什么是数据结构?
数据结构就是计算机存储和组织数据的方式
- 基本用途:组织数据
- 常见操作:插入、删除、排序、搜索、遍历等
- 不同的数据结构,适合解决不同的问题
每种结构要了解什么知识点
- 用途与定义 eg. HashSet可以用来查看
- 常见功能及复杂度 eg. BST查找元素复杂度O(log(N))
- 实现原理 e.g. HashMap的冲突解决策略: Linear Probing / Separate Chaining
- 注意事项 e.g. 翻转链表(Iterative/Recursive)
- 语言细节 e.g. Java中heap是用什么class实现的?
Big O
一种算法有多“快”?
某种数据结构或算法所支持的操作,有其时间、空间上的“效率 “。我们用时间/空间复杂度这个概念来衡量它。
时间复杂度,是指算法运行时间与输入数据量的函数关系,常用 大写字母O表示,读作Big Oh。
类似地,空间复杂度,是指算法运行空间与输入数据量的函数关 系。
复杂度不仅有Big O一种表达方式,Big O最常见。 详参《算法导论》
常见时间复杂度种类
- O(1) 表明算法运行时间不随输入数据量增长而变化,一直保持恒定。 e.g. HashSet/HashMap的contains(E elem)方法
- O(N)
表明算法运行时间与输入数据量增长呈线性相关。 e.g. Unordered Array的查找。 - O(logN)
表明算法运行时间与输入数据量增长呈对数关系:k^x = N。
e.g. Heap的pop操作。该复杂度常见于平衡的树结构操作或二分查找,即“一次去掉一半“。 - O(N^2) 表明算法运行时间与输入数据量增长呈平方(Quadratic)关系。 e.g. for...for...; Bubble Sort
5. O(NlogN)
通常出现于O(log N)操作执行了N次,或O(N)操作执行了log N次。 e.g. HeapSort, MergeSort - O(2^N)
较低效,应当尽力避免。
e.g. 斐波那契数列的递归实现。
public int Fibonacci(n) {
if (n == 1 || n == 2)
return 1;
if (n > 2)
return Fibonacci(n-1) + Fibonacci(n-2);
}
- O(N!) 比指数时间更低效,应当避免。 e.g. Permutation
Big O 注意事项
- BigO表示函数关系,是相对量,不是绝对量
e.g. 时间复杂度数量级小,不等于绝对速度在任何情况下都更快,只表明运行时间随
输入数据量的变化速度较慢或不变。 - 只取变化量最大的关系,省略其他
e.g. O(N^2 + 2*N)等同于O(N^2) - 通常取最坏情况
e.g. 假设在队列头部插入,而非中部或尾部
e.g. 平均情况? “一般是在哪里插入” - O(N!)比指数复杂度更低效
线性结构
Array
数组是一种按照线性的顺序来组织固定数量 (fixed amount)的数据的数据结构。
数组所储存的单个数据称为数组的元素(element)
Java中,Array只能装一种元素,但可以是primary type,也可以 是object。
注意事项:
- Fixed size, not dynamic
注意防止溢出 - No holes:无洞性
删除后必须把后面的元素向前移,插入同理
复杂度
| Tables | Are | Cool |
| ------------- |:-------------:| -----:|
| col 3 is | right-aligned | $1600 |
| col 2 is | centered | $12 |
| zebra stripes | are neat | $1 |
| 操作 | 时间复杂度 |
|---|---|
| 插入/删除(原地) | O(N) |
| 搜索(未排序) | O(N) |
| 搜索(已排序) | O(log N) |
| 定位 arr[1] | O(1) |
| 遍历 | O(N) |
| 排序 | O(N log N) |
ArrayList
Dynamic array 既能完成数组线性储存、管理、常数时间 内定位数据的功能,又可以自动调整数组长度。
Java中,这一功能由ArrayList来实现。
复杂度
| 操作 | 时间复杂度 |
|---|---|
| 插入/删除(原地) | O(N) |
| 插入/删除(动态) | Enabled, O(N) |
| 搜索(未排序) | O(N) |
| 搜索(已排序) | O(log N) |
| 定位 arr[1] | O(1) |
| 遍历 | O(N) |
| 排序 | O(N log N) |
复杂度同Array,不同点是支持动态插入删除
| 操作 | 时间复杂度 |
|---|---|
| 插入/删除(原地) | O(N) |
| 插入/删除(动态) | Enabled, O(N) |
| 搜索(未排序) | O(N) |
| 搜索(已排序) | O(log N) |
| 定位 arr[1] | O(1) |
| 遍历 | O(N) |
| 排序 | O(N log N) |
扩容公式
New Capacity = max(新arraylist的最小长度,原 arraylist的size * 2)
LinkedList
只要有插入/删除点的引用(指针),即可实现O(1)插入/删除
复杂度
| 操作 | 时间复杂度 |
|---|---|
| 插入/删除(有指针) | O(1) |
| 插入/删除(用index) | O(N) |
| 搜索 | O(N) |
| 定位 | O(N) |
| 遍历 | O(N) |
| 排序 | O(N log N) |
经典题目:翻转链表
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) return head;
ListNode prev = null, cur = head;
ListNode next;
while (cur != null) {
next = cur.next;
cur.next = prev;
prev = cur;
cur = next; }
return prev;
}
Java链表为双向链表,实现类?
