(一)深度学习实战 | 基于PyTorch的目标检测数据加载
1. PyTorch加载数据
P y T o r c h {\rm PyTorch} PyTorch中使用 D a t a s e t {\rm Dataset} Dataset和 D a t a L o a d e r {\rm DataLoader} DataLoader两个工具类完成数据的加载,前者用于构造数据集(数据集能够通过索引取出一条数据)、后者用于取一批次的数据( P y T o r c h {\rm PyTorch} PyTorch只支持批数据处理)。本文介绍使用 P y T o r c h {\rm PyTorch} PyTorch处理目标检测数据,主要涉及 V O C {\rm VOC} VOC标注格式的数据集和 C O C O {\rm COCO} COCO标注格式的数据集两种,其加载数据的整体结构如下:
from torch.utils.data import Dataset, DataLoader
class CustomDataSet(Dataset):
def __init__(self):
pass
def __getitem__(self, index):
pass
def __len__(self):
pass
dataset = CustomDataSet()
dataloader = DataLoader(
dataset=dataset,
batch_size=64,
shuffle=True,
num_workers=4)
CustomDataSet是我们自定义的数据加载类,其继承自Dataset类。__init__方法用于定义一些初始化操作。我们可以通过该方法将所有数据加载至内存,后续通过索引在内存中取相应数据,这适合于数据本身很小的情况下;而我们更多采用的是首先将数据的路径存在相关文件内,后续根据路径索引取得相应数据,这往往应用于数据量较大的情况。__getitem__方法的功能是根据索引取出一条数据。注意该数据是处理后的数据,可以直接作为网络的输入,所以在返回前需要进行一些必要的如数据增强、标准化等操作。__len__方法用于返回数据集的条数。- 最后使用
DataLoader类制作数据加载器,我们通常使用的几个参数如上面程序所示。第一个参数dataset就是前面我们定义的数据加载类的对象;第二参数batch_szie是每批次数据的大小,通常根据内存等确定;第三个参数shuffle是每次加载一批数据时是否将其打乱,在训练时一般设置为 T r u e {\rm True} True、测试时设置为 F a l s e {\rm False} False;第四个参数num_workers是在读取数据时使用的线程数。 - 有时候为了实现更加高效的数据加载,我们会使用
DataLoader类的其他参数,可参考 P y T o r c h {\rm PyTorch} PyTorch文档,可参考这里。
以上介绍了使用 P y T o r c h {\rm PyTorch} PyTorch加载数据时的整体结构,下面就 V O C {\rm VOC} VOC标注格式的数据集和 C O C O {\rm COCO} COCO标注格式的数据集分别介绍相应的处理流程。
2. VOC格式数据集的加载
V O C {\rm VOC} VOC数据集大致有 2007 {\rm 2007} 2007和 2012 {\rm 2012} 2012两个版本,二者标注形式完全一致,只是数据量不同,数据集可以在这里下载(本文以 V O C 2007 {\rm VOC\ 2007} VOC 2007为例说明)。同时,我们可以将自己的数据集制作为 V O C {\rm VOC} VOC格式,这里使用的是 l a b e l I m g {\rm labelImg} labelImg工具。首先在使用pip install labelImg命令安装工具,安装成功后输入labelImg即可打开可视化界面。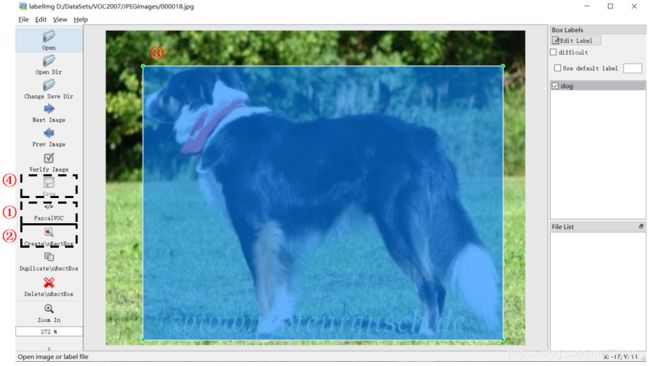
数据集的目录结构如下图。在制作自己的数据集时,首先我们要依照下图格式建立相应的文件夹。然后如上图分别执行对应的四个步骤。其中在画完框后会自动弹出来一个对话框,此时我们需要输入该标注目标的类别。最后根据标注信息将自动生成.xml文件。

其中,第一个文件夹用于存放数据集的标注信息,以.xml文件保存。我们以目标检测部分的标注信息介绍文件内的具体内容,以000002.xml为例。

第二个文件夹内的Main文件夹存放着目标检测相关的文件。其中train.txt、val.txt、test.txt和trainval.txt分别存放了训练集、验证集、测试集和训练验证集的图像名称。第三个文件夹内存放图像本身,如上述标注文件对应的图像000002.jpg为下图。

