【阅读笔记】Image2StyleGAN:How to Embed Images Into the StyleGAN Latent Space
论文名称:Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?
论文作者:Rameen Abdal, Yipeng Qin, Peter Wonka
发行时间:Submitted on 15 Dec 2019, last revised 31 Mar 2020
论文地址:http://openaccess.thecvf.com/content_ICCV_2019/html/…
代码开源:[none]
- 一. 概要
- 二. 图像编码潜在空间的研究
- 2.1. 各种种类的图像编码
- 2.2. 人脸图编码的鲁棒性
- 2.2.1. 仿射变换
- 2.2.2. 缺陷图编码
- 2.3. 编码空间的选择
- 三. 编码算法
- 3.1. 初始化
- 3.2. 损失函数的选择
- 3.3. 超参数设置
- 四. 编码的意义
- 4.1. 图像变换
- 4.2. 风格迁移
- 4.2.1. 人脸类间迁移
- 4.2.2. 不同类间迁移
- 4.3. 表情传递
- 五. 结论
一. 概要
本文提出一种将指定图像编码到 StyleGAN 中的 latent space 中的有效算法, 这种编码使语义图像编辑操作可应用于现有照片. 研究编码算法的结果可为StyleGAN潜在空间的结构提供有价值的见解. 本文的主要贡献就是:
- 提出一种有效的编码算法, 可以将给定图像映射到预先训练的 StyleGAN 的扩展潜空间 W + W+ W+ 中.
- 深入了解了 StyleGAN 潜在空间的结构.
- 对向量使用三个基本运算来研究编码的质量, 这样可以更好地了解潜在空间以及如何编码不同类别的图像.
二. 图像编码潜在空间的研究
2.1. 各种种类的图像编码
论文中收集了一个包含25张不同图像的小规模数据集, 该数据集涵盖了5个类别: 人脸, 猫, 狗, 车, 画, 每个类别各有五张图像. 之所以这样选择, 是因为猫, 狗和绘画与人脸具有相同的整体结构, 只是描绘方式不同, 而汽车则是与人脸没有结构相似性.
编码的结果如上图所示, 尽管文中模型是在人脸数据集上进行训练的, 但是编码算法能让能生成高质量的猫, 狗, 车, 画的图像, 尽管比人脸的效果差, 可见编码算法的有效性和泛化性.
2.2. 人脸图编码的鲁棒性
2.2.1. 仿射变换

如上图所示, styleGAN 的编码对仿射变换非常的敏感. 仿射变换分为 平移、调整大小、旋转. 其中, 平移的效果最差, 因为其可能会产生无效的脸部编码效果; 而对于调整大小和旋转, 产生的图像虽然是有效的, 但丢失了较多细节, 比常规编码效果糟. 这表示学习到的表示在一定程度上仍与图像大小和位置有关.
2.2.2. 缺陷图编码

由上图可知, 虽然移除了某些五官信息, 但是编码生成的结果对其他仍然存在的五官很好的复原了. 可见不同的面部特征的编码是彼此独立. 一方面, 这种现象对于一般的图像编辑是有益的. 另一方面, 这表明潜在空间不会迫使编码的图像成为完整的面孔, 即它不会修补丢失的信息.
2.3. 编码空间的选择
在 styleGAN 中存在多个潜在空间可用于编码. 两个明显的候选空间是 初始潜在空间 Z Z Z 和 中间潜在空间 W W W. 其中 512 512 512 维的向量 w ∈ W w \in W w∈W 是由 512 512 512 维的向量 z ∈ Z z \in Z z∈Z 经过 8 8 8 个全连接层所得到的. 论文中给出的理解是直接将 W W W 或 Z Z Z 进行编码式不容易的.
因此文中给出的建议是编码扩展的编码空间 W + W^+ W+中:
- W + W^+ W+是由 18 18 18 个不同的 w w w 向量连接(串联)而成的
- 这 18 18 18 个不同的 w w w 向量是由 styleGAN 中的生成器里的 18 18 18 层 AdaIN 所接受输入, 这样每一个 w w w 向量都对应于 styleGAN 的一个层.
三. 编码算法
文中的方法是将给定的图像编码到预训练好的生成器集合中, 从合适的初始化 w ⋆ w^{\star} w⋆ 开始, 通过最小化给定的图片和由 w ⋆ w^{\star} w⋆ 生成的图像的相似度损失来使其逐渐逼近于最优的 w ⋆ w^{\star} w⋆. 伪代码如下所示:

