年龄及性别预测(2)AgeNet: Deeply Learned Regressor and Classifier for Robust Apparent Age Estimation
版权声明:本文为博主原创文章,码字不易,未经博主允许,不得转载:https://mp.csdn.net/postedit/79765765。
本篇文章:AgeNet: Deeply Learned Regressor and Classifier for Robust Apparent Age Estimation (点我下载)是2015 ChaLearn挑战赛(去这里摸索)表面年龄(年龄分类在上文中已经进行了说明)预测的第二名。
文章主要训练了一个由粗到精的端到端网络,能够在中型数据集上达到state-of-art的效果。
一、
先说一下用到的进行年龄估计的几个数据集以及它们各自的特点:
(1)Morph-II:仅仅包含犯罪嫌疑人的照片,照片中的任务年龄为真实年龄。由16-77岁的55135张图像组成(要钱,可以点我看下多少钱)
(2)FG-NET:仅仅有1002张图片,照片中的人物年龄为真实年龄。(点我)
(3)CASIA-WebFace:由10575个不同个体的500K张图像组成。(点我)
(4)CACD:由14-62岁之间的160K张图像组成,准确性见下一条。(点我)
(5)WebFaceAge:由1-82岁之间的600K张图像组成。这里的图像大多都是从网上扒取下来的,扒取的方式比较简单,比如输入“10岁”、“2010年出生的人”等,由这些结果图像组成。准确性不高,有噪声。(没找到链接,跪求有知情者提供!)
(6)ICCV2015 Looking at People Challenge:包含4699张图片,每张照片都由一个均值和方差进行标注(为什么是这样标注的请参考上文)
更多图像数据请参考https://zhuanlan.zhihu.com/p/25138563,值得收藏
二
文章提到,使用面部进行年龄估计包含两个关键步骤:
(1)年龄特征表达:这对于一般的视觉问题都存在,之前使用的方法都是利用人工设定的特征提取器来进行特征提取,但是这种方式很大程度上由特征提取器的特点所决定,往往能够在重点照顾某一方面的情况下,在其它方面表现并不是很好。这类特征提取器主要有(BIF、LBP、HOG等)。而使用深度学习的方法可以使网络能够更广泛的学习多种特征,不仅可以减少人工成本,而且提取出来的特征也比较具有通用性。
(2)年龄估计器的学习过程:年龄的估计划分为回归、分类、分类+回归等问题进行学习,但以往利用人工特征提取器进行提取的方法,其特征提取与年龄估计过程是分开的,也就是先利用一些特征提取器进行特征提取之后喂给神经网络或SVR等进行估计,这样做不好的一点是,最终的准确性依赖特征的选取,往往后面分类/回归器的学习无法反馈给特征提取器,从而不能根据估计的准确性来调整特征提取。这点类似于目标检测中RCNN和Fast RCNN的训练方法,不仅在特征提取阶段运算量大,而且容易产生冗余,而且后续的处理不能反馈到前面,从而效果一般。而通过使用深度神经网络则可以实现端到端的过程,从而提升估计的准确度。
三
本文提出的AgeNet便是利用神经网络实现了分类+回归的端到端的训练,主要有一下几个特点:
(1)网络利用分类+回归的思想,使用的网络是GoogLeNet(22层),对原始网络中的辅助损失层进行了删除,并且去掉了原始网络中所有的Dropout层,改为在每一个Relu激活函数层之前加入BN层。
(2)为了避免过拟合,使用了由一般到特殊的迁移学习
四
这里介绍一下关于年龄估计中的标签设定,因为无论是使用哪种方法,对于监督学习来说,势必存在一个对应的标签。而对于年龄估计来说,标签的编码有以下几种方法:
(1)1维真实年龄编码:(本文使用)这个容易理解,就是通过人实际年龄直接作为标签,比如真实年龄是20岁或30,那么标签就是20或30,这种编码方式在回归中较为常用
(2)0/1编码:这种编码方式在分类中较为常用,也就是所谓的one-hot编码。将每一个年龄都看做是一个一维的向量,每个向量中只有该年龄对应的位置处为1,其余为0。假设一个人的年龄为5岁,总共有10个年龄,那么对应的编码便为[0,0,0,0,1,0,0,0,0,0]。
(3)根据标签年龄分布编码:(本文使用)这种编码方式是由(文章Facial age estimation by learning from label distributions )提出的,总体思想是通过每个标签中的描述度来表示实例的标签。这个表述度论文中使用的是高斯标签分布。对于一个给定的图像I,假定其对应年龄的是y,那么就可以将这个标签表示为:

公式中,M表示的原始年龄标签中的最大年龄,![]() 表示的是标签的标准方差,y表示图像标签,j表示真实年龄。这样做的理由是:通常我们的0/1编码结合softmax损失进行分类时,是将所有的标签都同等对待,即我们认为每个标签之间都是相互独立的,彼此之间没有太大关系。但实际上在进行年龄分类的时候,如果有两个年龄40与41,那么我们很难去判断这个人到底是准确的40岁还是41岁,因为这个人可能是40岁零2个月。这两个年龄之间的界限并没有像40与80岁之间那么明确,反而相当模糊,在这种情况下,就不能简单的将两者分开对待,而是有一定的关联的。因此,这里采用了类似高斯映射的方式将标签进行了转化。
表示的是标签的标准方差,y表示图像标签,j表示真实年龄。这样做的理由是:通常我们的0/1编码结合softmax损失进行分类时,是将所有的标签都同等对待,即我们认为每个标签之间都是相互独立的,彼此之间没有太大关系。但实际上在进行年龄分类的时候,如果有两个年龄40与41,那么我们很难去判断这个人到底是准确的40岁还是41岁,因为这个人可能是40岁零2个月。这两个年龄之间的界限并没有像40与80岁之间那么明确,反而相当模糊,在这种情况下,就不能简单的将两者分开对待,而是有一定的关联的。因此,这里采用了类似高斯映射的方式将标签进行了转化。
五
介绍一下网络的训练方法:
(1)年龄回归器训练:
这里采用了回归的方法,首先将原始网络的最后一层修改为一个神经节点,并且采用sigmoid激活函数,这样可以将结果限制在[0,1]之间。那么也需要将年龄标签归一化[0,1]之间以使得他们具有相同的尺度,不然损失函数将无法计算。标签归一化的方法是将所有年龄都除以100。
然后使用欧氏距离来作为损失函数进行反向传播。

