《机器学习实战》完整总结
1.首先从图片的角度,对机器学习算法、实战有一个全面而感性的认识。
1.1 机器学习算法思维导图
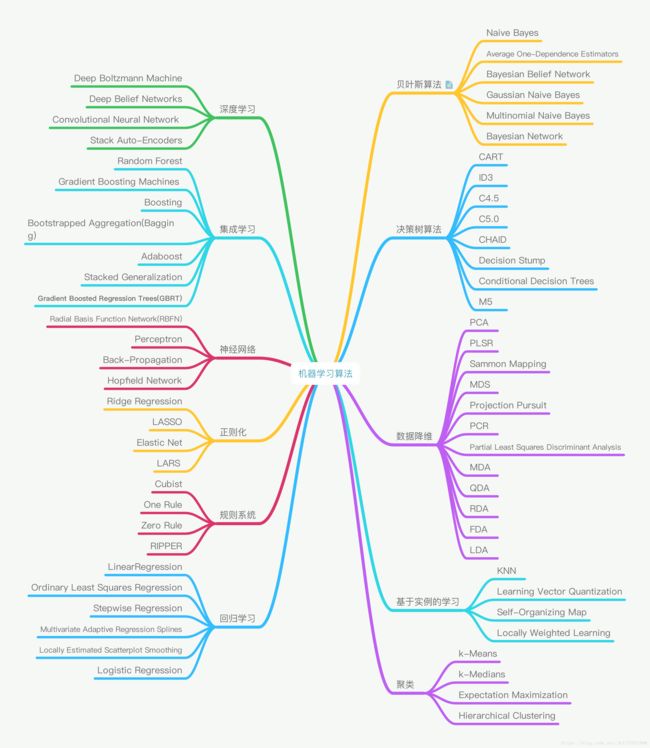
1.2 监督学习经典模型树状图

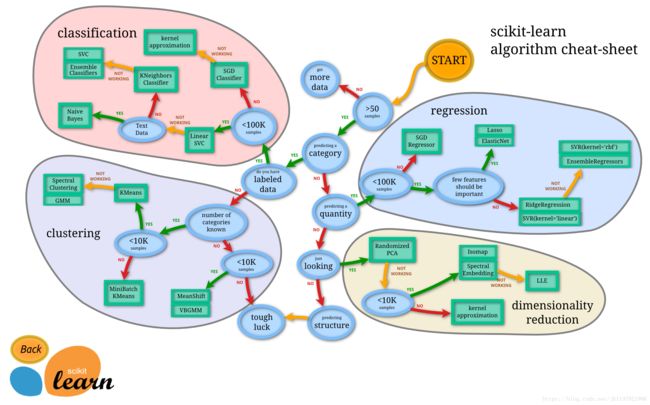
1.3 Scikit-learn工具包使用网状图
1.4 监督学习流程图
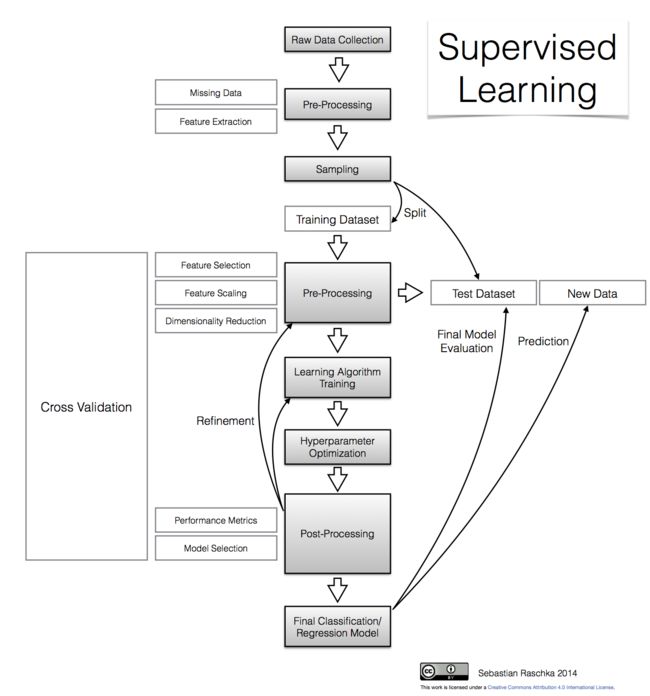
2.剖析监督学习流程图的每一个步骤(by code)。
2.1 原始数据收集
(1)导入本地数据:
import pandas as pd
train = pd.read_csv('../Breast-Cancer/breast-cancer-train.csv')
test = pd.read_csv('../Breast-Cancer/breast-cancer-test.csv')
(2)在线获取数据
import pandas as pd
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
(3)导入sklearn模块自带的数据集
from sklearn.datasets import load_boston,load_digits,fetch_20newsgroups
boston = load_boston()
#查看数据说明(DESCR)
print boston.DESCR
digits = load_digits()
#查看数据规模和特征维度
print digits.data.shape
#与之前预存的数据不同,fetch_20newsgroups需要即时从互联网下载数据
news=fetch_20newsgroups(subset='all')
#查验数据规模和细节
print len(news.data)
print news.data[0]
2.2 数据预处理
- 处理缺失数据
(1)泰坦尼克号乘客数据中,对缺失的乘客年龄进行处理
#这里是先完成了特征提取,然后再处理的 missing data
X['age'].fillna(X['age'].mean(),inplace=True)
(2)在肿瘤分类任务中,将原始数据数据缺失值进行处理
#将?替换为标准缺失值
data = data.replace(to_replace='?',value=np.nan)
#丢失带有缺失值的数据(只要有一个纬度缺失就舍弃)
data = data.dropna(how='any')
- 特征提取(选取数据样本中的重要特征)
(1)泰坦尼克号乘客数据中,选取对结果影响比较大的几个特征组成数据样本X,y
X = titanic[['pclass','sex','age']]
y = titanic['survived']
(2)手写体数字图像的数据,利用数据的维度,获取X,y
X_train = digits_train[np.arange(64)]
y_train = digits_train[64]
X_test = digits_test[np.arange(64)]
y_test = digits_test[64]
2.3 采样(数据分割)
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
2.4 数据进一步预处理
- 特征抽取(将原始数据转化为特征向量的形式)
#1.用CountVectorizer提取特征(词袋法)
from sklearn.feature_extraction.text import CountVectorizer
count_vec=CountVectorizer()
X_count_train = count_vec.fit_transform(X_train)
X_count_test = count_vec.transform(X_test)
#2.用TfidfVectorizer提取特征
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer()
X_tfidf_train = tfidf_vec.fit_transform(X_train)
X_tfidf_test = tfidf_vec.transform(X_test)
#3.使用DictVectorizer将类别型特征转换成0/1型
from sklearn.feature_extraction import DictVectorizer
#sparse=False指不用稀疏矩阵表示
vec = DictVectorizer(sparse=False)
#转换特征之后,我们发现凡是类别型的特征都单独剥离出来,独自构成一列特征,数值型特征则保持不变,如sex分割成'sex=female', 'sex=male'两列
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.fit_transform(X_test.to_dict(orient='record'))
- 特征筛选(在高维度、已量化的特征向量中选择更有效的特征组合)
# 从sklearn导入特征筛选器
from sklearn import feature_selection
# 筛选特征向量表现最好的前20%个特征,使用相同配置的决策树模型进行预测,并且评估性能
fs = feature_selection.SelectPercentile(feature_selection.chi2,percentile=20)
#注意此处的fit_transform参数,是两个值,不再只是X_train
X_train_fs = fs.fit_transform(X_train,y_train)
- 特征标准化(使得预测结果不会被某些维度过大的特征值所主导)
from sklearn.preprocessing import StandardScaler
ss=StandardScaler()
#注意,X_train与X_test的标准化方法不同
