VarGFaceNet:地平线开源有效可变组卷积的人脸识别网络

概述
为了提高轻量级人脸识别网络的识别和泛化能力,提出了一种有效的可变群卷积网络vargfacenet。VarGNet它引入了一种刻板的卷积来解决小计算和块内计算强度不平衡之间的冲突。
利用变群卷积方法设计了一个支持大规模人脸识别的网络,降低了计算量和参数。具体来说,作者在网络开始时设置了头部来保留基本信息,并提出了一种具体的嵌入方法来降低用于嵌入的全连接层的参数。
为了改进解释,作者使用等效角蒸馏损失来指导我们的轻量级网络,并应用递归知识蒸馏来减轻教师模型和学生模型之间的差异。值得一提的是,lfr(2019)挑战赛中,深灯田径冠军证明了该模式和方法的有效性。
许多工作已经导致轻量级网络用于常见的计算机视觉任务,如SqueezeNet, MobileNet, MobileNetV2, ShuffleNet, SqueezeNet.。他们使用了一个大的1x1卷积,与alexnet相比减少了50倍的参数,同时在imagenet上保持了alexnet级别的准确性。
MobileNet利用深度可分离卷积来实现计算时间和精度之间的权衡在此基础上,mobilenetv2提出了一种倒瓶颈结构来提高网络的识别能力。
shufflenet和shufflenetv2通过使用逐点卷积和信道随机操作进一步降低计算成本。尽管它们在推理过程中的计算量很小,在各种应用中都有很好的性能,但是嵌入式系统的优化问题仍然存在。
为了解决这一矛盾,vargnet提出了一种可变群卷积方法,有效地解决了块内部计算强度的不平衡问题。同时,探讨了在相同卷积核大小的情况下,变群卷积比深卷积具有更大的学习能力,有助于网络提取更多的信息。
然而,VarGNet是为图像分类和目标检测等常见任务而设计的它将头部的空间减少到一半以节省内存和计算成本,这不适合于人脸识别任务,因为它需要更详细的面部信息。此外,在最后一个conv和完全连接的层之间只有一个平均池层,并且可能无法提取足够的区分信息。
在vargnet的基础上,提出了一种有效的变群卷积轻量级人脸识别网络vargfacenet。为了提高VarGNet在大规模人脸识别任务中的识别能力,作者首先在VarGNet的块中加入SE块[13]和PReLU[8]然后,在网络开始时移除下采样过程以保留更多信息为了降低网络参数,作者在fc层之前使用可变群卷积将特征张量降到1x1x512。
VarGFaceNet的性能表明,该方法在降低网络参数的同时,保持了区分能力为了提高对轻量级网络的解释能力,我们在训练过程中采用了知识蒸馏的方法目前有几种方法可以使更深层次的网络更小、更有效,例如模型修剪、模型量化和知识提取。最近,ShrinkTeaNet引入了一个角度蒸馏损失来关注教师模型的视角。
受角蒸馏损失的启发,采用等效损失和更好的实现方法来指导vargfacenet。此外,为了减少教师模型与学生模型之间的优化复杂度,作者引入递归知识求精方法,将递归学生模型作为下一代预训练模型。
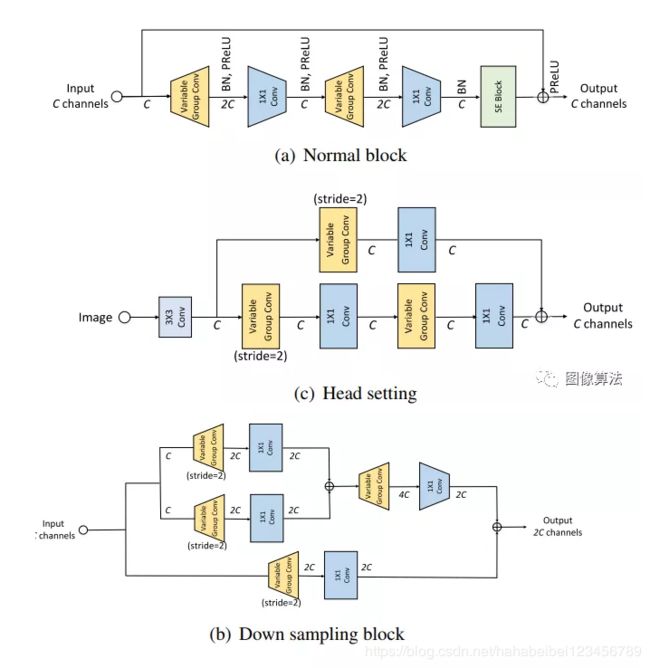
- 为了提高VarGNet在大规模人脸识别中的识别能力,采用了不同的头部,提出了一种新的嵌入式块在嵌入式模块中,首先通过1×1卷积层将信道扩展到1024,以保留基本信息,然后利用变群变换和逐点变换将空间域缩小到1×1,节省了计算量。如下所示,这样的操作可以提高人脸识别任务的性能。
