TCP在FIN_WAIT1状态到底能持续多久以及TCP假连接问题
近期遇到一个问题,简单点说,主机A上显示一条ESTABLISHED状态的TCP连接到主机B,而主机B上却没有任何关于主机A的连接信息,经查明,这是由于主机A和主机B的发送/接收缓冲区差异巨大,导致主机B进程退出后,主机A暂时憋住,主机B频繁发送零窗口探测,FIN_WAIT1状态超时,进而连接被销毁,然而主机A并不知情导致。
正好昨天也有人咨询另外一个类似的问题,那么就抽昨晚和今天早上的时间,写一篇总结吧。
TCP处处是坑!
不要觉得你对TCP的实现的代码烂熟于心了就能把控它的所有行为!不知道你有没有发现,目前市面上新上市的关于Linux内核协议栈的书可谓是汗牛充栋,然而无论作者是国内的还是国外,几乎都是碰到TCP就草草略过,反而对IP,ARP,DNS这些大书特书,Why?因为Linux内核里TCP的代码太乱太复杂了,很少有人能看明白80%以上的,即便真的有看过的,其中还包括只懂代码而不懂网络技术的,我就发现很多声称自己精通Linux内核TCP/IP源码,结果竟然不知道什么是默认路由…
所以我打算写一篇文章,趁着这个FIN_WAIT1问题,顺便表达一下我是如何学习网络技术,我是如何解决网络问题的方法论观点,都是形而上,个人看法:
- 设计覆盖全面的复现实验
- 通读协议标准文档,理解实现建议
- 再次实验,预测并确认问题以外的现象
- 核对代码实现,跟踪代码的Changelog
- 写一个自己的实现或者乱改代码
…
本文聊聊TCP的FIN_WAIT1以及TCP假连接(死连接)问题。先看FIN_WAIT1。
首先还是从状态机入手,看看和FIN_WAIT1相关的状态机转换图:

我们只考虑常规的从ESTABLISHED状态的转换,很简单的一个单一状态转换:
- ESTAB状态发送FIN即切换到FIN_WAIT1状态;
- FIN_WAIT1状态下收到针对FIN的ACK即可离开FIN_WAIT1到达FIN_WAIT2.
看一下和上述状态机转换相关的简单时序图:
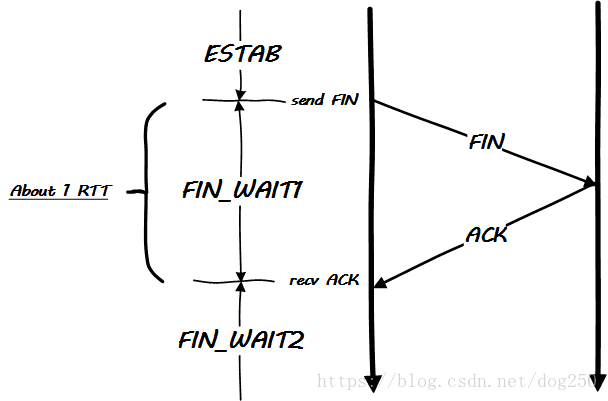
从状态图和时序图上,我们很明确地可以看到,FIN_WAIT1持续1个RTT左右的时间!这个时间段几乎不会被肉眼观察到,转瞬而即逝。
然而,这是真的吗?
