AAAI 2020 开源论文 | 用于深度立体匹配的自适应单峰匹配代价体滤波

©PaperWeekly 原创 · 作者|张承灏
学校|中科院自动化所硕士生
研究方向|深度估计
本文介绍北航和深动科技在 AAAI 2020 上的论文 Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching,他们在这篇工作中提出给匹配代价体(cost volume)添加自适应单峰分布的真值信息来监督,从而提升立体视差估计的准确率。

论文链接:https://arxiv.org/abs/1909.03751
源码链接:https://github.com/DeepMotionAIResearch/DenseMatchingBenchmark
立体匹配是一个经典的计算机视觉任务,传统方法主要基于滑动窗口来计算匹配代价。基于深度学习的方法将视差估计视为回归问题,这些模型都只在网络的最终结果上计算损失函数,即预测的视差值与真实视差值的误差。它们忽略了视差回归的中间产物——匹配代价体在学习中容易产生过拟合,因为匹配代价体是没有监督信息的。
针对这个问题,作者提出直接给匹配代价体增加在真值附近的单峰约束,并且设计了置信度估计网络来生成单峰分布的方差,用以表示模型在不同纹理区域下匹配的不确定性。截止 2019.08.20,论文提出的模型 AcfNet 在 KITTI 2012 公开榜单上排名第一,在 KITTI 2015 上排名第四。

研究背景
立体匹配算法分为四个步骤:匹配代价计算,代价聚合,视差回归和视差精修。其中,匹配代价的计算是至关重要的一步。根据匹配代价计算方式的不同,可以将基于深度学习的视差估计算法分为两类。
1. 基于相关性的匹配代价计算。以 DispNetC [1] 为代表,利用相关层对左右图像的特征计算匹配代价,构造 3 维的匹配代价体,最后使用 2D 卷积回归视差图。iResNet [2] 通过引入堆叠的精修子网络进一步提升了性能。
2. 基于 3D 卷积的匹配代价计算,以 GC-Net [3] 为代表,通过将左右图的特征体进行连接来构造 4 维的匹配代价体,最后使用 3D 卷积和可导的”winner takes all (WTA)”策略来得到视差图。基于此改进的 PSMNet [4] 和 GANet [5] 等模型是目前性能较好的网络。
本文属于第二类方法,基于 PSMNet 对匹配代价体增加自适应的单峰滤波约束,从而使得预测的代价匹配体在真值附近能够得到和真值一致的分布,如图 1 所示。第 1、3 行分别是 PSMNet 和 AcfNet 预测的代价分布,第 2、4 行分别是真值的代价分布。PSMNet 在真值附近生成了两个最小值的峰值,这与真值的分布不符合。而本文的 AcfNet 在真值附近生成了正确的分布。

