Waymo 2020 | 2D/3D目标检测、跟踪和域自适应性冠军解决方案解析

©PaperWeekly 原创 · 作者|黄飘
学校|华中科技大学硕士
研究方向|多目标跟踪
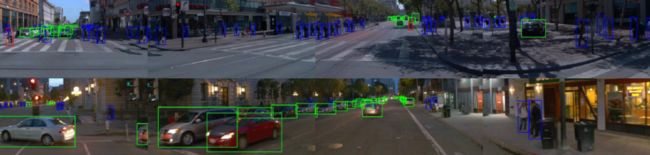
随着最近 Waymo Open Dataset Challenges 2020 的落幕,其中关于 2D/3D 目标检测和跟踪赛道的部分冠亚军解决方案也都公布了,由于我只看到了地平线发布的论文,所以就只分析他们公司在这次比赛中的解决方案。
PS:地平线在 Waymo 2020 中获得了 3D 检测、2D/3D 跟踪和域自适应性赛道冠军,2D 检测赛道亚军。

HorizonDet

论文标题:2nd Place Solution for Waymo Open Dataset Challenge - 2D Object Detection
论文链接:https://arxiv.org/abs/2006.15507
一般检测竞赛的算法技术报告中,榜前的方法都是各种算法 ensemble 的,比如多种检测算法结合,又比如多种 nms 方式的结合等。
 1.1 模型选择
1.1 模型选择
地平线这次在 Waymo 2020 的 2D 检测赛道获得了第二名,也同样用到了模型 ensemble 的方式。对于检测算法,他们团队考虑到两阶段算法和单阶段 anchor-free 算法在检测结果多样性方面的互补,以及 anchor-free 算法在拥挤、小目标场景下更好的效果,选用了 Cascade R-CNN 和 CenterNet 的结合。
其中 CenterNet 部分,采用了两组 Hourglass104 网络作为 backbone,其中第一组的输出只在训练的时候为提供 auxilliary loss,具体见下图。
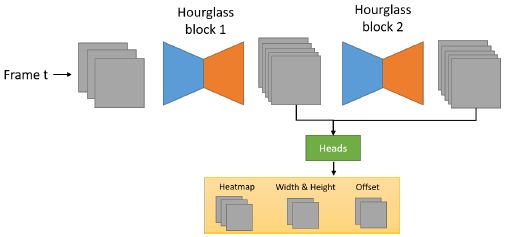
1.2 训练策略
另外,还引入了 AAAI 2020 中针对 CenterNet 这类算法框架提出的训练策略改进 TTF [2],为了提供更多高质量的正样本。由于 CenterNet 所采用的高斯核只考虑了中心点和与之距离的因素,在 x,y 方向共用一组标准差,生成了圆形的高斯 mask:

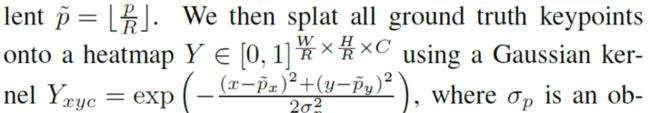
而 TTF 中则是考虑到了目标的 aspect ratio,提出了多样的标准差:

上述的这种只是对中心点回归训练的改进,接下来是对目标框宽高的回归的改进。原始的 CenterNet 假设预测得到的中心点绝对准确,所以可以通过宽高得到最终的目标框。但是 TTF 默认预测得到中心点不一定准确,所以预测的是中心点距离两个角点的 offset:

对于 anchor 的设定则是在原始的 0.5,1,2 基础上,考虑到车辆,加入了 0.25 和 0.75 两种 aspect ratio。与此同时,考虑到部分标注错误,还加入了 label smoothing。
1.3 模型ensemble
接下来就是模型 ensemble了,除了 Cascade RCNN 和 CenterTrack 的结合,还考虑到了不同尺度输入策略(对于前者选取了 0.8,1.0,1.2 三种尺度,对于后者选取了 0.5,0.75,1,1.25,1.5 五种尺度),当然还有不同训练代数、策略下不同的模型,还有不同后处理的结果。
作者团队将不同检测框架和不同推理策略进行组合,通过二叉树来构建贪婪式的自动 ensemble 框架:

每组模型的评价由验证集上的 mAP 指标为准,模型结果的融合则是基于不同的 nms 处理方式,这里作者用了五种后处理方式:
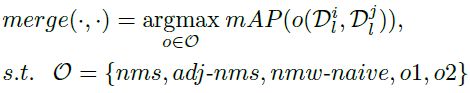
其中第二种 adj-nms 指的是商汤在 OpenImage 2019 上的提出的方案:

即先用传统的 NMS,再用 Soft-NMS。第三种 NMS 指的是 ICCV 2017 workshop 上的一篇论文提出的方法:

即对于当前选择的置信度较高的候选框,基于其周围候选框与其的 iou 和各自的类别置信度信息对候选框进行加权融合,有点像 softer-nms。对于后两种后处理即直接取第一种模型或者第二种模型。
结果如下:
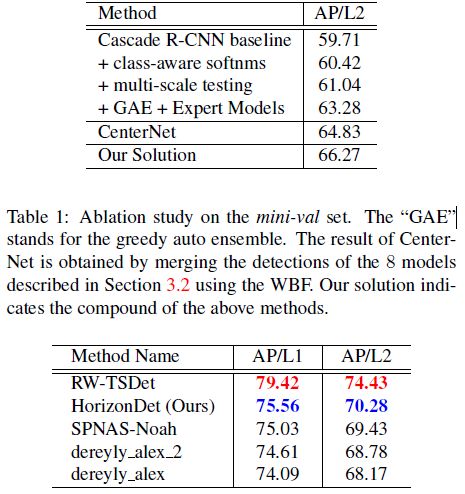
这里面的 GAE 就是模型 ensemble,Expert Models 指的是只用白天、夜晚等场景下的数据进行训练。

AFDet

论文标题:AFDet: Anchor Free One Stage 3D Object Detection
论文链接:https://arxiv.org/abs/2006.12671
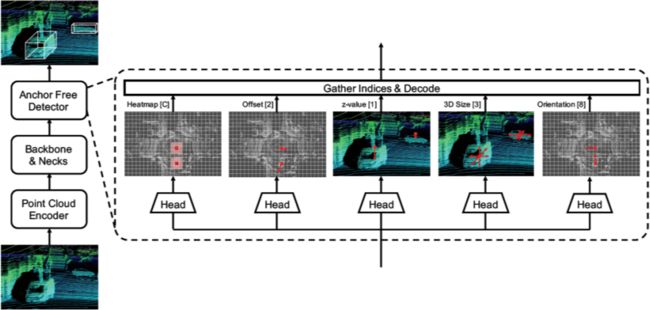
AFDet 是地平线这次 3D 检测竞赛的 baseline 算法,在 CVPR2020 Workshop 上报告过,从算法流程图可以知道的 AFDet 由点云编码器、骨干网络和检测器三部分构成。其中点云编码器部分采用的是 CVPR2019 的一篇论文中提出的 PointPillars 算法:
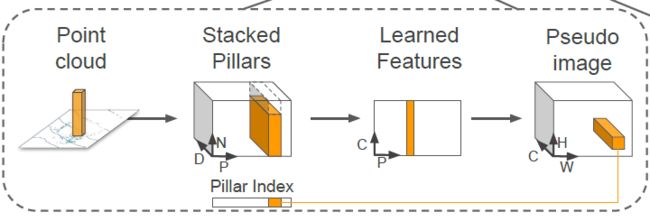
其首先基于鸟瞰图将原始空间划分为 HxW 的网格区域,那么每个点都存在有:
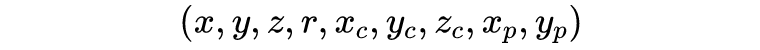
9 个维度的特征。其中前三个为每个点的真实位置坐标,r 为反射率,带 c 下标的是该网格内所有点的均值,带 p 下标的是对点相对于网格中心的偏差。
然后取 P 个非空网格区域,每个区域取 N 个点,多的话就采样,少的话就补 0,D 代表特征维度 9,因此就得到 DxPxN 的 tensor。然后利用线性层进行特征转换得到 CxPxN 的 tensor,紧接着利用取最值的操作得到 CxP 的 tensor,即每个非空网格区域对应一组特征。
最后根据网格位置映射到 HxW 空间,得到 CxHxW 的 tensor,从而可以使用二维卷积的策略进行进一步特征学习。
其 backbone 部分网络结构如下:
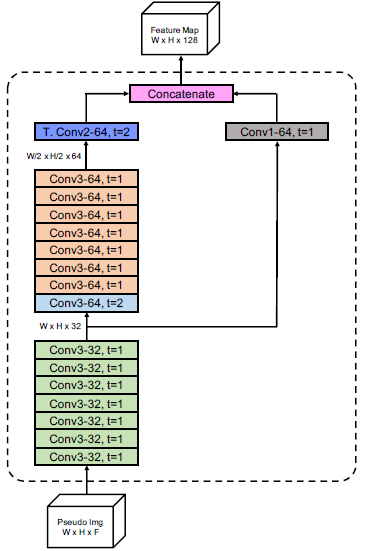
在检测器部分,作者团队采用的是 anchor-free 的检测框架,其回归预测部分包含有 5 个分支:
目标定位(heatmap、offset 和 z 方向定位):
这部分类似于 centernet,中心点的标签是依据点到预设网格点的归一化后的 offset 确定的,而 heatmap 则是采用的:

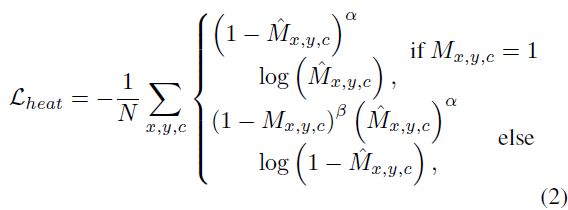
而 offset 的损失计算则引入了一个围绕中心点的正方形区域,用来缓和微小的定位误差:
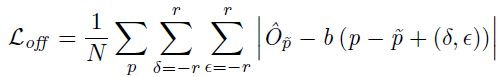
其中 b 是网格区域的 size,r 是正方形的 size,通过一个方形区域的设定,当中心点位置刚好正确,那么误差最小,如果中心点位置稍微发生偏移则会增大误差。z 方向的回归采用的是 L1 Loss。
框的尺寸回归:
这部分就是长宽高的回归,同样采用 L1 Loss。
方向回归:
这里的方向是绕 z 轴的角度,设定了两个 bin,分别是 [-7π/6,π/6] 和 [-π/6,7π/6],每个 bin 有四个变量,两个用作 softmax 分类,两个用作角度回归。其中分类是判定属于哪种 bin,角度回归是相对于 bin 中心的 sin 和 cos 偏差。

在推理阶段,通过 max pooling 等操作取峰值,从而避免使用 NMS。
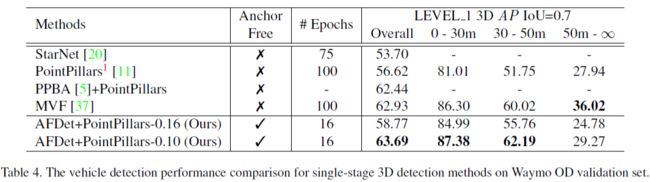
结果如下:

HorizonLiDAR3D

论文标题:1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
论文链接:https://arxiv.org/abs/2006.15505
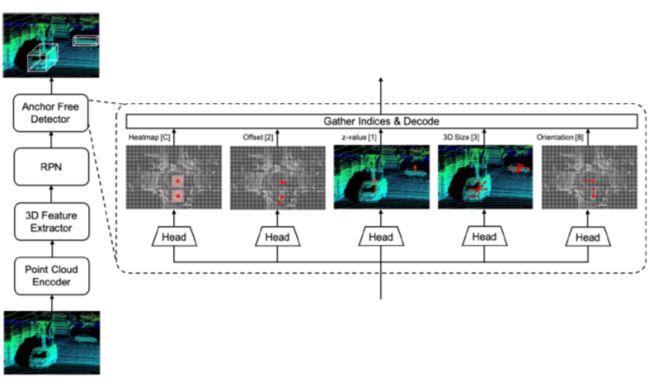
可以看到,HorizonLiDAR3D 检测框架跟 AFDet 基本一样,区别就在于,这个是用来参赛的,所以会增加很多 tricks 和 ensemble。其中的点云编码部分跟之前一样,还是编码成了 pseudo image 形式:
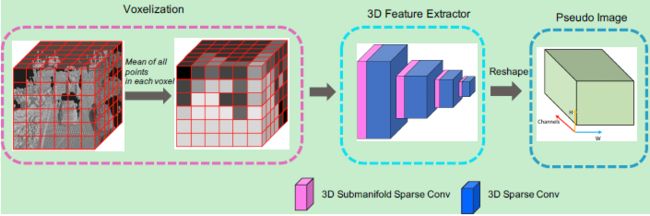
而中间的 backbone 和 necks 部分则是换成了更加复杂的形式,包含有两种 3D 特征提取器和三种 RPN 网络,组合成了三种网络框架:
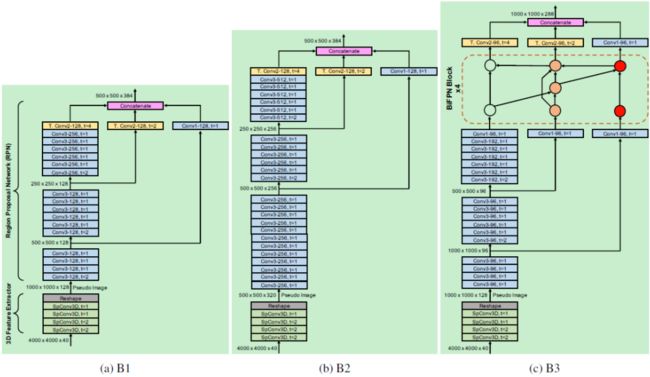
其中 3D 特征提取部分的 SPConv3D 卷积是由几个 submanifold 卷积和一个稀疏卷积层构成 [6],其目的是防止网络稀疏性下降:

可以看到原本稀疏的点在经过卷积之后,逐渐变得模糊,从而使得稀疏性下降,所以采用了稀疏卷积。这里我没有具体到相应的论文去研究这种卷积的模式,不过我猜测应该类似于在卷积之后,通过判断每个点的感受野中心是否为上一层的 active 区域,如果是就保留,否则置 0。
在推理阶段,作者团队将前 4 帧的点云信息也一并利用起来,用来增加稠密性,所以输入维度多了一个时间维度。另外团队也充分利用了 Waymo 数据集提供的 5 种 LiDAR sweeps。
在数据增强环节,除了一些基本的平移旋转操作,作者在每帧中加入了 6 个车辆、8 个行人和 10 个自行车,并沿着 z 轴做随机反转。特别地,作者团队借鉴 CVPR 2020 中 Pointpainting 的方式,引入了颜色信息,用来增加类别区分度和更丰富的伪点云信息:
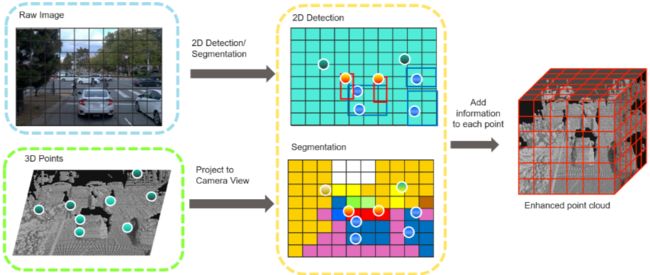
引入 painting 之后的效果好了很多:
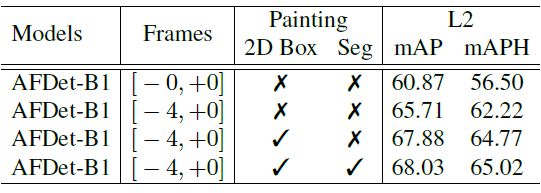
当然,还有一些模型 ensemble,这里我就不再细说了,放最后的结果:
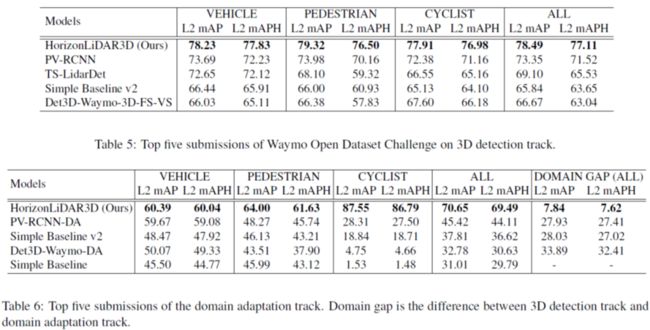

HorizonMOT (2D/3D)