3.1. 初始化
文中给出了两种初始化 w ⋆ w^{\star} w⋆ 的方法:
- 随机初始化, 每个参数独立于均匀分布 U [ − 1 , 1 ] \mathcal{U}[-1,1] U[−1,1]
- 观察得出的平均latent code vector w ‾ \overline{w} w , 因为其可辨别出低质量的人脸图像
文中更推荐使用 w ‾ \overline{w} w 作为初始化, 期望优化收敛到更接近与 w ‾ \overline{w} w 的 w ⋆ w^{\star} w⋆.
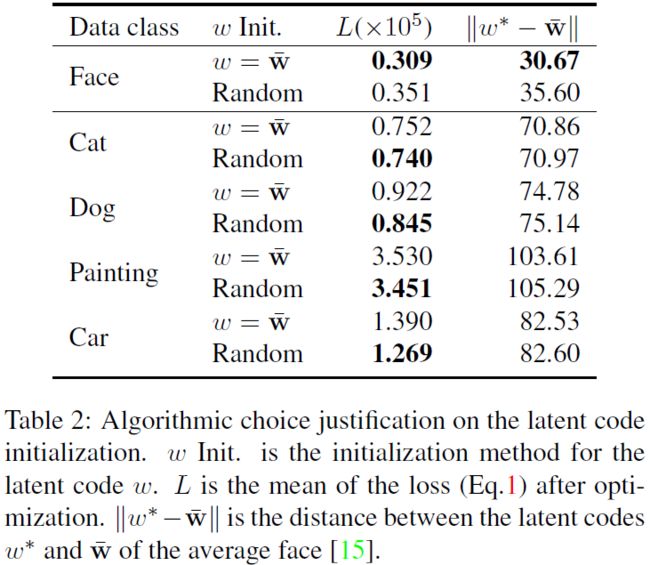
为了评估这两种方法, 文中设计了实验来评估 loss损失 和 ∣ ∣ w ⋆ − w ‾ ∣ ∣ ||w^{\star}-\overline{w}|| ∣∣w⋆−w∣∣距离. 实验结果如下表所示, 对于人脸类图像, 使用 w ‾ \overline{w} w 进行初始化不但使得 w ⋆ w^{\star} w⋆ 更接近于 w ‾ \overline{w} w, 而且损失降低了很多. 对于非人脸类图像, 则随机初始化的效果更好, 从自觉上看, 该现象表明该分部仅具有一个脸部簇, 其他的实例都是围绕在该簇的分散点, 并不会按照其他实例的模型进行构造! 定性结果如上图所示.
3.2. 损失函数的选择
损失函数的选择是 VGG-16中的感知损失与逐像素的MSE损失的加权和: w ⋆ = min w L p e r c e p t ( G ( w ) , I ) + λ m s e N ∣ ∣ G ( w ) − I ∣ ∣ 2 2 w^{\star} = \mathop{\min}\limits_wL_{percept}(G(w),I)+\frac{\lambda_{mse}}{N}||G(w)-I||_2^2 w⋆=wminLpercept(G(w),I)+Nλmse∣∣G(w)−I∣∣22 其中 I ∈ R n × n × 3 I\in \mathbb{R}^{n\times n\times 3} I∈Rn×n×3 是输入图像, G ( ⋅ ) G(\cdot) G(⋅) 是预训练GAN的生成器, N N N是图像的标量的数量( N = n × n × 3 N=n\times n\times 3 N=n×n×3 ), w w w 是需要优化的 latent code vector.
凭经验让 λ m s e = 1 \lambda_{mse} = 1 λmse=1 来获得良好性能, 对于式子中的 L p e r c e p t ( ⋅ ) L_{percept}(\cdot) Lpercept(⋅), 是: L p e r c e p t ( I 1 , I 2 ) = ∑ j = 1 4 λ j N j ∣ ∣ F j ( I 1 ) − F j ( I 2 ) ∣ ∣ 2 2 L_{percept}(I_1,I_2)=\sum^4_{j=1}\frac{\lambda_j}{N_j}||F_j(I_1)-F_j(I_2)||_2^2 Lpercept(I1,I2)=j=1∑4Njλj∣∣Fj(I1)−Fj(I2)∣∣22 其中, I 1 , I 2 ∈ R n × n × 3 I_1,I_2 \in \mathbb{R}^{n\times n\times 3} I1,I2∈Rn×n×3 是输入图像, F j ( ⋅ ) F_j(\cdot) Fj(⋅) 是 VGG-16中 conv1_1, conv1_2, conv3_2 和 conv4_2 的特征输出, N j N_j Nj 是第 j j j 层输出的标量数, λ j = 1 \lambda_j=1 λj=1 是对所有 j j j 根据经验获得的.
之所以这样设计损失函数, 是因为 **仅按像素方式的 MSE 损失无法找到高质量的嵌入. 因此, 感知损失充当某种正则化器, 以将优化引导到潜在空间的正确区域. **