我们之所以得到FIN_WAIT1持续1个RTT这个结论,基于两个假设,即:
- TCP的对端是一个正常的TCP端;
- 两端TCP之间的链路是正常的,可达的。
OK,接下来我们来设计一个实验模拟异常的情况。准备实验拓扑如下:

host1和host2的系统内核版本(uname -r获取):
3.10.0-862.2.3.el7.x86_64首先,我们看一下如果对端TCP针对FIN发送的ACK丢失,会发生什么。按照上述的时序图,正常应该是FIN_WAIT1将会永久持续。我们来验证一下。
- 实验1:模拟ACK丢失
在host1上做以下命令:
nc -l -p 1234host2上完成以下命令:
cat /dev/zero|nc 1.1.1.1 1234以上保证了host1和host2之间的TCP建立并且连接之间有持续的数据传输。接下来,在host2上执行下列动作:
iptables -A INPUT -p tcp --tcp-flags ACK,FIN ACK
killall nc此时在host2上:
[root@localhost ~]# netstat -antp|grep 1234
tcp 0 1229 1.1.1.2:39318 1.1.1.1:1234 FIN_WAIT1 - 连续上翻命令,这个FIN_WAIT1均不会消失,暂时符合我们的预期…出去抽根烟,刷会儿微博…回来后,发现这个FIN_WAIT1消失了!
它是如何消失的呢?这个时候,我们提取netstat数据,执行“ netstat -st”,会发现:
TcpExt:
...
1 connections aborted due to timeout多了一条timeout连接!
我这里直接说答案吧。
虽然说在协议上规范上看,TCP没有必要为链路或者说对端的不合常规的行为而买单,但是从现实角度,TCP的实现必须处理异常情况,TCP的实现必然要有所限制!。
我们知道,计算机是无法处理无限,无穷这种抽线的数学概念的,所有如果针对FIN的ACK迟迟不来,那么必然要有一个等待的极限,这个极限在Linux内核协议栈中由以下参数控制:
net.ipv4.tcp_orphan_retries # 默认值是0!这里有坑...这个参数表示如果一直都收不到针对FIN的ACK,那么在彻底销毁这个FIN_WAIT1的连接前,等待几轮RTO退避。
所谓的orphan tcp connection,意思就是说,在Linux进程层面,创建该连接的进程已经退出销毁了,然而在TCP协议层面,它依然在遵循TCP状态机的转换规则存在着。
注意,这个参数不是一个时间量,而是一个次数量。我们知道,TCP每一次超时,都会对下一次超时时间进行指数退避,这里的次数量就是要经过几次退避的时间。举一个例子,如果RTO是2ms,而tcp_orphan_retries 的值是4,那么所计算出的FIN_WAIT1容忍时间就是:
T=21+22+23+24 T = 2 1 + 2 2 + 2 3 + 2 4
还是看看Linux内核文档怎么说的吧:
tcp_orphan_retries - INTEGER
This value influences the timeout of a locally closed TCP connection, when RTO retransmissions remain unacknowledged.
See tcp_retries2 for more details.
The default value is 8.
If your machine is a loaded WEB server,
you should think about lowering this value, such sockets
may consume significant resources. Cf. tcp_max_orphans.
让我们看看tcp_retries2,以获取数值的含义:
tcp_retries2 - INTEGER
This value influences the timeout of an alive TCP connection,
when RTO retransmissions remain unacknowledged.
Given a value of N, a hypothetical TCP connection following
exponential backoff with an initial RTO of TCP_RTO_MIN would
retransmit N times before killing the connection at the (N+1)th RTO.
The default value of 15 yields a hypothetical timeout of 924.6
seconds and is a lower bound for the effective timeout.
TCP will effectively time out at the first RTO which exceeds the hypothetical timeout.
RFC 1122 recommends at least 100 seconds for the timeout,
which corresponds to a value of at least 8.