Stack
| 操作 | 时间复杂度 |
|---|---|
| 弹出顶部元素 pop | O(1) |
| 放元素至顶部 push | O(1) |
| 查看是否为空 | O(1) |
| 窥看顶部元素 peek | O(1) |
| 搜索 | O(N) |
| 定位 | Disabled |
| 遍历 | O(N) |
栈(Stack)是一种以O(1)复杂度实现LIFO(Last In First Out)功能的线性数据结构
| 操作 | 时间复杂度 |
|---|---|
| 弹出顶部元素 pop | O(1) |
| 放元素至顶部 push | O(1) |
| 查看是否为空 | O(1) |
| 窥看顶部元素 peek | O(1) |
| 搜索 | O(N) |
| 定位 | Disabled |
| 遍历 | O(N) |
Queue
| 操作 | 时间复杂度 |
|---|---|
| 进入队尾 enqueue | O(1) |
| 弹出队首 dequeue | O(1) |
| 窥视队首 peek | O(1) |
| 搜索 | O(N) |
| 定位 | Disabled |
| 遍历 | O(N) |
队列(Queue)是一种以O(1)复杂度实现LIFO(First In Last Out)功能的线性数据结构
| 操作 | 时间复杂度 |
|---|---|
| 进入队尾 enqueue | O(1) |
| 弹出队首 dequeue | O(1) |
| 窥视队首 peek | O(1) |
| 搜索 | O(N) |
| 定位 | Disabled |
| 遍历 | O(N) |
Java中,Queue是一个接口,有多种实现。 常用的初始化方式:
1.LinkedList
2.PriorityQueue(见Heap)
经典题目
1.用Stack实现Queue
2.用Queue实现Stack
Tree
树是节点(node)的集合。这些节点用父子关系来储存元素,其中:根节点没有父节点,其他节点有且只有一个父节点。
树的结构越接近一个链条,各操作就越接近线性结构,就失去了树结构的优势。
常见二叉树:二叉搜索树(Binary Search Tree,BST) 常见多叉树:字典树(Trie Tree,通常为26叉树)
二叉搜索树(Binary Search Tree)
二叉搜索树是一种二叉树,能够按顺序组织元素。 满足以下条件:
- 每一个节点的左子树中的元素,比这个节点的 元素小,或与它相等。
- 每一个节点的右子树中的元素,比这个节点的 元素大,或与它相等。
进行In-Order Traversal时,顺序从小到大。
BST适合用来对元素排序,或维护元素顺序。 大多数关于树的常见面试题目与二叉搜索树有关。
二叉搜索树可分为平衡树(Balanced Tree)与非平衡树。 “平衡”指树形相对“扁平”。如AVL树:父节点的左右子树均为平衡树,且高度 之差<=1。
“自平衡树”:时刻维持树的平衡。不同自平衡树有不同的自平衡策略。AVL是一种常见的自平衡二叉查找树,当AVL检测到不平衡的状况出现,它会旋转树节点,使得树重新平衡。
为何要区分平衡树与非平衡树? 为保证插入、删除、搜索的最坏时间复杂度不高于O(log N)
AVL平衡二叉树,插入、删除、搜索时间复杂度为O(logN),遍历为O(N)
树的遍历:
1.Depth-First Search
1.Breath-First Search
二叉树题目总结
AVL tree VS Red-Black Tree
The AVL trees are more balanced compared to Red Black Trees, but they may cause more rotations during insertion and deletion. So if your application involves many frequent insertions and deletions, then Red Black trees should be preferred. And if the insertions and deletions are less frequent and search is more frequent operation, then AVL tree should be preferred over Red Black Tree.