如上图所示, 可见文中的最终方法是最佳性能的.
3.3. 超参数设置
使用 Adam 优化器, 对应学习率为 0.01 0.01 0.01, β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.999 \beta_2=0.999 β2=0.999, ϵ = 1 e − 8 \epsilon=1e^{-8} ϵ=1e−8. 5000 5000 5000 个优化步骤.
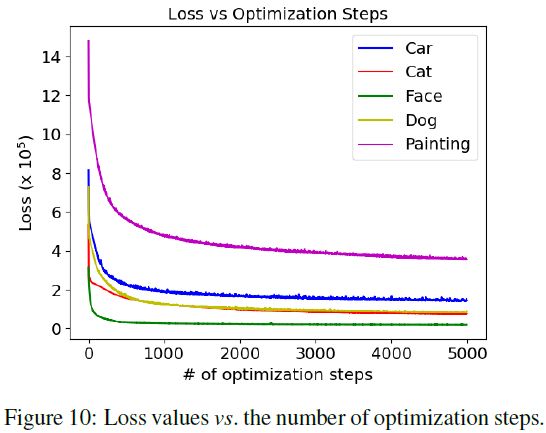
如下图所示, 人脸损失下降最快, 约 1000 1000 1000 个步骤收敛. 猫, 狗 和 汽车在约 3000 3000 3000 个步骤较慢收敛. 绘画则收敛最慢, 约 5000 5000 5000 才收敛.
四. 编码的意义
4.1. 图像变换
给定两个编码图像及其对应的 latent code 向量 w 1 w_1 w1 和 w 2 w_2 w2, 通过线性插值计算进行如下变换: w = λ w 1 + ( 1 − λ ) w 2 , λ ∈ ( 0 , 1 ) w=\lambda w_1+(1-\lambda)w_2,~\lambda\in (0,1) w=λw1+(1−λ)w2, λ∈(0,1) 随后就使用变换得到的新编码 w w w 再生成图像.

在实验中, 如上图所示, 文中方法在人脸的变换效果上很棒, 但在其他类别之间进行变换则效果较差. 文中给出的观点是 styleGAN 中的 latent space 专用于人脸, 因为在非人脸类间的变化的中间图像中存在人脸轮廓. 作者还推测对于非人脸的图像变换的编码方式是这样进行的:
- 最初的图层会创建一个类似人脸的结构.
- 随后的图层会在这个结构上进行绘画.
- 因此不再可被识别.
4.2. 风格迁移
给定两个编码图像及其对应的 latent code 向量 w 1 w_1 w1 和 w 2 w_2 w2, 利用交叉操作来实现风格迁移.
为了方便描述, 文中将提供内容而被改变风格的潜在编码记为 w 1 w_1 w1, 而仅提供风格而不在乎图像主题的潜在编码记为 w 2 w_2 w2. 这样的话, 文中给出的方法是 保留 w 1 w_1 w1的前9层(对应的分辨率为 4 × 4 ∼ 64 × 64 4\times4 \sim 64\times64 4×4∼64×64), 而用 w 2 w_2 w2 中的后9层替换掉原来的(对应的分辨率为 64 × 64 ∼ 1024 × 1024 64\times64 \sim 1024\times1024 64×64∼1024×1024), 便得到了风格迁移后的新 latent code. 之所以这样做是因为低级特征决定了图像的主体, 而高级特征则是决定了颜色等精细特征.
4.2.1. 人脸类间迁移

首先看人脸之间的风格迁移, 如上图所示, 迁移的效果还是可以得, 可见 styleGAN 对人脸的处理能力是很强的.
4.2.2. 不同类间迁移

再看不同类别的编码图像之间的风格迁移, 上图便是迁移结果, 只有人脸作为内容图时效果还算可以, 其他则效果较差. 这表明文中的方法虽然能够传递低级特征(颜色, 纹理等), 但不能忠实地维护非人脸图像的结构内容. 这说明了 styleGAN 的泛化和表达能力很容易驻留在同较高空间分辨率相对应的样式层中.
4.3. 表情传递
给定三个输入向量 w 1 w_1 w1, w 2 w_2 w2, w 3 w_3 w3, 其中 w 1 w_1 w1 是目标图像的 latent code, w 2 w_2 w2 对应于原图像的中性表情的 latent code, w 3 w_3 w3 对应于一种更独特的表情(哭、笑等). 那么表情传递的计算式为: w = w 1 + λ ( w 3 − w 2 ) w=w_1+\lambda(w_3-w_2) w=w1+λ(w3−w2) 为了消除噪声(例如背景噪声), 文中设置了阈值, 即对 latent code 在各通道的差值的 L 2 L_2 L2 范数 设置了下限阈值, 低于该阈值的通道将会被零向量所替换. 在上图进行的实验中, 文中设置阈值为 1 1 1, 并对所得到的的向量进行归一化以控制表达式在特定方向上的强度. 上图得到的表情传递结果具有较高的质量.
五. 结论
提出了一种有效的算法, 将给定的图像嵌入到StyleGAN的潜在空间中. 该算法支持语义图像编辑操作, 例如图像变换, 样式转移和表达转移. 我们还使用该算法来研究Style-GAN潜在空间的多个方面. 我们提出了实验, 以分析可以嵌入哪种类型的图像, 如何嵌入图像以及嵌入的意义. 我们工作的重要结论是, 在扩展的潜在空间W+中嵌入效果最好, 并且可以嵌入任何类型的图像. 但是, 只有脸部的嵌入才有意义.