虽然说文档上默认值的建议是8,但是大多数的Linux发行版上其默认值都是0。更多详情,就自己看RFC和Linux源码吧。
有了这个参数保底,我们知道,即便是ACK永远不来,FIN_WAIT1状态也不会一直持续下去的,这有效避免了有针对性截获ACK或者不发送ACK而导致的DDoS,退一万步讲,即便是没有DDoS,这种做法也具有资源利用率的容错性,使得资源使用更加高效。
实验1的结论如下:
- 如果主动断开端调用了close关掉了进程,它会进入FIN_WAIT1状态,此时如果它再也收不到ACK,无论是针对pending在发送缓冲的数据还是FIN,它都会尝试重新发送,在收到ACK前会尝试N次退避,该N由tcp_orphan_retries参数控制。
接下来,我们来看一个更加复杂一点的问题,还是先从实验说起。
- 实验2:模拟对端TCP不收数据,接收窗口憋死
在host1上做以下命令:
# 模拟小接收缓存,使得憋住接收窗口更加容易
sysctl -w net.ipv4.tcp_rmem="16 32 32"
nc -l -p 1234host2上完成以下命令:
cat /dev/zero|nc 1.1.1.1 1234
sleep 5 # 稍微等一下
killall nc此时,我们发现host2的TCP连接进入了FIN_WAIT1状态。然而抓包看的话,数据传输依然在进行:
05:15:51.674630 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 305:321, ack 1, win 5840, options [nop,nop,TS val 1210945 ecr 238593370], length 16
05:15:51.674690 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 321, win 0, options [nop,nop,TS val 238593471 ecr 1210945], length 0
05:15:51.674759 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 321, win 16, options [nop,nop,TS val 238593471 ecr 1210945], length 0
05:15:51.777774 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 321:325, ack 1, win 5840, options [nop,nop,TS val 1211048 ecr 238593471], length 4
05:15:51.777874 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 325, win 16, options [nop,nop,TS val 238593497 ecr 1211048], length 0
05:15:52.182918 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 325:341, ack 1, win 5840, options [nop,nop,TS val 1211453 ecr 238593497], length 16
05:15:52.182970 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 341, win 0, options [nop,nop,TS val 238593599 ecr 1211453], length 0
05:15:52.183055 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 341, win 16, options [nop,nop,TS val 238593599 ecr 1211453], length 0
05:15:52.592759 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 341:357, ack 1, win 5840, options [nop,nop,TS val 1211863 ecr 238593599], length 16
05:15:52.592813 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 357, win 0, options [nop,nop,TS val 238593701 ecr 1211863], length 0
05:15:52.592871 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 357, win 16, options [nop,nop,TS val 238593701 ecr 1211863], length 0
05:15:52.695160 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 357:361, ack 1, win 5840, options [nop,nop,TS val 1211965 ecr 238593701], length 4
05:15:52.695276 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 361, win 16, options [nop,nop,TS val 238593727 ecr 1211965], length 0
05:15:53.099612 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 361:377, ack 1, win 5840, options [nop,nop,TS val 1212370 ecr 238593727], length 16
05:15:53.099641 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 377, win 0, options [nop,nop,TS val 238593828 ecr 1212370], length 0
05:15:53.099671 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 377, win 16, options [nop,nop,TS val 238593828 ecr 1212370], length 0
05:15:53.505028 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 377:393, ack 1, win 5840, options [nop,nop,TS val 1212775 ecr 238593828], length 16
05:15:53.505081 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 393, win 0, options [nop,nop,TS val 238593929 ecr 1212775], length 0
05:15:53.505138 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 393, win 16, options [nop,nop,TS val 238593929 ecr 1212775], length 0
05:15:53.605923 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [P.], seq 393:397, ack 1, win 5840, options [nop,nop,TS val 1212876 ecr 238593929], length 4这是显然的,这是因为收发两端巨大的缓存大小差异造成的,即便是host2发送端进程退出了,在退出前已经有大量数据pending到了TCP的发送缓冲区里面而脱离已经被销毁的进程了,FIN包当然是排在了缓冲区的末尾了。
TCP的状态机运行在缓存的上层,即只要把FIN包pending排队,就切换到了FIN_WAIT1,而不是说实际发送了FIN包才切换。