这里的N表示一个batch的size,两个y就不说了。
其中有一个重点需要进行说明:论文中使用的数据集的最大年龄标签为85岁,将其进行归一化的时候是除以100的(一般进行归一化的时候都是除以数据中的最大值85,不太理解这里为什么除以100),那么在最终年龄估计的时候,估计年龄应该为:
![]()
其中的f函数表示取式中计算结果的下限,比如计算结果为72.7岁,那么结果应该是不大于它的最大整数,即72
(2)年龄分类器训练:
前文说了,文章采用了年龄描述度标签,这里采用了交叉熵来作为损失函数进行训练。

式中的p(in)表示经过标签经过描述度编码后的年龄,范围为[0,1]。p_hat(in)表示网络的输出,N表示一个batchsize,L表示年龄描述度标签的长度。
最终年龄估计的结果为网络结果中,最大置信度所对应的标签即为估计结果。
![]()
六
网络训练的步骤:
(1)由于人脸的数据集都规模不大(注意,这里IMDB-WIKI数据集应该没有公布,因为两者是同一年进行的比赛,应该不会共享数据的)首先在大型人脸识别数据集CASIA-WebFace进行了预训练。主要是因为人脸识别与人脸年龄估计都用到了人脸特征,因此在人脸识别数据集上进行预训练可以更好的提取人脸的特征,这种初始化方式势必比随机初始化更好,不容易发生严重的过拟合。
(2)利用包含真实年龄的数据集进行微调。真实年龄估计和表面年龄估计虽然不一样,但两者还是存在很多相似性的。文章在CACD、Morph-II、WebFaceAge上进行了微调。上面提到的分类器和回归器便是在这里进行了的学习。
(3)利用比赛数据进行微调。
全部流程如下图:

对几种方式进行不同组合的预训练所得到的精度提升如下:
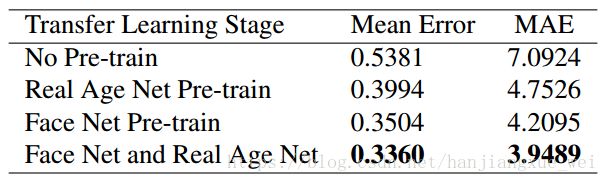
七
脸部预处理:
(1)面部提取:利用VIPL 实验室研发的脸部探测器CAS进行了面部提取。
(2)脸部特征点定位:使用Coarse-to-Fine Auto-Encoder Network(CFAN)检测了脸部的五个特征点,分别是左右眼中心,鼻尖,嘴部左右角。
(3)面部标准化:这里使用了内标准化(翻译不一定正确)与外标准化两种方式,其中外标准化的方式不仅包含了脸部的固有信息,而且也包含了整体的上下文信息;内标准化只包含了面部信息。然后将标准化之后的图像进行了256*256的resize,下面是两种标准化的结果。(恕奴才眼拙,看不出来啊!)

八
集成学习:
最终的年龄预测是8个网络的平均。具体每个网络如下图:
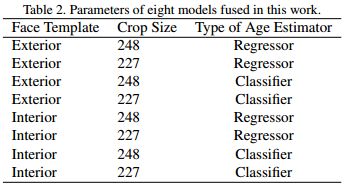
可以看到,这里进行了不同的模型集成,既结合了分类器与回归器的结果,又结合了外部和内部标准化两种方式,同时,对图像大小进行了不同尺寸的裁剪。
实验结果:
直接上图

这里的评价标准在上文中已进行了说明。
这在上文中进行了说明。
从图中可以看到:
(1)使用0/1编码方式进行预测的准确率明显低于经过描述度编码的方式。
(2)对于248*248大小图像来说,无论是内部标准化还是外部标准化的方式,单独的回归器比分类器效果要好(一点点),对于227*227恰好相反。
(3)无论是标准化方式集成还是分类器、回归器集成,都能够显著提高算法精确度
(4)当然,最好的还是将上面的八种方式都结合起来取个平均的方法。
九
训练过程:
基础学习率设为0.01,学习率递减设置伽马值为0.5,动量项设置为0.9,权重衰减设为0.0005
(1)在人脸识别数据集训练时采用的batch size 为24,迭代320k次
(2)在实际年龄数据集上训练采用batch size 为50, 迭代100k次
(3)在比赛数据集上进行训练采用batch size 为50,迭代10k次(每个模型,总体为10k*8)
下图为年龄估计的最终效果展示:

从图中可以看出,算法对于姿势、光照、种族、颜色等不同表现都较好,但是对于面部模糊、校准失败和年长的人预测效果一般(不过虽然一般,但是对于年长的人来说,最起码趋势是预测年龄较高,而不至于差距太大)。
个人看法:
这篇文章相对来说容易实现一些,训练时间也不是很长,在能够接受的范围内。
创新点感觉没有太多,尤其在网络方面。但感觉其在处理脸部数据,标签数据处理方面的利用是其成功的一大半。
这篇文章有部分不懂的地方,可能表达不太正确,需要查资料,将来有机会再进行补充与更正。
希望朋友们能够指出来进行探讨。