第四个文件夹和第五个文件夹内存放的图像分割的相关标注信息。首先我们来定义文件解析类,其参数是ElementTree类的对象(用于解析 x m l {\rm xml} xml文件的类),返回是对应文件所包含的标注信息。
class VOCAnnotationTransform:
def __init__(self):
# 将类别标签转换为对应的数字标签
self.class_to_ind = dict(zip(VOC_CLASSES, range(len(VOC_CLASSES))))
def __call__(self, target, width, height):
res = []
for obj in target.iter('object'):
# 目标类别
name = obj.find('name').text.lower().strip()
# 标注框
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
# 将坐标值缩放到[0,1]内
cur_pt = int(bbox.find(pt).text) - 1
cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
# 获取类别和标注框信息并添加到结果
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res += [bndbox]
return res # res=[[xmin, ymin, xmax, ymax, label_ind], ... ]
然后定义数据加载类。在数据加载时,只有当使用到该条数据时我们才将其加载到内存,在函数pull_item函数内实现。最后通过__getitem__函数返回指定index的数据。
class VOCDetection(data.Dataset):
def __init__(self, root, target_transform=VOCAnnotationTransform()):
# 数据集根目录
self.root = root
# 调用解析类
self.target_transform = target_transform
# 文件路径
self.annopath = osp.join('%s', 'Annotations', '%s.xml')
self.imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')
# self.ids=((数据集根目录, 文件名),...),作用是与上面“文件路径”变量组合称为完整路径
self.ids = list()
for line in open(osp.join(self.root, 'ImageSets', 'Main', "trainval" + '.txt')):
self.ids.append((self.root, line.strip()))
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
# 返回数据
return im, gt
def __len__(self):
return len(self.ids)
def pull_item(self, index):
# 根据index取出某一条(数据集根目录, 文件名)
img_id = self.ids[index]
# 组合成完成路径后解析xml文件和读取图像
target = ET.parse(self.annopath % img_id).getroot()
img = cv2.imread(self.imgpath % img_id)
height, width, channels = img.shape
# xml解析
if self.target_transform is not None:
target = self.target_transform(target, width, height)
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
3. COCO格式数据集的加载
相比于 V O C {\rm VOC} VOC数据集, C O C O {\rm COCO} COCO数据量更大、图像中小目标居多、图像中的目标数据更多等,因此其常作为当前目标检测算法的判断基准。另外一个不同是, V O C {\rm VOC} VOC数据集中每张图像都有与之对应的标注文件,而 C O C O {\rm COCO} COCO数据集中的所有图像的标注信息存放在一个.json文件。同时,我们可以将自己的数据集制作为 C O C O {\rm COCO} COCO格式,这里使用的是 l a b e l m e {\rm labelme} labelme工具。首先在使用pip install labelme命令安装工具,安装成功后输入labelme即可打开可视化界面。其标注方式与上相似,这里不再赘述。
本文以 C O C O 2017 {\rm COCO\ 2017} COCO 2017数据集为例进行说明。 C O C O {\rm COCO} COCO数据集官方提供了 C O C O A P I {\rm COCO\ API} COCO API用于更加方便地解析标注文件,在使用之前通过pip install pycocotools安装依赖。数据集和 C O C O A P I {\rm COCO\ API} COCO API相关信息可以在这里下载和查看。首先,我们来介绍 C O C O A P I {\rm COCO\ API} COCO API的相关内容。
在使用各 A P I {\rm API} API前,我们需要实例化COCO类,它接受的参数为标注文件的路径,返回类的对象。以本文的内容为例,首先我们使用以下语句初始化COCO类的对象。这里使用的是 C O C O 2017 {\rm COCO\ 2017} COCO 2017数据集中对应的训练集部分。
coco = COCO(os.path.join(root, 'annotations', 'instances_{}.json'.format('train2017')))
然后,我们就可以通过COCO类的对象调用各种 A P I {\rm API} API函数。其中,在本文将会使用的 A P I {\rm API} API函数包括:
coco.imgToAnns将图像的索引与其标注信息相关联,执行后的效果是给定指定的图像索引可以返回该图像对应的所有标注信息,coco.imgToAnns.keys()返回所有的图像的索引(给数据集中的每幅图像赋值一个索引,用于后续与其标注和类别信息相关联),然后再通过指定图像的索引就可以访问其相关的标注信息。如下图是各索引之间的相互关联。

注意每个annotation里面仅对应于一个目标的标注信息。如果我们使用coco.imgToAnns.keys()[index],则 将区域索引为 i n d e x {\rm index} index的图像对应的标注信息的索引,是一个列表。然后根据每个标注信息的索引去寻找每一个目标的标注信息。如上图,bbox即为本文中我们所需要的目标检测的标注信息。coco.getAnnIds(imgIds=imgIds)就是根据参数值取指定索引图像的标注信息,返回一个列表。- 得到标注信息的索引的列表后,我们就可以使用
coco.loadAnns(ids=ann_ids)返回指定标注索引的标注内容,其中同时包括目标检测和图像分割的内容。也就是上图中的annotations{}部分。 - 同时,根据
coco.loadImgs(ids=img_ids)就可以获得指定图像索引的图像信息,其格式如下:

则现在我们可以完成整个数据加载类的书写。首先我们需要注意的是,由于 C O C O {\rm COCO} COCO数据集中的索引并不是连续的,如图: 最左边是原始的索引,中间是经过处理后的索引,最后一列表示具体的类别。首先,我们需要根据该文件的内容使用中间一列的索引作为最后的索引。定义如下函数:
最左边是原始的索引,中间是经过处理后的索引,最后一列表示具体的类别。首先,我们需要根据该文件的内容使用中间一列的索引作为最后的索引。定义如下函数:
def get_label_map(label_file):
label_map = {}
labels = open(label_file, 'r')
for line in labels:
ids = line.split(',')
# 返回字典形式,如上图中的为{...,11:11,13:12,14:16,...}
label_map[int(ids[0])] = int(ids[1])
return label_map
和 V O C {\rm VOC} VOC数据集的加载流程一致,首先我们定义解析类COCOAnnotationTransform,传入参数是标注信息,即上文提到的一系列的annotations{}。然后返回形式同VOCAnnotationTransform类一致。
class COCOAnnotationTransform:
def __init__(self):
self.label_map = get_label_map(osp.join('data', 'coco_labels.txt'))
def __call__(self, target, width, height):
scale = np.array([width, height, width, height])
res = []
for obj in target:
if 'bbox' in obj:
# 将(x,y,w,h)->(xmin,ymin,xmax,ymax)
bbox = obj['bbox']
bbox[2] += bbox[0]
bbox[3] += bbox[1]
# 将坐标值缩放到[0,1]内
final_box = list(np.array(bbox)/scale)
# 获取类别和标注框信息并添加到结果
label_idx = self.label_map[obj['category_id']] - 1
final_box.append(label_idx)
res += [final_box]
else:
print("no bbox problem!")
return res # [[xmin, ymin, xmax, ymax, label_idx], ... ]
然后定义数据加载类,相应内容同上。
class COCODetection(data.Dataset):
def __init__(self, root, target_transform=COCOAnnotationTransform()):
# 图像数据集根目录
self.root = osp.join(root, 'train2017')
# 参数为标注文件路径,返回COCO类的对象
self.coco = COCO(osp.join(root, 'annotations', 'instances_{}.json'.format('train2017')))
# 获取每张图片的索引,同时将图片索引与标注信息相关联
self.ids = list(self.coco.imgToAnns.keys())
# 调用解析类
self.target_transform = target_transform
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
# 返回数据
return im, gt
def __len__(self):
return len(self.ids)
def pull_item(self, index):
# 获得图像索引
img_id = self.ids[index]
# 获得指定图像索引的标注信息,返回一个列表,列表的每一个值表示一个目标的标注信息
ann_ids = self.coco.getAnnIds(imgIds=img_id)
# 根据标注信息的索引返回其具体的标注内容
target = self.coco.loadAnns(ann_ids)
# 获得图像的完整路径
path = osp.join(self.root, self.coco.loadImgs(img_id)[0]['file_name'])
assert osp.exists(path), 'Image path does not exist: {}'.format(path)
img = cv2.imread(path)
# 解析标注信息
height, width, _ = img.shape
if self.target_transform is not None:
target = self.target_transform(target, width, height)
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
4. 总结
我们在编写完数据加载类后,就可以通过如下方式使用,我们以上述COCODetection类为例。
cocoDetection = COCODetection(root=root)
# 117266,即训练集的图像数目
print(len(cocoDetection))
# 获取指定索引的图像的返回信息,如下图
print(cocoDetection[index])

如上图,第一个tensor是图像的像素值;第二个tensor是目标检测的标注信息,这里边界框的坐标进行了归一化。
由以上两种格式的数据集的加载流程,我们可以得到: V O C {\rm VOC} VOC数据集的标注格式更加清晰易懂,且加载过程仅调用 P y t h o n {\rm Python} Python中的各 A P I {\rm API} API就可以实现;而 C O C O {\rm COCO} COCO数据集的标注信息由于在一个文件内完成,所以难以产生直观的理解。但在面临大规模的数据集时,如 C O C O 2017 {\rm COCO\ 2017} COCO 2017数据集, C O C O {\rm COCO} COCO格式的数据集更加节省标注文件所占用的空间,且可以在一定程度上加快标注信息的加载。但在制作自己的数据集时,为了方便理解和操作,尽量使用 V O C {\rm VOC} VOC格式。 同时,我们也可以使 C O C O {\rm COCO} COCO格式的数据集和 V O C {\rm VOC} VOC格式的数据集之间实现相互转化,具体的内容本人还没有研究过,这里就不做介绍了。
以上两种格式的数据集的加载程序可以作为目标检测中的通用程序。而在数据预处理中,为了增强训练模型的鲁棒性,我们通常还会加上数据增强操作,后文将继续介绍目标检测中的数据增强操作。
参考
- https://github.com/amdegroot/ssd.pytorch.
- http://cocodataset.org/#home.