因此,我们可有的等了,数据传输依然在正常有序进行,针对小包的ACK源源不断从host1回来,这进一步促进host2发送未竟的数据包,直到所有缓冲区的数据全部发送完毕…
不管怎样,总是有个头儿,只要有结束,就不需要担心。我们可以简单得出一个结论:
- 如果主动断开端调用了close关掉了进程,它会进入FIN_WAIT1状态,如果接收端的接收窗口呈现打开状态,此时它的TCP发送队列中的数据包还是会像正常一样发往接收端,直到发送完,最后发送FIN包,收到FIN包ACK后进入FIN_WAIT2。
现在,我们进行实验的下一步,把host1上的接收进程nc的接收逻辑彻底憋死。很简单,host1上执行下面的命令即可:
killall -STOP nc进程并没有退出,只是暂停了,nc进程上下文的recv不再执行,然而软中断上下文的TCP协议的处理依然在进行。
这个时候,抓包就会发现只剩下指数时间退避的零窗口探测包了:
# 注意观察探测包发送时间的间隔
05:15:56.444570 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1215715 ecr 238594487], length 0
05:15:56.444602 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238594664 ecr 1214601], length 0
05:15:57.757217 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1217027 ecr 238594664], length 0
05:15:57.757248 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238594992 ecr 1214601], length 0
05:16:00.283259 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1219552 ecr 238594992], length 0
05:16:00.283483 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238595624 ecr 1214601], length 0
05:16:05.234277 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1224503 ecr 238595624], length 0
05:16:05.234305 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238596861 ecr 1214601], length 0
05:16:15.032486 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1234301 ecr 238596861], length 0
05:16:15.032532 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238599311 ecr 1214601], length 0
05:16:34.629137 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1253794 ecr 238599311], length 0
05:16:34.629164 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238604210 ecr 1214601], length 0
05:17:13.757815 IP 1.1.1.2.39318 > 1.1.1.1.1234: Flags [.], ack 1, win 5840, options [nop,nop,TS val 1292784 ecr 238604210], length 0
05:17:13.757863 IP 1.1.1.1.1234 > 1.1.1.2.39318: Flags [.], ack 465, win 0, options [nop,nop,TS val 238613992 ecr 1214601], length 0这个实验的现象和实验1的现象,仅有一个区别,那就是实验1是阻塞了ACK,而本实验则是FIN根本就还没有发送出去就进入了FIN_WAIT1,且针对RTO指数时间退避发送的零窗口探测的ACK持续到来,简单总结就是:
实验1没有ACK到来,实验2有ACK到来。
在实验结果之前,我们来看一段摘录,来自RFC 1122:https://tools.ietf.org/html/rfc1122#page-92
4.2.2.17 Probing Zero Windows: RFC-793 Section 3.7, page 42
.
Probing of zero (offered) windows MUST be supported.
.
A TCP MAY keep its offered receive window closed
indefinitely. As long as the receiving TCP continues to
send acknowledgments in response to the probe segments, the
sending TCP MUST allow the connection to stay open.
紧接着后面是一段注解:
DISCUSSION:
It is extremely important to remember that ACK
(acknowledgment) segments that contain no data are not
reliably transmitted by TCP. If zero window probing is
not supported, a connection may hang forever when an
ACK segment that re-opens the window is lost.
.
The delay in opening a zero window generally occurs
when the receiving application stops taking data from
its TCP. For example, consider a printer daemon
application, stopped because the printer ran out of
paper.
只要有ACK到来,连接就要保持,这会带来什么问题呢?确实会带来问题,但是在正视这些问题之前,Linux内核协议栈的实现者,也保持了缄默,我们来看一段实验主机host1和host2所用的标准内核主线版本3.10的内核源码,来自tcp_probe_timer函数内部的注释以及一小段代码:
/* *WARNING* RFC 1122 forbids this
*
* It doesn't AFAIK, because we kill the retransmit timer -AK
*
* FIXME: We ought not to do it, Solaris 2.5 actually has fixing
* this behaviour in Solaris down as a bug fix. [AC]
*
* Let me to explain. icsk_probes_out is zeroed by incoming ACKs
* even if they advertise zero window. Hence, connection is killed only
* if we received no ACKs for normal connection timeout. It is not killed
* only because window stays zero for some time, window may be zero
* until armageddon and even later. We are in full accordance
* with RFCs, only probe timer combines both retransmission timeout
* and probe timeout in one bottle. --ANK
*/
...