Red-Black Tree
Graph
“图”(Graph):节点的集合 + 连接这些节点的边的集合。 在图论中,树(Tree)是一种无向图(Undirected Graph),其中任意两个顶点间存在唯一一条路径。或者说,只要没有环(cycle)的连通图(亦即没有岛island)就是树。
Heap
Heap是一种逻辑结构为树形,物理结构为线性的数据结构,它的主要功能是维护及提供最小或最大元素(依此分为最小堆和最大堆)。
- 近完全的树形结构(almost complete Tree):除最后一层外,每层都维持“满节 点”状态。添加元素时,从左到右依次添 加。
- 根节点存放最小(或最大)元素。
-
对每个节点而言,其子节点的元素值都比自己小(或大)。
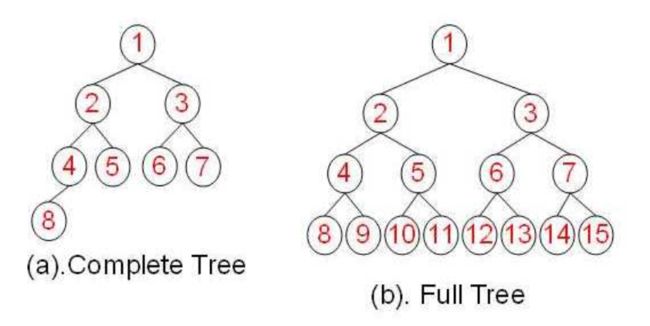 image.png
image.png
物理结构
为什么说Heap的物理结构是线性的?
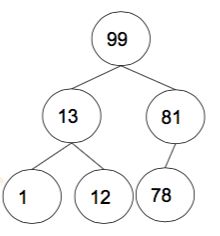
[0,99,13,81,1,12,78]
1.对于任意一个index为k的节点:
- 其父节点的index:k/2
- 其左孩子的index:2*k
- 其右孩子的index:2*k+1
2.index为0的位置要空出来
建堆
逐个offer法 O(NlogN)
逐层扫描法 O(N)
重点
- 用途是维护和提供最大最小值,但不负责完整排序。
- 物理线性,逻辑树形(近完全树)。
- 两个操作:弹出最值和加入新元素,复
杂度都是O(log N)。 - 建堆时间可以优化到O(N)。
- 非叶节点index:1 - n/2。
- Java中可直接调用PriorityQueue类使用其功能。
Set/Map
冲突问题(Collision)
不同的key形成了同一个hash码
为何会有冲突问题
- 哈希函数的特性。e.g.“均匀哈希函数”(Uniform Hash function)
- 存储位置比较少
冲突问题如何解决?
- Separate Chaining(链接法)
- 以每个bucket内的Entry object为head node,将不同的entry连缀起来形成 LinkedList。(即每个bucket是一个链表,可以动态增删)
- 插入时,查找一遍已存在的LinkedList,如果有相同的key则更新其value;如果没有, 则插入到bucket首位。
- 删除、查找时同理。
- Linear Probing(线性探查)
定义
Map是一种为“Key-value pair” 提供存储、查找、替换、遍历等功能的数据结构。
实现方式

- HashMap is implemented as a hash table, and there is no ordering on keys or values.
- TreeMap is implemented based on red-black tree structure, and it is ordered by the key.
- LinkedHashMap preserves the insertion order
- Hashtable is synchronized, in contrast to HashMap. It has an overhead for synchronization.
- This is the reason that HashMap should be used if the program is thread-safe.
参考:四种基本实现
根据常见实现方式可以分为: HashMap, TreeMap, LinkedHashMap
- LinkeHashMap: HashMap + LinkedList, 可以保存输入的顺序
Application: LRU Cache - TreeMap:HashMap + 红黑树(自平衡的BST),可以针对可排序的key进行排序,key为自定义对象是必须实现Comparable接口
- HashTable:The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls. HashTable的所有接口都是synchronized
- HashMap提供了最快的查找技术,也没有按照任何明显的顺序来保存元素。TreeMap按照比较结果的升序保存键,而LinkedHashMap则按照插入顺序保存键,同时还保留了HashMap的查询速度。
如果Map的key是自定义对象,需要自己实现equals() 和 hashCode(),否则会使用默认的equals() 和 hashCode()
The default hashCode() method gives distinct integers for distinct objects, and the equals() method only returns true when two references refer to the same object.
Set(集合)
主要用途: 查找(查重)
实现方式
根据实现方式也分为: HashSet, TreeSet,LinkedHashSet
HashSet提供了最快的查找技术,存储的顺序没有实际的意义。TreeMap按照比较结果的升序保存对象,而LinkedHashMap则按照插入顺序保存对象。
底层结构:
- 用一个HashMap来实现,但value部 分用dummy object,只保留key
- 存储和查找原理与HashMap完全一致
- 如果重复,和HashMap一样会替换,但因为value都是dummy