VarGFaceNet:地平线提出轻量级、有效可变组卷积的人脸识别网络

作者 | Mengjia Yan、Mengao Zhao、Zining Xu、Qian Zhang、Guoli Wang、Zhizhong Su
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】为了提高用于人脸识别的轻量级网络的判别和泛化能力,本文提出了一种有效的可变组卷积网络,称为VarGFaceNet。VarGNet引入了刻板组卷积,以解决小计算量与块内计算强度不平衡之间的冲突。
作者采用可变组卷积来设计了网络,该网络可以支持大规模人脸识别,同时减少计算成本和参数。具体来说,作者对头部(head)进行设置,用于在网络开始时保留基本信息,并提出特定的嵌入方法以减少用于嵌入的全连接层的参数。
为了提高解释能力,作者采用等效的角度蒸馏损失来指导我们的轻量级网络,并应用递归知识蒸馏来缓解教师模型和学生模型之间的差异。值得一提的是,LFR(2019)挑战赛,deepglintlight赛道冠军证明了本文模型和方法的有效性。

论文地址:
https://arxiv.org/abs/1910.04985v2
VarGFaceNet代码开源网址:
https://github.com/zma-c137/VarGFaceNet
引言
随着计算资源的激增,基于深度表示的人脸识别已广泛应用于监控,营销和生物识别等许多领域。然而,由于需要进行大规模的身份分类,因此在有限的计算成本系统(例如移动端和嵌入式系统)上实现人脸识别仍然是一项艰巨的任务。
许多工作提出了用于常见计算机视觉任务的轻型网络,例如SqueezeNet,MobileNet ,MobileNetV2,ShuffleNet,SqueezeNet。它们大量的使用1×1卷积,与AlexNet 相比,可减少50倍的参数,同时在ImageNet上保持AlexNet级别的准确性。
MobileNet 利用深度可分离卷积来实现计算时间和准确性之间的权衡。基于这项工作,MobileNetV2 提出了一种倒置的bottleneck结构,以增强网络的判别能力。
ShuffleNet 和ShuffleNetV2 使用逐点组卷积和通道随机操作进一步降低了计算成本。即使它们在推理过程中花费很少的计算并在各种应用程序上有良好的性能,但嵌入式系统上的优化问题仍然存在于。
为了解决这个冲突,VarGNet 提出了一个可变组卷积,可以有效地解决块内部计算强度的不平衡。同时,作者探索了在相同卷积核大小的情况下,可变组卷积比深度卷积具有更大的学习能力,这有助于网络提取更多的信息。
但是,VarGNet是针对常用任务设计的,例如图像分类和目标检测。它将头部的空域减小到一半,以节省内存和计算成本,而这种方式并不适合人脸识别任务,因为它需要更详细的面部信息。而且,在最后的conv和全连接层之间,只有一个平均池化层,可能无法提取足够的区分性信息。
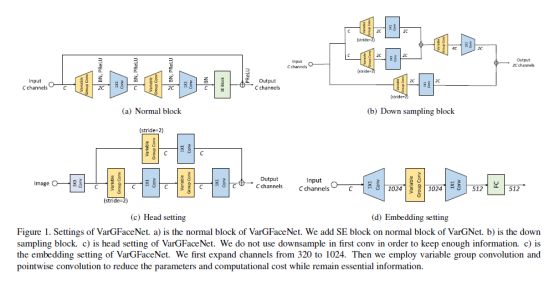
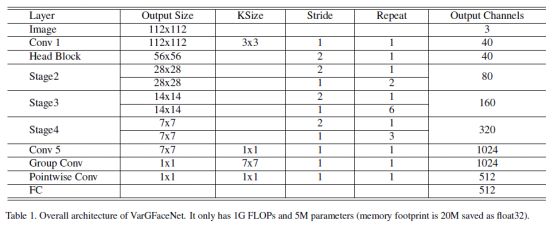
基于VarGNet,作者提出了一种有效的用于轻量级人脸识别的可变组卷积网络,简称VarGFaceNet。为了增强VarGNet对大规模人脸识别任务的判别能力,作者首先在VarGNet的块上添加SE块[13]和PReLU [8]。然后,在网络开始时删除了下采样过程,以保留更多信息。为了减少网络参数,作者用可变组卷积将特征张量缩小到fc层之前的1×1×512。
VarGFaceNet的性能表明,这种设置方法可以保留判别能力,同时减少网络参数。为了增强轻量级网络的解释能力,我们在训练过程中采用了知识蒸馏方法。目前有几种方法可以使深层网络更小,更高效,例如模型修剪,模型量化和知识蒸馏。最近,ShrinkTeaNet 引入了一个角度蒸馏损失来关注教师模型的角度信息。
受角度蒸馏损失的启发,作者采用等效损失和更好的实现来指导VarGFaceNet。此外,为了减轻教师模型和学生模型之间优化的复杂性,作者引入了递归知识提炼,它将递归的学生模型视为下一代的预训练模型。
LFR挑战赛是关于轻量级人脸识别挑战,它要求FLOPs数在1G以下且内存占用在20M以下的网络。VarGFaceNet在这一挑战上实现了SOTA的性能,这在第3节中有介绍。总之,本文贡献如下:
-
为了提高VarGNet在大规模人脸识别中的判别能力,作者采用了不同的头部并提出了一个新的嵌入块。在嵌入块中,作者先通过1×1卷积层将通道扩展到1024,以保留基本信息,然后使用可变组conv和逐点conv将空域缩小到1×1,节省计算成本。如下文所示,这样的操作能提高人脸识别任务的性能。
-
为了提高轻量级模型的泛化能力,作者提出了递归知识蒸馏,以减少教师模型和学生模型之间的泛化差距。
-
作者分析了可变组卷积的性能,并在训练过程中采用了等效的角度蒸馏损失。实验证明了本文方法的有效性。
数据集和评价标准
从头训练VarGFaceNet

使用ResNet指导训练VarGFaceNet
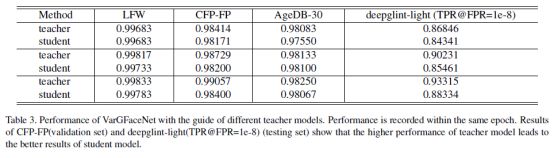

采用递归知识蒸馏进行训练

(*本文为 AI科技大本营整理文章,请微信联系 1092722531)
◆
精彩推荐
◆


推荐阅读

你点的每个“在看”,我都认真当成了AI