性能优化专题十三--BlockCanary简析
Looper 提供的机制
先看看我们熟悉的 Looper 的源码,里面实现的功能就是不断地从 MessageQueue 里面取出 Message 对象,并加以执行。
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// ignore some code...
msg.recycleUnchecked();
}注意到,在 dispatchMessage 的前后,分别有两个 log 的输出事件,而 dispatchMessage 就是线程上的一次消息处理。如果两次消息处理事件,都超过了 16.67ms, 那就一定发生了卡顿,这也是 BlockCanary 的基础原理。
BlockCanary 实现了 Printer,我们看看具体的实现。
class LooperMonitor implements Printer {
@Override
public void println(String x) {
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
// ignore other codes...
}这里实现了 println 方法,而 Looper 中也调用了 println 方法,而且在除非 dump 日志的情况下,也只有在事件消息前后进行 println 操作。换而言之,我们可以初步认为两个 println 调用之间的时间超过 16.67ms 就证明了卡顿。上面的代码也非常地清晰明了说明了这点。
输出堆栈
在发现卡顿时,还需要提供当前线程的堆栈,这样才能方便开发人员知晓在哪里发生了卡顿,而 Java 刚好也提供了类似的机制,代码也非常的简单。
@Override
protected void doSample() {
StringBuilder stringBuilder = new StringBuilder();
for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) {
stringBuilder
.append(stackTraceElement.toString())
.append(BlockInfo.SEPARATOR);
}
synchronized (sStackMap) {
if (sStackMap.size() == mMaxEntryCount && mMaxEntryCount > 0) {
sStackMap.remove(sStackMap.keySet().iterator().next());
}
sStackMap.put(System.currentTimeMillis(), stringBuilder.toString());
}
}BlockCanary 的原理简介就到这里,还是比较轻松和简单的。
BlockCanary卡顿检测流程图
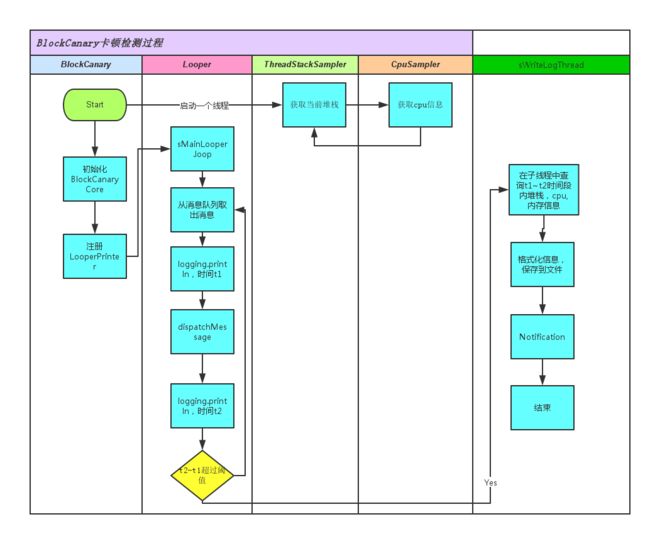
BlockCanary启动一个线程负责保存UI线程当前堆栈信息,将堆栈信息以及CPU信息保存分别保存在 mThreadStackEntries和mCpuInfoEntries中,每条信息都以时间撮为key保存。
BlockCanary注册了logging来获取事件开始结束时间。如果检测到事件处理时间超过阈值(默认值1s),则从mThreadStackEntries中查找T1~T2这段时间内的堆栈信息,并且从mCpuInfoEntries中查找T1~T2这段时间内的CPU及内存信息。并且将信息格式化后保存到本地文件,并且通知用户。
https://lrh1993.gitbooks.io/android_interview_guide/content/java/concurrence/thread-pool.html