- 为了提高轻量级模型的泛化能力,提出了一种递归知识提取方法,以缩小教师模型和学生模型之间的泛化差距。
方法
与vargnet不同,本文在网络的开头使用步长为1的3×3 conv,而不是在vargnet中使用步长为2的3×3 conv。vargnet中第一个转换的输出特性大小将减小,本文的输入特性大小将保持与输入大小相同,如图所示。说明了本文中轻量级网络(VarGFaceNet)的总体结构vargfacenet的内存占用为20M,触发器为1G。作者根据经验将s=8设为一组。由于可变组卷积、头部设置和特定的嵌入设置,vargfacenet可以在有限的计算成本和参数条件下实现良好的人脸识别性能。在第3节中,我们将演示我们的网络在数百万个干扰性面部识别任务中的有效性。
VarGFaceNet的总体架构。 它只有1G FLOP和5M参数(内存占用量为20M,另存为float32)。
实验
数据集和评估标准
以LFR2019的数据作为训练集万亿粒子是一个测试集,由两部分组成:celelfw和delfw。以TPR@FPR=1e-8为评价标准
从零开始训练瓦格法内特
为了验证VarGFaceNet网络的效率和有效性,作者对网络进行了从头训练,并将其性能与mobilefacenet(y2)进行了比较在训练过程中,以弧面损失作为分类的目标函数。表2列出了vargfacenet和y2。可见,在1g触发器的限制下,vargfacenet可以在验证集上获得更好的人脸识别性能。
对于性能改进,作者有两个共同的直觉:
1、当限制触发器时,本文的可变卷积网络可以包含比y2更多的参数。Y2信道最大数为256,信道最大数为320。
2、本文中的嵌入方法可以提取出更重要的信息。y2将信道数从256扩展到512,然后使用7×7的深度卷积得到fc层之前的特征张量。本文将信道数从320个扩展到1024个,然后采用变群卷积和网络容量较大的逐点卷积。
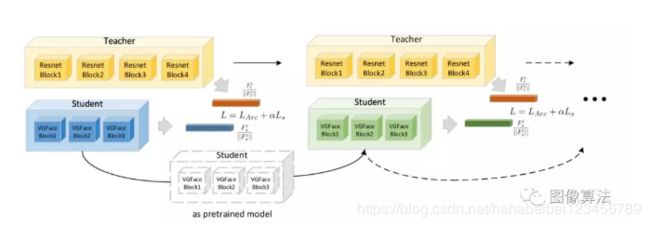
用resnet训练vargfacenet
为了获得比从头开始训练更高的性能,作者将角蒸馏损失函数用于知识蒸馏。实验研究了不同的教师模式对VarGFaceNet的影响结果见表3。可以看出:1。虽然师生结构完全不同,但vargfacenet仍然接近resnet的性能。vargfacenet的表现与教师模式高度相关。
递归知识蒸馏训练
当教师模式和学生模式之间存在巨大差异时,知识的一次提炼可能不足以进行知识转移。为了验证这一点,作者使用ResNet 100模型作为教师模型,并在VarGFaceNet上进行递归知识提取在训练下一个迭代模型时,性能改进如表5所示。lfw和cfpfp的变化增加了0.1%。
结论
在本文中,我们提出了一种有效的轻量级网络,称为VarGFaceNet,用于大规模人脸识别。受益于可变组卷积,VarGFaceNet是能够在效率和效率之间找到更好的折衷性能。面部识别专用的头部设置和嵌入设置有助于在保存信息的同时减少参数。此外,为了提高轻量级网络的解释能力,我们采用等价的角蒸馏损失作为我们的目标函数,并提出了递归知识蒸馏策略。
LFR挑战的最新性能证明了我们方法的优越性。
相关论文源码下载地址:关注“图像算法”微信公众号 回复“VarGFaceNet”