▲ 图1. 沿匹配代价体的视差维度展示的代价分布情况

论文方法
方法概述(Overview)
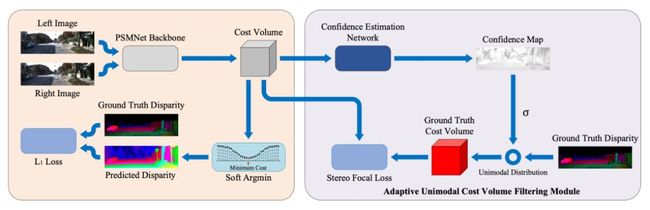 ▲ 图2. AcfNet的整体框架图
▲ 图2. AcfNet的整体框架图
图 2 是 AcfNet 的整体框架图。论文在 PSMNet 的基础上,提出自适应单峰匹配代价体滤波,它作用于匹配代价体上。匹配代价体一方面通过 CENet 得到置信图,结合真值视差形成对匹配代价体进行监督的单峰分布,另一方面通过 soft argmin 来预测视差。
在匹配代价计算中,可能的视差分布是 {0, 1, ..., D-1},那么构建得到的匹配代价体的大小即为 H×W×D(高度×宽度×最大视差值)。形式上,对每个像素包含 D 个代价的匹配代价体定义为  ,那么每个子像素估计的视差可以通过 soft argmin 得到:
,那么每个子像素估计的视差可以通过 soft argmin 得到:
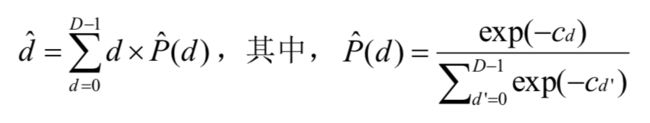
将每个子像素预测的视差和真值视差做 smooth L1 loss 使得整个网络模型是可导的,可以进行端到端的训练。
然而,这种监督信息还是不够完善的,可能有无数种模型权重来实现正确的插值结果。中间产物代价匹配体由于其灵活性很容易过拟合,因为许多学习不正确的匹配代价体可能会插值接近真实的视差值。为了解决这个问题,根据匹配代价体的单峰特性,直接对其进行监督。
单峰分布(Unimodal distribution)
匹配代价体是用来反映候选匹配像素对之间的相似性的,因此真实的匹配像素对应该具有最小的代价,这反映出在真值视差的附近应该是单峰分布的,这种单峰分布可以定义为:
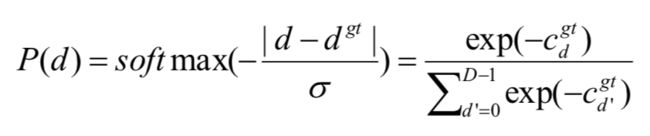
这里的 σ 是方差,用来控制分布在峰值附近的尖锐度。但是这样构造的真实匹配代价体并不能反映不同像素之间的相似性分布差异,比如桌角上的像素应具有非常尖锐的峰,而均匀区域中的像素应具有相对平坦的峰。为了为代价匹配体构建更合理的监督信息,作者设计了一个置信度估计网络以自适应地预测每个像素的 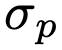 。
。
置信度估计网络(Confidence estimation network, CENet)
CENet 实际上是由两个卷积层构成,第一层是带有 BN 和 ReLu 的 3×3 卷积,第二层是带有 sigmoid 激活的 1×1 卷积用来生成置信图 。再经过尺度缩放得到最终的真值匹配代价体监督信息:

这里非负的 s 反映的对置信度 ![]() 的敏感性的比例因子,正数 ε 定义
的敏感性的比例因子,正数 ε 定义 ![]() 的下界,避免了除以 0 的数值问题。由于置信度越高,其对应的匹配代价体就应该越低,所以 和
的下界,避免了除以 0 的数值问题。由于置信度越高,其对应的匹配代价体就应该越低,所以 和 ![]() 是成反比的, 的范围在 [ε,s+ε]。消融实验表明 s=1, ε=1 能取得最好的性能。论文中最终的结果也表明,置信度低的区域就是纹理较弱和难以匹配的遮挡区域。
是成反比的, 的范围在 [ε,s+ε]。消融实验表明 s=1, ε=1 能取得最好的性能。论文中最终的结果也表明,置信度低的区域就是纹理较弱和难以匹配的遮挡区域。
立体焦点损失(Stereo focal loss)
预测的匹配代价体和真实的匹配代价体之间存在严重的样本不均衡,因为对每一个像素点来说只有一个视差值是正确的,这是一个正样本,其余的均为负样本。因此,作者参照用于目标检测的 focal loss,设计了 stereo focal loss。
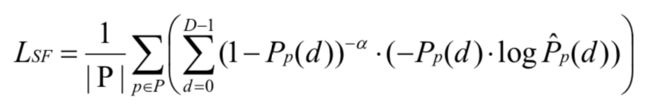
其中 α=0 时与交叉熵损失一样;α>0 时给视差正样本赋予更多的权重。消融实验表明比标准的交叉熵损失性能要好。
最终的损失函数由三部分构成,一是 stereo focal loss;二是预测视差和真实视差的回归损失;三是 CENet 得到的置信度的损失,其表示如下:
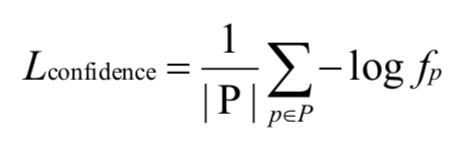