max_probes = sysctl_tcp_retries2;
if (sock_flag(sk, SOCK_DEAD)) { // 如果是orphan连接的话
const int alive = ((icsk->icsk_rto << icsk->icsk_backoff) < TCP_RTO_MAX);
// 即获取tcp_orphan_retries参数,有微调,请详审。本实验参数默认值取0!
max_probes = tcp_orphan_retries(sk, alive);
if (tcp_out_of_resources(sk, alive || icsk->icsk_probes_out <= max_probes))
return;
}
// 只有在icsk_probes_out,即未应答的probe次数超过探测最大容忍次数后,才会出错清理连接。
if (icsk->icsk_probes_out > max_probes) {
tcp_write_err(sk);
} else {
/* Only send another probe if we didn't close things up. */
tcp_send_probe0(sk);
}是的,从上面那一段注释,我们看出了抱怨,一个FIN_WAIT1的连接可能会等到世界终结日之后,然而我们却只能“in full accordance with RFCs”!
这也许暗示了某种魔咒般的结果,即FIN_WAIT1将会一直持续到终结世界的大决战之日。然而非也,你会发现大概在发送了9个零窗口探测包之后,连接就消失了。netstat -st的结果中,呈现:
1 connections aborted due to timeout看来想制造点事端,并非想象般容易!
如上所述,我展示了标准主线的Linux 3.10内核的tcp_probe_timer函数,现在的问题是,为什么下面的条件被满足了呢?
if (icsk->icsk_probes_out > max_probes) 只有当这个条件被满足,tcp_write_err才会被调用,进而:
tcp_done(sk);
// 递增计数,即netstat -st中的那条“1 connections aborted due to timeout”
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPABORTONTIMEOUT);按照注释和代码的确认,只要收到ACK,icsk_probes_out 字段就将被清零,这是很明确的啊,我们在tcp_ack函数中便可看到无条件清零icsk_probes_out的动作:
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
...
sk->sk_err_soft = 0;
icsk->icsk_probes_out = 0;
tp->rcv_tstamp = tcp_time_stamp;
...
}从代码上看,只要零窗口探测持续发送,不管退避到多久(最大TCP_RTO_MAX),只要对端会有ACK回来,icsk_probes_out 就会被清零,上述的条件就不会被满足,连接就会一直在FIN_WAIT1状态,而从我们抓包看,确实是零窗口探测有去必有回的!
预期会永远僵在FIN_WAIT1状态的连接在一段时间后竟然销毁了。没有符合预期,到底发生了呢?
如果我们看高版本4.14版的Linux内核,同样是tcp_probe_timer函数,我们会看到一些不一样的代码和注释:
static void tcp_probe_timer(struct sock *sk)
{
...
/* RFC 1122 4.2.2.17 requires the sender to stay open indefinitely as
* long as the receiver continues to respond probes. We support this by
* default and reset icsk_probes_out with incoming ACKs. But if the
* socket is orphaned or the user specifies TCP_USER_TIMEOUT, we
* kill the socket when the retry count and the time exceeds the
* corresponding system limit. We also implement similar policy when
* we use RTO to probe window in tcp_retransmit_timer().
