#’,因此提示错误。
完成了SQL解析之后,最后一步便是对数据分片所需的上下文进行提取。它通过对SQL的理解,以访问抽象语法树的方式去提炼分片所需的上下文,并标记有可能需要改写的位置。供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)等。
三、Sharding-Sphere中的SQL解析
SQL解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标。
Sharding-Sphere的前身,Sharding-Sphere在1.4.x之前的版本使用Druid作为SQL解析器。经实际测试,它的性能远超其它解析器。
从1.5.x版本开始,Sharding-Sphere采用完全自研的SQL解析引擎。由于目的不同,Sharding-Sphere并不需要将SQL转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它采用对SQL“半理解”的方式,仅提炼数据分片需要关注的上下文,因此SQL解析的性能和兼容性得到了进一步的提高。
在最新的3.x版本中,Sharding-Sphere尝试使用ANTLR作为SQL解析的引擎,并计划根据DDL->TCL->DAL–>DCL->DML–>DQL这个顺序,依次替换原有的解析引擎。使用ANTLR的原因是希望Sharding-Sphere的解析引擎能够更好地对SQL进行兼容。对于复杂的表达式、递归、子查询等语句,虽然Sharding-Sphere的分片核心并不关注,但是会影响对于SQL理解的友好度。自研的SQL解析引擎为了性能的极致,对这些方便并未处理,使用时会直接报错。
经过实例测试,ANTLR解析SQL的性能比自研的SQL解析引擎慢3倍左右。为弥补差距,Sharding-Sphere将使用Prepared Statement的SQL解析的语法树放入缓存。因此建议采用PreparedStatement这种SQL预编译的方式提升性能。Sharding-Sphere会提供配置项,将两种解析引擎共存,交由用户抉择SQL解析的兼容性与性能。
Sharding-Sphere近期相关计划安排是什么呢?欢迎大家来github围观、留言!
https://github.com/sharding-sphere/sharding-sphere/issues/1189
Sharding-Sphere自2016开源以来,不断精进、不断发展,被越来越多的企业和个人认可:在Github上收获5000+的star,2000+forks,60+公司企业的成功案例。此外,越来越多的企业和个人也加入到Sharding-Sphere的开源项目中,为它的成长和发展贡献了巨大力量。
我们从未停息过脚步,聆听社区伙伴的需求和建议,不断开发新的、强大的功能,不断使其健壮可靠!
开源不易, 我们却愿向着最终的目标,步履不停!
那么,正在阅读的你,是否可以助我们一臂之力呢?分享、转发、使用、交流,以及加入我们,都是对我们最大的鼓励!
项目地址:
https://github.com/sharding-sphere/sharding-sphere/
更多信息请浏览官网:
http://shardingsphere.io/
扫码进群


