一步一步学linux操作系统: 15 进程是如何创建的_fork都做了些什么
fork 系统调用
fork 是一个系统调用,glibc中传入fork系统调用号给DO_CALL,DO_CALL在32位系统中通过软中断进入内核,在64位系通过syscall 指令进入内核,并在内核的系统调用表中找到对应函数并执行 参看 06 系统调用https://blog.csdn.net/leacock1991/article/details/106773065
最后会在 sys_call_table 中找到相应的系统调用 sys_fork。

sys_fork 会调用 _do_fork
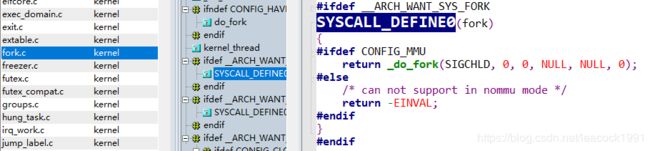
\kernel\fork.c
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
_do_fork函数
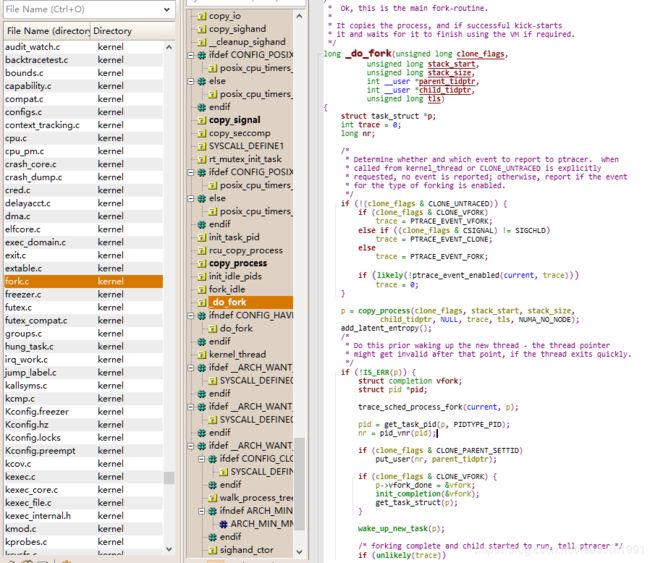
\kernel\fork.c
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
......
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......
if (!IS_ERR(p)) {
struct pid *pid;
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
......
wake_up_new_task(p);
......
put_pid(pid);
}
......
fork 的第一件大事:复制结构
task_struct 的结构图
函数 copy_process(_do_fork)
\kernel\fork.c
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
int retval;
struct task_struct *p;
......
p = dup_task_struct(current, node);

dup_task_struct 函数( copy_process) task_struct 结构相关
\kernel\fork.c
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
struct task_struct *tsk;
unsigned long *stack;
struct vm_struct *stack_vm_area;
int err;
......
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
stack = alloc_thread_stack_node(tsk, node);
if (!stack)
goto free_tsk;
stack_vm_area = task_stack_vm_area(tsk);
err = arch_dup_task_struct(tsk, orig);
......
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
set_task_stack_end_magic(tsk);
......
}

- 调用 alloc_task_struct_node 分配一个 task_struct 结构;
- 调用 alloc_thread_stack_node 来创建内核栈,这里面调用 __vmalloc_node_range 分配一个连续的 THREAD_SIZE 的内存空间,赋值给 task_struct 的 void *stack 成员变量;
- 调用 arch_dup_task_struct(struct task_struct *dst, struct task_struct *src),调用 memcpy将 task_struct 进行复制
alloc_thread_stack_node 函数(dup_task_struct)
\kernel\fork.c
static unsigned long *alloc_thread_stack_node(struct task_struct *tsk, int node)
{
#ifdef CONFIG_VMAP_STACK
void *stack;
int i;
for (i = 0; i < NR_CACHED_STACKS; i++) {
struct vm_struct *s;
s = this_cpu_xchg(cached_stacks[i], NULL);
if (!s)
continue;
tsk->stack_vm_area = s;
return s->addr;
}
stack = __vmalloc_node_range(THREAD_SIZE, THREAD_SIZE,
VMALLOC_START, VMALLOC_END,
THREADINFO_GFP,
PAGE_KERNEL,
0, node, __builtin_return_address(0));
/*
* We can't call find_vm_area() in interrupt context, and
* free_thread_stack() can be called in interrupt context,
* so cache the vm_struct.
*/
if (stack)
tsk->stack_vm_area = find_vm_area(stack);
return stack;
#else
struct page *page = alloc_pages_node(node, THREADINFO_GFP,
THREAD_SIZE_ORDER);
return page ? page_address(page) : NULL;
#endif
}

