DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
- 来源
- 背景
- Motivation
- 强化学习
- 训练过程
- 实验
- 代码
来源
2017 EMNLP
Wenhan Xiong and Thien Hoang and William Yang Wang
Department of Computer Science
University of California, Santa Barbara
Santa Barbara, CA 93106 USA
{xwhan,william}@cs.ucsb.edu, [email protected]
背景
在自然语言处理领域的许多问题往往要求多个相互关联的决策相互作用,目前基于深度学习的知识推理问题仍然是一个非常有挑战的课题。为了能够处理复杂的查询,例如没有显式答案,我们期望机器有能力根据现存的有限资源推断出未知的答案。本文将围绕多跳推理展开研究,为了更简便的理解多跳推理,举一个例子:在一个知识图谱中包含Neymar plays for Barcelona, and Barcelona are in the La Liga league 这样的事实,我们需要让机器学会下面的公式:playerPlaysForTeam(P,T) ∧ teamPlaysInLeague(T,L) ⇒ playerPlaysInLeague(P,L). 多跳推理在复杂的问答系统中有着非常广泛的应用。
Motivation
PRA 算法是一个非常经典的知识图谱上的推理模型,它使用具有基于重启的推理机制的随机游走来执行多个有界深度优先搜索过程以找到关系路径,与弹性网络相结合,使用监督学习的方法选择更可能的路径。PRA算法是在完全离散空间中进行,这使得在评估和比较相似的实体和关系变得困难。
本文将路径学习过程视为一个强化学习过程,使用基于翻译的embedding方法编码智能体在连续空间中的状态, 通过采样关系增量扩展路径,本文使用新的奖励函数进行基于策略梯度的训练,目的是提高准确性、多样性、效率。本文的方法在连续空间中推理,通过在奖励函数中引入不同的标准,更好的控制路径寻找的过程。
强化学习
强化学习系统包括两个部分,一部分是环境系统,另一部分是智能体,第一部分负责知识图谱与智能体之间的动态交互,在强化学习中,环境被视为一个马尔科夫决策过程 < S , A , P , R > <S,A,P,R> <S,A,P,R>, S S S表示连续的状态空间, A A A是一系列可行的动作, P P P是概率转移矩阵, R ( s , a ) R(s,a) R(s,a)是奖励函数。智能体被表示为一个策略网络 π θ ( s , a ) = p ( a ∣ s , θ ) \pi_\theta(s,a) = p(a|s,\theta) πθ(s,a)=p(a∣s,θ), 架构如图所示:
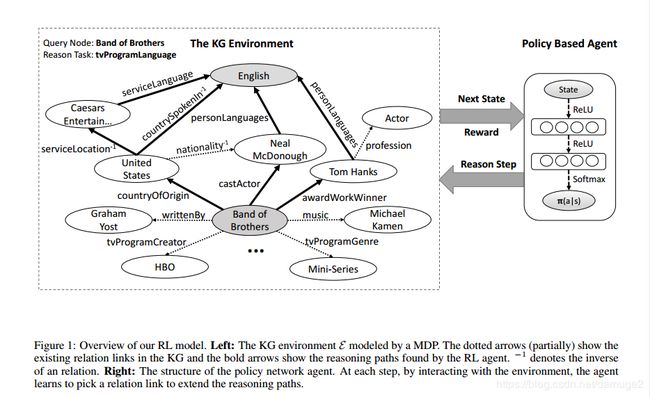
action:
给定一个实体对 p ( s , t ) p(s,t) p(s,t), 期望智能体可以找到一条最符合链接两个实体的路径,智能体使用策略网络选择一条最有可能的关系扩展当前的路径,直到达到目标实体。因此动作空间被建模为知识图谱中全体关系空间。
状态:
知识图谱中的实体与关系都是离散的符号原子,由于知识图谱的规模,状态不能够对所有的符号原子进行建模,因此本文将智能体所在位置作为状态,这里使用基于翻译的embedding的实体表示: s t = ( e t , e t a r g e t − e t ) s_t = (e_t, e_{target} - e_t) st=(et,etarget−et),这里的状态表示没有加入推理的关系,这是因为在路径寻找过程中,推理的关系是不变的,对训练没有帮助。
奖励:
强化学习是受奖励驱动的,很多因素会影响选择路径的质量,为了鼓励智能体找到可预测的路径,本文提出了一下的奖励函数:
- 准确性

- 路径效率

依据短路径可以提供更加可靠的推理证据相对于长路径 - 多样性

为了鼓励智能体尽可能找到不同的路径
策略网络:
使用一个全连接的神经网络参数化 π ( s ; θ ) \pi(s;\theta) π(s;θ) 将状态向量 s s s映射到在所有可能动作上的概率分布,神经网络包含两个隐藏层,每层后面加一个relu激活函数,输出层使用softmax函数规范化
训练过程
在大型知识图谱上使用强化学习方法寻找路径,如果单纯直接进行反复训练,则面临难以收敛的问题,受AlphaGo中使用专家指导预训练的启发,本文使用监督的策略学习进行预训练。
监督策略训练:
对于每个关系,使用一个所有正例的子集进行监督策略学习。使用双向的宽度优先搜索算法寻找正确连接两个实体的路径,对于每条路径,使用蒙特卡洛策略梯度最大化期望累计奖励:

通过加入BFS算法找到的路径,可以近似的计算梯度来更新策略网络:

BFS更倾向于搜索短的路径,但是本文期望路径原则完全由奖励函数驱动,本文使用了一个技巧:
在 ( e s o u r c e , e t a r g e t ) (e_{source},e_{target}) (esource,etarget)中间随机选择一个中间节点 e i n t e r e_inter einter, 分别在 ( e s o u r c e , e i n t e r ) (e_{source}, e_{inter}) (esource,einter)和 e i n t e r , e t a r g e t e_{inter},e_{target} einter,etarget搜索路径,将搜索的路径合并在一起来训练智能体,监督的策略学习从失败的经验中学习到很多,然后在训练智能体找到期望的路径。
使用奖励函数再训练:

初始点 e s o u r c e e_{source} esource,根据所有关系的概率分布 π ( a ∣ s ) \pi(a|s) π(a∣s)选择一个动作扩展推理路径,关系链接可能会指向一个新的实体也可能没有对应的下一个实体,这些失败的步骤导致智能体获得一个负的奖励。在经过错误的步骤后,智能体保持相同的状态,由于采用随机策略,智能体不会陷于重复一个错误的步骤。
双向路径约束搜索:
给定一个实体对,智能体学习到推理路径可以被用来作为逻辑公式预测关系链接。每个公式使用双向的搜索进行验证,目的是减小搜索空间。举例:对于关系personNationality−1,the US 有很多邻居实体,如果一个公式包含很多这样的链接,中间节点会指数增加,但是如果从相反方向来验,中间节点的数量会大大减少。

实验
为了验证智能体找到的推理公式,本文实验了两个推理任务:链接预测(找目标实体)、事实预测(事实成不成立)
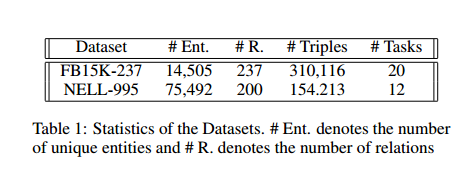

当两个实体之间关系路径的数量较少时,PRA 和本文的RL模型表现的不好。此外在NELL数据集上RL模型的表现好于FB数据集
事实预测:


代码
代码