论文标题:1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
论文链接:https://arxiv.org/abs/2006.15506
近期联合检测和跟踪的算法框架很热门,性能也比较好,比如 CenterTrack、FairMOT 等。作者团队也借鉴了这一点,检测框架部分自然就是采用了上面所介绍的 HorizonDet 和 HorizonLiDAR3D,而跟踪分支则是借鉴了 FairMOT 的模式,增加了 reid 分支:
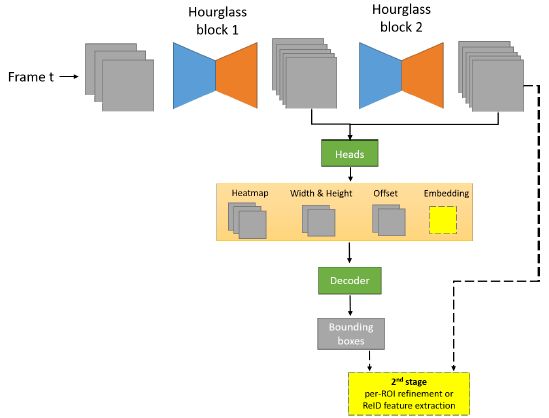
其中虚线部分是尚未来得及在竞赛中使用的部分。跟踪部分假设不使用未来信息,不考虑相机运动,具体如下:
运动模型
这一部分借鉴了 DeepSort 算法,使用了 Kalman Filter 算法,在 2D 跟踪中设定的状态变量是中心坐标、长宽比和高度以及各自的速度变化量。在 3D 跟踪中设定的状态变量为 3D 坐标、长宽高和位置的速度变化量。
表观模型
表观模型的引入主要是为了防止拥挤和轨迹暂时丢失的问题,行人输入为 128x64,车辆输入为 128x128,经过 11 个 3x3 卷积和 3 个 1x1 卷积以及一些 pooling 层得到 512 维向量。
数据关联
数据关联的基础算法是匈牙利算法,这里作者将关联过程分成了三个阶段,与此同时将检测结果按照置信度分成了两份,一份置信度大于 t(s),一份介于 t(s)/2 和 t(s) 之间。
第一阶段的数据关联跟 DeepSort 一样,采用级联匹配的方式,对跟踪框和第一份检测结果进行匹配,也就是先匹配持续跟踪的目标,对于暂时丢失的目标降低优先级;
第二阶段的数据关联会对第一阶段中尚未匹配的跟踪轨迹(丢失时间小于 3)和剩余的第一份检测结果进行匹配,当然也会降低一些匹配阈值
第三阶段的数据关联会对第二阶段尚未匹配的跟踪轨迹和第二份检测结果进行匹配,同样降低阈值标准。
对于不同目标的阈值也是有区别的:
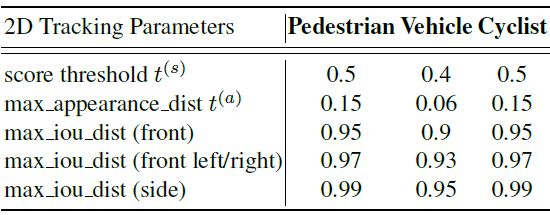
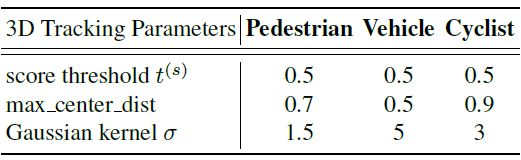
而对于 2D 和 3D 目标的 IOU 距离计算则是:
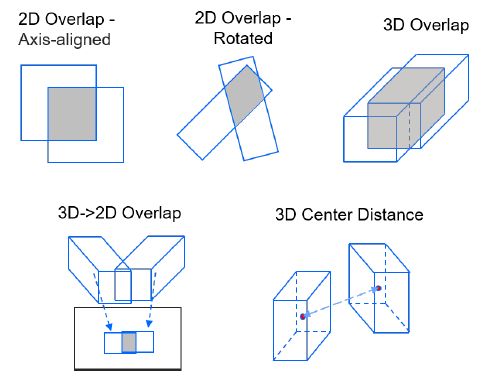
其中 ReID 特征的余弦距离用于第一阶段,而 IOU 距离用于后两个阶段。
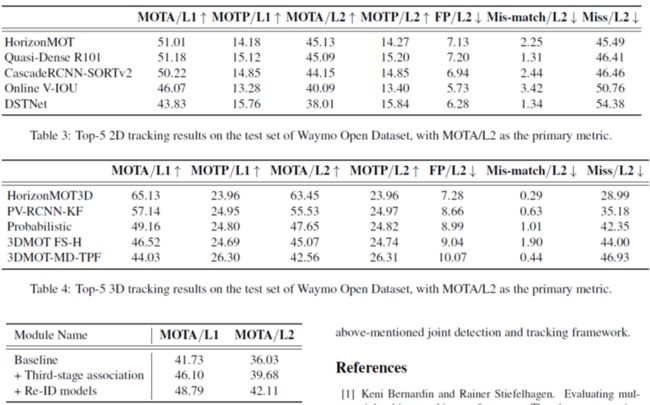
最终的结果如下:
参考文献
[1] 2nd Place Solution for Waymo Open Dataset Challenge - 2D Object Detection
[2] Training-Time-Friendly Network for Real-Time Object Detection
[3] AFDet: Anchor Free One Stage 3D Object Detection
[4] PointPillars: Fast Encoders for Object Detection from Point Clouds
[5] 1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
[6] Second: Sparsely embedded convolutional detection
[7] 1st Place Solutions for Waymo Open Dataset Challenges - 2D and 3D Tracking
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