- 调用 setup_thread_stack 设置 thread_info
- 到这里,整个 task_struct 复制了一份,而且内核栈也创建好了
copy_creds 函数( copy_process) 权限相关
\kernel\fork.c
/*
* Copy credentials for the new process created by fork()
*
* We share if we can, but under some circumstances we have to generate a new
* set.
*
* The new process gets the current process's subjective credentials as its
* objective and subjective credentials
*/
int copy_creds(struct task_struct *p, unsigned long clone_flags)
{
struct cred *new;
int ret;
......
new = prepare_creds();
if (!new)
return -ENOMEM;
......
p->cred = p->real_cred = get_cred(new);
alter_cred_subscribers(new, 2);
......
}
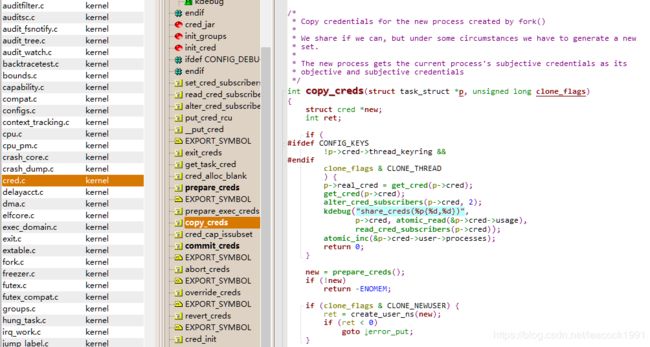
调用 prepare_creds,准备一个新的 struct cred *new
其实还是从内存中分配一个新的 struct cred 结构,然后调用 memcpy 复制一份父进程的 cred
prepare_creds 函数
\kernel\cred.c
/**
* prepare_creds - Prepare a new set of credentials for modification
*
* Prepare a new set of task credentials for modification. A task's creds
* shouldn't generally be modified directly, therefore this function is used to
* prepare a new copy, which the caller then modifies and then commits by
* calling commit_creds().
*
* Preparation involves making a copy of the objective creds for modification.
*
* Returns a pointer to the new creds-to-be if successful, NULL otherwise.
*
* Call commit_creds() or abort_creds() to clean up.
*/
struct cred *prepare_creds(void)
{
struct task_struct *task = current;
const struct cred *old;
struct cred *new;
validate_process_creds();
new = kmem_cache_alloc(cred_jar, GFP_KERNEL);
if (!new)
return NULL;
kdebug("prepare_creds() alloc %p", new);
old = task->cred;
memcpy(new, old, sizeof(struct cred));
atomic_set(&new->usage, 1);
set_cred_subscribers(new, 0);
get_group_info(new->group_info);
get_uid(new->user);
get_user_ns(new->user_ns);
......
}
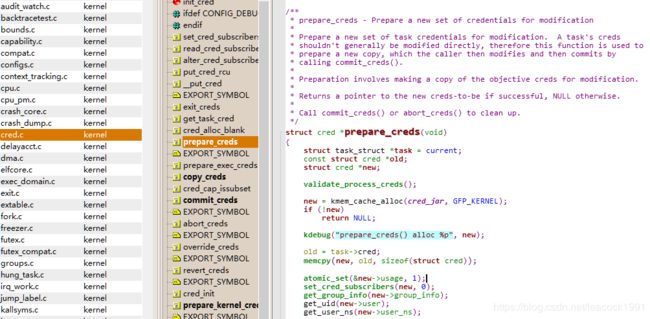
接着 p->cred = p->real_cred = get_cred(new),将新进程的“我能操作谁”和“谁能操作我”两个权限都指向新的 cred。
进程运行的统计量相关
p->utime = p->stime = p->gtime = 0;
p->start_time = ktime_get_ns();
p->real_start_time = ktime_get_boot_ns();
sched_fork 函数 ( copy_process)调度相关
\kernel\sched\core.c
/*
* fork()/clone()-time setup:
*/
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(clone_flags, p);
/*
* We mark the process as NEW here. This guarantees that
* nobody will actually run it, and a signal or other external
* event cannot wake it up and insert it on the runqueue either.
*/
p->state = TASK_NEW;
/*
* Make sure we do not leak PI boosting priority to the child.
*/
p->prio = current->normal_prio;
/*
* Revert to default priority/policy on fork if requested.
*/
if (unlikely(p->sched_reset_on_fork)) {
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->policy = SCHED_NORMAL;
p->static_prio = NICE_TO_PRIO(0);
p->rt_priority = 0;
} else if (PRIO_TO_NICE(p->static_prio) < 0)
p->static_prio = NICE_TO_PRIO(0);
p->prio = p->normal_prio = __normal_prio(p);
set_load_weight(p);
/*
* We don't need the reset flag anymore after the fork. It has
* fulfilled its duty:
*/
p->sched_reset_on_fork = 0;
}
if (dl_prio(p->prio)) {
put_cpu();
return -EAGAIN;
} else if (rt_prio(p->prio)) {
p->sched_class = &rt_sched_class;
} else {
p->sched_class = &fair_sched_class;
}
init_entity_runnable_average(&p->se);
......
__set_task_cpu(p, cpu);
if (p->sched_class->task_fork)
p->sched_class->task_fork(p);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
......
}
- 调用 __sched_fork
__sched_fork 函数(sched_fork)
\kernel\sched\core.c
/*
* Perform scheduler related setup for a newly forked process p.
* p is forked by current.
*
* __sched_fork() is basic setup used by init_idle() too:
*/
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
INIT_LIST_HEAD(&p->se.group_node);
......
}