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
- 特征降维(将高维度的特征空间映射到低维度的空间,尽可能的保证数据的多样性)
from sklearn.decomposition import PCA
#初始化一个可以将高维度的特征向量(64维)压缩至两个维度的PCA
estimator = PCA(n_components=2)
X_pca = estimator.fit_transform(X_digits)
2.5 学习算法训练
#1.线性分类器模型训练
from sklearn.linear_model import LogisticRegression,SGDClassifier
lr=LogisticRegression()
lr.fit(X_train,y_train)
sgdc=SGDClassifier()
sgdc.fit(X_train,y_train)
#2.使用kernel='linear'配置的SVC模型训练
from sklearn.svm import SVC
linear_svc = SVC(kernel='linear')
linear_svc.fit(X_train,y_train)
#3.朴素贝叶斯模型训练
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(X_train,y_train)
#4.K近邻(回归)模型训练
from sklearn.neighbors import KNeighborsClassifier
knc = KNeighborsClassifier()
knc.fit(X_train,y_train)
#5.决策树分类器模型训练
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train,y_train)
#6.集成模型(分类)训练
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train,y_train)
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier()
gbc.fit(X_train,y_train)
······
2.6 超参数优化 (模型配置,我们一般统称为模型的超参数)
#以下给出一个超参数搜索的例子,返回模型性能最好的超参数
from sklearn.pipeline import Pipeline
clf = Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())])
parameters = {'svc__gamma':np.logspace(-2,1,4),'svc__C':np.logspace(-1,1,3)}
from sklearn.grid_search import GridSearchCV
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3)
#执行单线程网格搜索
gs.fit(X_train,y_train)
print gs.best_params_,gs.best_score_
2.7 后期处理
- 性能评估
(1)分类模型评估:
#使用sklearn.metrics中的classification_report模块对肿瘤预测模型的性能进行分析
from sklearn.metrics import classification_report
#1.使用逻辑回归模型自带的评分函数score获得模型在测试集上对准确性结果
print 'Accuracy Of LR:',lr.score(X_test,y_test)
#利用classification_report模块获得LR的其他三个指标(pression,recall,f1 score)
print classification_report(y_test,lr_y_predict,target_names=['Bebign','Malignat'])
#2.使用SGD模型自带的评分函数score获得模型在测试集上的准确性结果
print 'Accuracy Of SGD:',sgdc.score(X_test,y_test)
#利用classification_report模块获得LR的其他三个指标(pression,recall,f1 score)
print classification_report(y_test,sgdc_y_predict,target_names=['Bebign','Malignat'])
(2)回归模型评估:
#使用SGDRegressor自带的评估模块,并输出评估结果
print 'the value of default measurement of SGDR:',sgdr.score(X_test,y_test)
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
print 'the value of R-squared of SGDR is',r2_score(y_test,sgdr_y_predict)
print 'the MSE of SGDR is',mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(sgdr_y_predict))
print 'the MAE of SGDR is',mean_absolute_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(sgdr_y_predict))
#回归模型自带的评估结果与r2_score的值是一样的,推荐使用第一种方式
- 模型选择
通过交叉验证的方式,选择性能表现最稳定,预测准确性最好的模型。
2.8 选定最终的分类/回归模型
2.9 将交叉验证后,性能表现最好的几个模型,放在测试集上评估
2.10在测试集上,表现最佳的模型,用来预测未知新数据