调研:暴恐识别(图像识别)by_xxzcc
调研:暴恐识别
一、方法:分类、目标检测、人体姿态分析
1、腾讯优图:(接口:https://ai.qq.com/doc/imageterrorism.shtml)
图片分类(属性):13类
terrorists:恐怖分子; normalarmy:普通军;knife:刀;guns:枪;
blood:血;fire:火;flag:旗帜;crowd:人群;ship:船;aircraft:飞机;
cannon:大炮;armoredcar:装甲车;other_weapon:其他武器
腾讯优图暴恐识别结果:

2、百度暴恐识别:
图片分类:
粗分:2类,正常和暴恐
细分:12类
正样本:正常;警察部队 (共两类)
负样本:血腥;尸体;爆炸火灾;杀人;暴乱;恐暴人物;军事武器;暴恐旗帜;血腥动物动物尸体;车祸 (共10类)
3、关键点检测:(人体姿态)
根据人的14个关键点,然后计算视频或者图片中是否有暴力情况发生。
缺点:可能关键点较多,在人多的时候检测会较慢。

4、其他:
场景分类:分为7类
正常;特殊着装人物(军队,警察等);
特俗符号;武器或者武器持有者;血腥场景;暴乱场景;战争场景
二、数据:
1. 数据 Real Life Violence Situations Dataset
说明:1000个暴力行为视频如打架斗殴, 1000个非暴力视频如吃饭,行走等
链接: https://www.kaggle.com/mohamedmustafa/real-life-violence-situations-dataset
论文:《Violence Recognition from Videos using Deep Learning Techniques》——2019
样例:打架视频

2. 数据 Gun Violence Data
说明:全面记录260k 起发生在2013-2018年美国的枪支暴力事件,有详细信息,csv格式
链接:https://www.kaggle.com/jameslko/gun-violence-data
3. 数据 Gun Violence Database
说明:从2000个媒体收集到的枪支暴力数据,包括儿童和青少年受伤死亡,以及大量枪击事件
链接:https://www.kaggle.com/gunviolencearchive/gun-violence-database
4.RWF-2000: An Open Large Scale Video Database for Violence Detection
说明:是1中的加强版
链接:https://github.com/mchengny/RWF2000-Video-Database-for-Violence-Detection 需要申请
三、部分论文
1. 《Violence Recognition from Videos using Deep Learning Techniques》2019
在视频上针对个人或者人群做暴力监督。
方法:
1)VGG-16(Pre-trained on Imagenet)提取特征
2)LSTM 接上层特征然后获取时间特征(即获取图片前后时间语义信息)
3)全连接层接上层信息,最终分类
2. 《RWF-2000: An Open Large Scale Video Database for Violence Detection》——2020
提出了一个新的大型暴力检测数据集,并提供了两个baseline,达到sota
数据:2000个短片共计30w帧数据。(全是监控下面的视频)
数据缺点:由于在现实摄像头下采取,可能出现一些图片有以下缺点:
1)视野的一小部分有人
2)视野下很多人
3)离视野远,目标很小
4)光照、清晰度等造成图片质量一般
5)部分暴力事件很短暂(比如20帧里面只有2帧是暴力)
样例demo:

四、部分代码
1. 代码:Violence Detection_CNN_LSTM (Keras + Tensorflow)
链接:https://github.com/liorsidi/ViolenceDetection_CNNLSTM (Tensorflow)
链接:https://github.com/swathikirans/violence-recognition-pytorch(Pytorch)
框架:多帧图片喂到ResNet50(Pre-trained), LSTM接多帧图片得出的feature_map,最终得到的特征过FC层然后进行分类。

2. 代码: Violence Detection
链接:https://github.com/JoshuaPiinRueyPan/ViolenceDetection (Tensorflow)
框架:基本同上
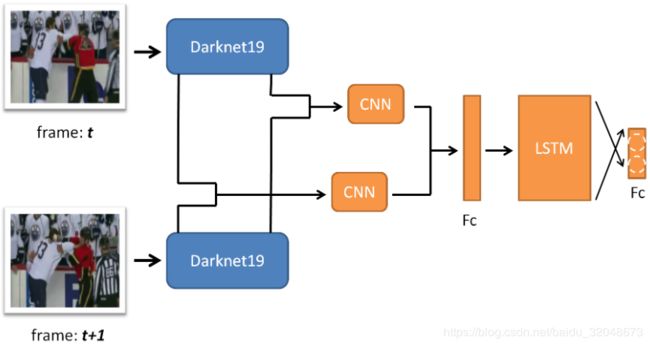
3.代码:Protest Detection and Violence Estimation
链接:https://github.com/wondonghyeon/protest-detection-violence-estimation (Pytorch)
论文:Protest Activity Detection and Perceived Violence Estimation from Social Media Images
图片:40764, 抗议图片:11659
可以认为是对目标图片进行分类+暴恐打分(从做往右程度越来越重)

总结:感觉对于视频来说可以采用 CNN+LSTM增加判断的准确性。对于单图片来说可以用CNN分类来做。