在这里面将 on_rq 设为 0,初始化 sched_entity,将里面的 exec_start、sum_exec_runtime、prev_sum_exec_runtime、vruntime 都设为 0。还这几个变量涉及进程的实际运行时间和虚拟运行时间
- 设置进程的状态 p->state = TASK_NEW;
- 初始化优先级 prio、normal_prio、static_prio;
- 设置调度类,如果是普通进程,就设置为 p->sched_class = &fair_sched_class
- 调用调度类的 task_fork 函数,对于 CFS 来讲,就是调用 task_fork_fair
task_fork_fair 函数 (sched_fork)
\kernel\sched\fair.c
/*
* called on fork with the child task as argument from the parent's context
* - child not yet on the tasklist
* - preemption disabled
*/
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
struct rq *rq = this_rq();
struct rq_flags rf;
rq_lock(rq, &rf);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current);
curr = cfs_rq->curr;
if (curr) {
update_curr(cfs_rq);
se->vruntime = curr->vruntime;
}
place_entity(cfs_rq, se, 1);
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
/*
* Upon rescheduling, sched_class::put_prev_task() will place
* 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime;
rq_unlock(rq, &rf);
}
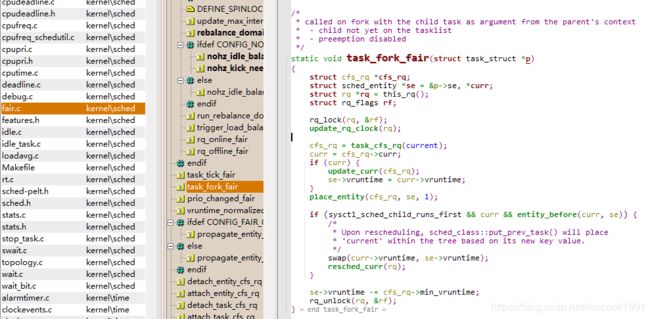
在这个函数里,先调用 update_curr,对于当前的进程进行统计量更新,把子进程和父进程的 vruntime 设成一样,最后调用 place_entity,初始化 sched_entity。
sysctl_sched_child_runs_first 变量 设置父进程和子进程谁先运行
初始化与文件和文件系统相关的变量
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
copy_files 函数
\kernel\fork.c
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{
struct files_struct *oldf, *newf;
int error = 0;
/*
* A background process may not have any files ...
*/
oldf = current->files;
if (!oldf)
goto out;
if (clone_flags & CLONE_FILES) {
atomic_inc(&oldf->count);
goto out;
}
newf = dup_fd(oldf, &error);
if (!newf)
goto out;
tsk->files = newf;
error = 0;
out:
return error;
}