实验结果
作者在立体匹配的主流数据集 Sceneflow,KITTI 2015,KITTI 2012 上进行实验,从表 1 可以看到 AcfNet 的性能成为新的 state-of-the-art。图 3 中最右边两列可以看到误差图和置信图很好的对应起来,说明 AcfNet 可以给予具有丰富信息的像素较高的置信度,同时防止信息较少的像素过拟合。图 4 在 KITTI 15 上的可视化结果表明 AcfNet 在细节信息上优于以往 SOTA 模型。
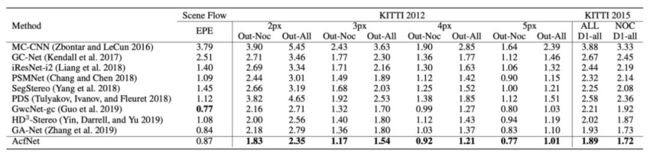
▲ 表1. AcfNet在Sceneflow,KITTI 2015和KITTI 2012上的性能
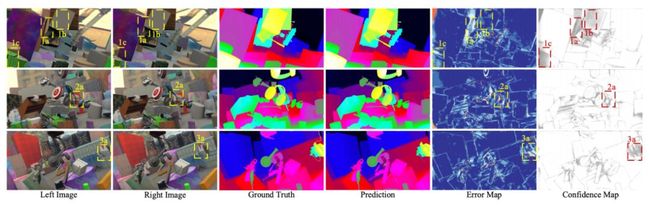
▲ 图3. Sceneflow数据集上的可视化结果
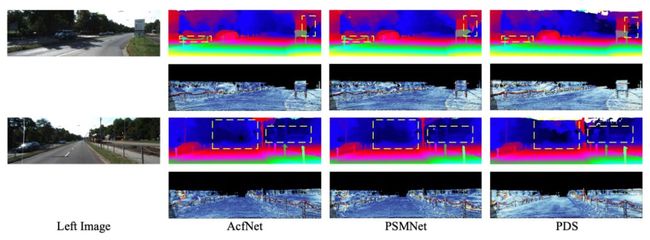
▲ 图4. KITTI 2015数据集上的可视化结果

评价与思考
本文的创新点比较新颖,关注的是以往被忽略的匹配代价体的监督问题,从理论上得出匹配代价体的分布是单峰分布。作者所提出的 CENet 和 stereo focal loss 也直观而有效。行文写作简洁明了,值得学习。
立体匹配方法最大的难点是缺少泛化性能,本文对匹配代价体的概率分布施加约束,能够作为辅助的监督信息,适用于多种基于匹配代价体的立体匹配方法。

参考文献
[1] Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4040–4048 (2016)
[2] Liang, Z., Feng, Y., Guo, Y., Liu, H., Chen, W., Qiao, L., Zhou, L., Zhang, J.: Learning for disparity estimation through feature constancy. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2811–2820 (2018)
[3] Kendall, A., Martirosyan, H., Dasgupta, S., Henry, P.: End-to-end learning of geometry and context for deep stereo regression. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 66–75 (2017)
[4] Chang, J.R., Chen, Y.S.: Pyramid stereo matching network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5410–5418 (2018) [5] Zhang, F., Prisacariu, V., Yang, R., Torr, P.H.: Ga-net: Guided aggregation net for end-to-end stereo matching. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 185–194 (2019)

点击以下标题查看更多往期内容:
深度学习模型不确定性方法对比
神经网络中的常用激活函数总结
基于无标签单目视频序列的单帧三维人体姿态估计
通过多标签相关性研究提升神经网络视频分类能力
ICCV 2019 | 适用于视频分割的全新Attention机制
视频预测领域有哪些最新研究进展?
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文 & 源码