*/
start_ts = tcp_skb_timestamp(tcp_send_head(sk));
if (!start_ts)
tcp_send_head(sk)->skb_mstamp = tp->tcp_mstamp;
else if (icsk->icsk_user_timeout &&
(s32)(tcp_time_stamp(tp) - start_ts) >
jiffies_to_msecs(icsk->icsk_user_timeout))
goto abort;
max_probes = sock_net(sk)->ipv4.sysctl_tcp_retries2;
if (sock_flag(sk, SOCK_DEAD)) {
const bool alive = inet_csk_rto_backoff(icsk, TCP_RTO_MAX) < TCP_RTO_MAX;
max_probes = tcp_orphan_retries(sk, alive);
// 如果处在FIN_WAIT1的连接持续时间超过了TCP_RTO_MAX(这是前提)
// 如果退避发送探测的次数已经超过了配置参数指定的次数(这是附加条件)
if (!alive && icsk->icsk_backoff >= max_probes)
goto abort; // 注意这个goto!直接销毁连接。
if (tcp_out_of_resources(sk, true))
return;
}
if (icsk->icsk_probes_out > max_probes) {
abort: tcp_write_err(sk);
} else {
/* Only send another probe if we didn't close things up. */
tcp_send_probe0(sk);
}
}我们来看这段代码的注释,RFC1122的要求:
RFC 1122 4.2.2.17 requires the sender to stay open indefinitely as
long as the receiver continues to respond probes. We support this by
default and reset icsk_probes_out with incoming ACKs.
然后我们接着看这段注释,有一个But转折:
But if the socket is orphaned or the user specifies TCP_USER_TIMEOUT, we
kill the socket when the retry count and the time exceeds the corresponding system limit.
看起来,这段注释是符合我们实验的结论的!然而我们实验的是3.10内核,而这个却是4.X的内核啊!即Linux在高版本内核上确实进行了优化,这是针对资源利用的优化,并且避免了有针对性的DDoS。
答案揭晓了。
*我们实验所使用的内核版本不是社区主线版本,而是Redhat的版本!***Redhat显然会事先回移上游的patch,我们来确认一下我们所所用的实验版本3.10.0-862.2.3.el7.x86_64的tcp_probe_timer的源码。
为此,我们到下面的地址去下载Redhat(Centos…)专门的源码,我们看看它和社区同版本源码是不是在关于probe处理上有所不同:
http://vault.centos.org/7.5.1804/updates/Source/SPackages/
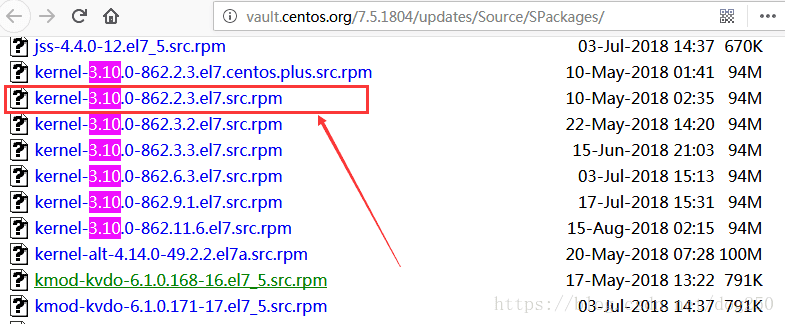
使用下面的命令解压:
rpm2cpio ../kernel-3.10.0-862.2.3.el7.src.rpm | cpio -idmv
xz linux-3.10.0-862.2.3.el7.tar.xz -d
tar xvf linux-3.10.0-862.2.3.el7.tar 查看net/ipv4/tcp_timer.c文件,找到tcp_probe_timer函数:

看来是Redhat移植了4.X的patch,导致了源码的逻辑和社区版本的出现差异,这也就解释了实验现象!
