基本语料库函数

1.古腾堡语料库
print(nltk.corpus.gutenberg.fileids())
emma = nltk.corpus.gutenberg.words('austen-emma.txt')
print(emma[:50])
print(len(emma))
- nltk.Text操作(详情可参考)进行初级的统计与分析
emma = nltk.Text(nltk.corpus.gutenberg.words('austen-emma.txt'))
print(emma)
print(emma.concordance("surprize"))
from nltk.corpus import gutenberg
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid))
num_words = len(gutenberg.words(fileid))
num_sents = len(gutenberg.sents(fileid))
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)]))
print(int(num_chars/num_words), int(num_words/num_sents), int(num_words/num_vocab), fileid)
macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt')
longest_len = max([len(s) for s in macbeth_sentences])
print([s for s in macbeth_sentences if len(s) == longest_len])
2.网络和聊天语料库
from nltk.corpus import webtext
webtext.fileids()
for fileid in webtext.fileids():
print(fileid, webtext.raw(fileid)[:65], '...')
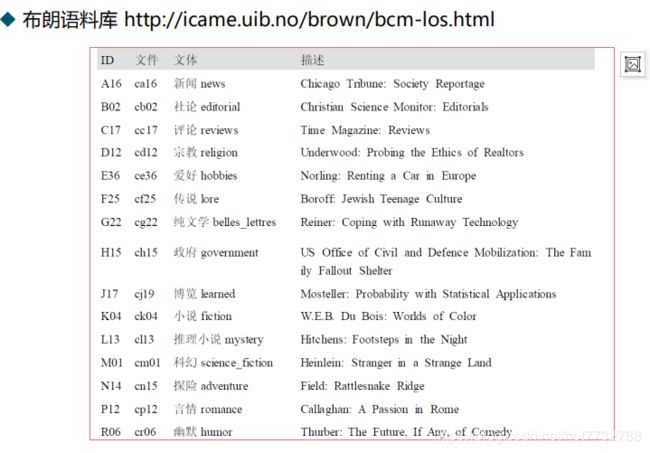
3.布朗语料库(第一个百万级的电子语料库)-用于研究不同文体之间的差异
from nltk.corpus import brown
print(brown.categories())
print(brown.words(categories='news'))
print(brown.words(fileids=['cg22']))
print(brown.sents(categories=['news', 'editorial', 'reviews']))
import nltk
from nltk.corpus import brown
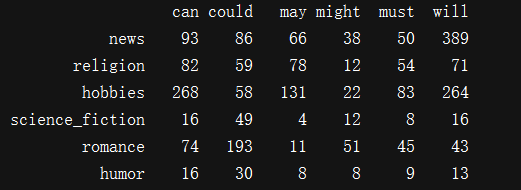
news_text = brown.words(categories='news')
fdist = nltk.FreqDist([w.lower() for w in news_text])
modals = ['can', 'could', 'may', 'might', 'must', 'will']
for m in modals:
print(m + ':', fdist[m],)
import nltk
from nltk.corpus import brown
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories=genre))
genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
cfd.tabulate(conditions=genres, samples=modals)
4.路透社语料库
from nltk.corpus import reuters
print(len(reuters.fileids()))
print(len(reuters.categories()))
reuters.categories('training/9865')
reuters.categories(['training/9865', 'training/9880'])
reuters.fileids('barley')
5.美国不同年份总统就职演讲语料库
from nltk.corpus import inaugural
import nltk
inaugural.fileids()
print([fileid[:4] for fileid in inaugural.fileids()])
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
cfd.plot()
6.载入自己的语料库
from nltk.corpus import PlaintextCorpusReader
corpus_root = './training'
wordlists = PlaintextCorpusReader(corpus_root, ['pku_training.utf8','cityu_training.utf8','msr_training.utf8','pku_training.utf8'])
print(wordlists.fileids())
print(wordlists.raw('pku_training.utf8'))
print(len(wordlists.words('pku_training.utf8')))
print(len(wordlists.sents('pku_training.utf8')))
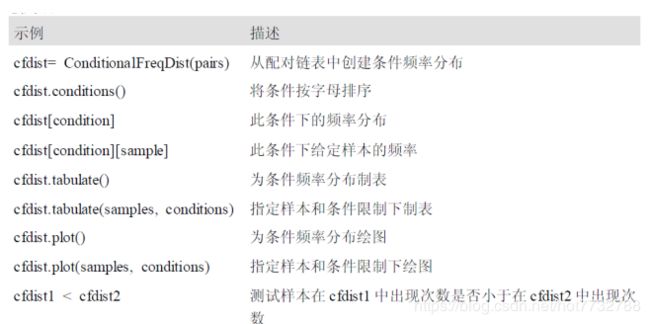
7.条件频率分布,以及绘制分布图,分布表
from nltk.corpus import brown
import nltk
genre_word = [(genre, word)
for genre in ['news', 'romance']
for word in brown.words(categories=genre)]
cfd = nltk.ConditionalFreqDist(genre_word)
print(cfd.items())
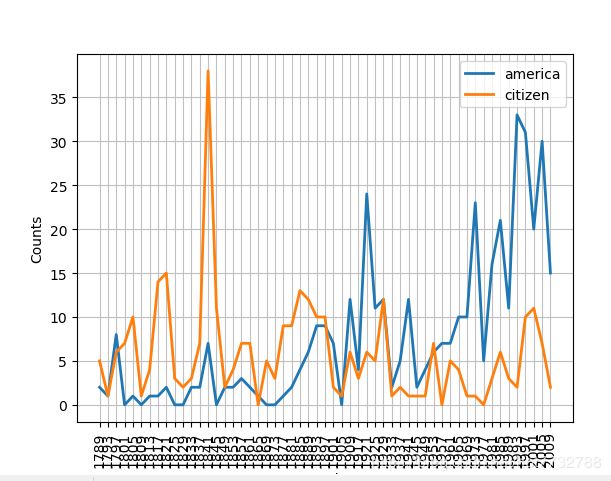
from nltk.corpus import inaugural
import nltk
cfd = nltk.ConditionalFreqDist(
(target, fileid[:4])
for fileid in inaugural.fileids()
for w in inaugural.words(fileid)
for target in ['america', 'citizen']
if w.lower().startswith(target))
cfd.plot()
from nltk.corpus import udhr
import nltk
languages = ['Chickasaw', 'English', 'German_Deutsch',
'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
udhr.fileids()
cfd = nltk.ConditionalFreqDist(
(lang, len(word))
for lang in languages
for word in udhr.words(lang + '-Latin1'))
cfd.tabulate(conditions=['English', 'German_Deutsch'],
samples=range(10), cumulative=True)

8.使用双连词生成随机文本
import nltk
sent = ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven',
'and', 'the', 'earth', '.']
print([i for i in nltk.bigrams(sent)])
def generate_model(cfdist, word, num=15):
for i in range(num):
print(word)
word = cfdist[word].max()
text = nltk.corpus.genesis.words('english-kjv.txt')
bigrams = nltk.bigrams(text)
cfd = nltk.ConditionalFreqDist(bigrams)
generate_model(cfd, 'living')