那么这个针对orphan connection的patch最初是来自何方呢?我们不得不去patchwork去溯源,以便得到更深入的Why。
在maillist,我找到了下面的链接:
http://lists.openwall.net/netdev/2014/09/23/8
Date: Mon, 22 Sep 2014 20:52:13 -0700
From: Yuchung Cheng [email protected]
To: davem@…emloft.net
Cc: edumazet@…gle.com, andrey.dmitrov@…etlabs.ru,
ncardwell@…gle.com, netdev@…r.kernel.org,
Yuchung Cheng [email protected]
Subject: [PATCH net-next] tcp: abort orphan sockets stalling on zero window probes
摘录一段描述吧:
Currently we have two different policies for orphan sockets
that repeatedly stall on zero window ACKs. If a socket gets
a zero window ACK when it is transmitting data, the RTO is
used to probe the window. The socket is aborted after roughly
tcp_orphan_retries() retries (as in tcp_write_timeout()).
.
But if the socket was idle when it received the zero window ACK,
and later wants to send more data, we use the probe timer to
probe the window. If the receiver always returns zero window ACKs,
icsk_probes keeps getting reset in tcp_ack() and the orphan socket
can stall forever until the system reaches the orphan limit (as
commented in tcp_probe_timer()). This opens up a simple attack
to create lots of hanging orphan sockets to burn the memory
and the CPU, as demonstrated in the recent netdev post “TCP
connection will hang in FIN_WAIT1 after closing if zero window is
advertised.” http://www.spinics.net/lists/netdev/msg296539.html
该链接最后面给出了patch:
...
+ max_probes = sysctl_tcp_retries2;
if (sock_flag(sk, SOCK_DEAD)) {
const int alive = inet_csk_rto_backoff(icsk, TCP_RTO_MAX) < TCP_RTO_MAX;
max_probes = tcp_orphan_retries(sk, alive);
-
+ if (!alive && icsk->icsk_backoff >= max_probes)
+ goto abort;
if (tcp_out_of_resources(sk, alive || icsk->icsk_probes_out <= max_probes))
return;
}
if (icsk->icsk_probes_out > max_probes) {
- tcp_write_err(sk);
+abort: tcp_write_err(sk);
} else {
...简单说一下这个patch的意义。
在实验2中,我用kill -STOP信号故意憋死了nc接收进程,以重现现象,然而事实上在现实中,存在下面两种不太友善情况:
- 接收端进程出现异常,或者接收端内核存在缺陷,导致进程挂死而软中断上下文的协议栈处理正常运行;
- 接收端就是一个恶意的DDoS进程,故意不接收数据以诱导发送端在FIN_WAIT2状态(甚至ESTAB状态)发送数据不成后发送零窗口探测而不休止。
无论哪种情况,最主动断开的发送端来讲,其后果都是消耗大量的资源,而orphan连接则占着茅坑不拉屎。这比较悲哀。
现在给出本文的第三个结论:
- 如果主动断开端调用了close关掉了进程,它会进入FIN_WAIT1状态,如果接收端的接收窗口呈现关闭状态(零窗口),此时它会不断发送零窗口探测包。发送多少次呢?有两种实现:
- 低版本内核(至少社区3.10及以下):永久尝试,如果探测ACK每次都返回,则没完没了。
- 高版本内核(至少社区4.6及以上):限制尝试tcp_orphan_retries次,不管是否收到探测ACK。
当然,其实还有关于非探测包的重传限制,比如关于TCP_USER_TIMEOUT这个socket option的限制:
else if (icsk->icsk_user_timeout &&
(s32)(tcp_time_stamp(tp) - start_ts) >
jiffies_to_msecs(icsk->icsk_user_timeout))
goto abort;包括关于Keepalive的点点滴滴,本文就不多说了。
在此,先有个必要的总结。我老是说在学习网络协议的时候读码无益并不是说不要去阅读解析Linux内核源码,而是一定要先有实验设计的能力重现问题,然后再去核对RFC或者其它的协议标准,最后再去核对源码到底是怎么实现的,这样才能一气呵成。否则将有可能陷入深渊。
以本文为例,我假设你手头有3.10的源码,当你面对“FIN_WAIT1状态的TCP连接在持续退避的零窗口探测期间并不会如预期那般永久持续下去”这个问题的时候,你读源码是没有任何用的,因为这个时候你只能静静地看着那些代码,然后纠结自己是不是哪里理解错了,很多人甚至很难能想到去对比不同版本的代码,因为版本太多了。
源码只是一种实现的方式,而已,真正重要的是协议的标准以及标准是实现的建议,此外,各个发行版厂商完全有自主的权力对社区源码做任何的定制和重构,不光是Redhat,即便你去看OpenWRT的代码,也是一样,你会发现很多不一样的东西。
我并不赞同几乎每一个程序员都拥护的那种任何情况下源码至上,the whole world is cheap,show me the code的观点,当一个逻辑流程摆在那里没有源码的时候,当然那绝对是源码至上,否则就是纸上谈兵,逻辑至少要跑起来,而只有源码编译后才能跑起来,流程图和设计图是无法运行的,这个时候,你需要放弃讨论,潜心编码。然而,当一个网络协议已经被以各种方式实现了而你只是为了排查一个问题或者确认一个逻辑的时候,代码就退居二三线了,这时候,请“show me the standard!”。
本文原本是想解释完FIN_WAIT1能持续多久就结束的,但是这样显得有点遗憾,因为我想本文的这个FIN_WAIT1的论题可以引出一个更大的论题,如果不继续说一说,那便是不负责任的。
是什么的?嗯,是TCP假连接的问题。那么何谓TCP假连接?
所谓的TCP假连接就是TCP的一端已经逃逸出了TCP状态机,而另一端却不知道的连接。
我们再看完美的TCP标准RFC793上的TCP状态图:

除了TIME_WAIT到CLOSED这唯一的出口,你是找不到其它出口的,也就是说,一个TCP端一旦发起了建立连接请求,暂不考虑同时打开同时关闭的情况,就一定要到其中一方的TIME_WAIT超时而结束。
然而,TCP的缺陷在于,TCP是一个端到端的协议,在协议层面上所有的端到端协议是需要底层的传送协议作为其支撑的,一旦底层永久崩坏,端到端协议将会面临状态机僵住的场景,而状态机僵住意味着对资源的永久消耗,因为连接再也释放不掉了!
随便举一个例子,在两端ESTAB状态的时候,把IP动态路由协议停掉并把把网线剪断,那么TCP两端将永远处在ESTAB状态,直到机器重启。为了解决这个问题,TCP引入了Keepalive机制,一旦超过一定时间没有互通有无,那么就会主动销毁这个连接,事实上,按照纯粹的TCP状态机而言,Keepalive机制是一种对TCP协议的污染。
是不是Keepalive就能完全避免假连接,死连接存在了呢?非也,Keepalive只是一种用户态按照自己的业务逻辑去检测并避免假连接的手段,而我们仔细观察TCP状态机,很多的步骤远不是用户态进程可是touch的,比如本文讲的FIN_WAIT1,一旦连接成为orphan的,将没有任何进程与之关联,虽然用户态设置的Keepalive也可以继续起作用,但万一用户态没有设置Keepalive呢??这时怎么办?
我们执行下面的命令:
[root@localhost ~]# sysctl -a|grep retries
net.ipv4.tcp_orphan_retries = 0
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 5
net.ipv6.idgen_retries = 3嗯,这些就是避免TCP协议本身的状态机转换僵死所引入的控制层Keepalive机制,详细情况就自己去查阅Linux内核文档吧。
在具体实现上,防止状态机僵死的方法分为两类:
- ESTABLISHED防止僵死的方法:使用用户进程设置的Keepalive机制
- 非ESTABLISHED防止僵死的方法:使用各种retries内核参数设置的timeout机制

听说温州老板要来,公司楼下专门驻场高定皮鞋衬衫西裤,完全是为了迎接温州老板,不试穿,无样品,完全量身定做,皇家版。皮鞋可以下雨穿。