copy_files 主要用于复制一个进程打开的文件信息。这些信息用一个结构 files_struct 来维护,每个打开的文件都有一个文件描述符。
在 copy_files 函数里面调用 dup_fd,在这里面会创建一个新的 files_struct,然后将所有的文件描述符数组 fdtable 拷贝一份。
copy_fs 函数
\kernel\fork.c
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
/* tsk->fs is already what we want */
spin_lock(&fs->lock);
if (fs->in_exec) {
spin_unlock(&fs->lock);
return -EAGAIN;
}
fs->users++;
spin_unlock(&fs->lock);
return 0;
}
tsk->fs = copy_fs_struct(fs);
if (!tsk->fs)
return -ENOMEM;
return 0;
}

copy_fs 主要用于复制一个进程的目录信息。这些信息用一个结构 fs_struct 来维护。一个进程有自己的根目录和根文件系统 root,也有当前目录 pwd 和当前目录的文件系统,都在 fs_struct 里面维护。
copy_fs 函数里面调用 copy_fs_struct,创建一个新的 fs_struct,并复制原来进程的 fs_struct。
初始化与信号相关的变量
init_sigpending(&p->pending);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
init_sigpending 和 copy_signal 用于初始化,并且复制用于维护发给这个进程的信号的数据结构
init_sigpending 函数
\include\linux\signal.h
static inline void init_sigpending(struct sigpending *sig)
{
sigemptyset(&sig->signal);
INIT_LIST_HEAD(&sig->list);
}

copy_sighand 函数
\kernel\fork.c
static int copy_sighand(unsigned long clone_flags, struct task_struct *tsk)
{
struct sighand_struct *sig;
if (clone_flags & CLONE_SIGHAND) {
atomic_inc(¤t->sighand->count);
return 0;
}
sig = kmem_cache_alloc(sighand_cachep, GFP_KERNEL);
rcu_assign_pointer(tsk->sighand, sig);
if (!sig)
return -ENOMEM;
atomic_set(&sig->count, 1);
memcpy(sig->action, current->sighand->action, sizeof(sig->action));
return 0;
}
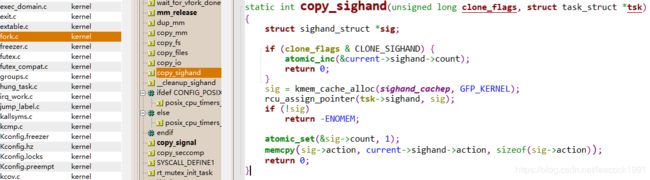
copy_sighand 会分配一个新的 sighand_struct并维护信号处理函数,调用 memcpy,将信号处理函数 sighand->action 从父进程复制到子进程。
copy_signal 函数
\kernel\fork.c
static int copy_signal(unsigned long clone_flags, struct task_struct *tsk)
{
struct signal_struct *sig;
if (clone_flags & CLONE_THREAD)
return 0;
sig = kmem_cache_zalloc(signal_cachep, GFP_KERNEL);
tsk->signal = sig;
if (!sig)
return -ENOMEM;
sig->nr_threads = 1;
atomic_set(&sig->live, 1);
atomic_set(&sig->sigcnt, 1);
/* list_add(thread_node, thread_head) without INIT_LIST_HEAD() */
sig->thread_head = (struct list_head)LIST_HEAD_INIT(tsk->thread_node);
tsk->thread_node = (struct list_head)LIST_HEAD_INIT(sig->thread_head);
init_waitqueue_head(&sig->wait_chldexit);
sig->curr_target = tsk;
init_sigpending(&sig->shared_pending);
seqlock_init(&sig->stats_lock);
prev_cputime_init(&sig->prev_cputime);
#ifdef CONFIG_POSIX_TIMERS
INIT_LIST_HEAD(&sig->posix_timers);
hrtimer_init(&sig->real_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
sig->real_timer.function = it_real_fn;
#endif
task_lock(current->group_leader);
memcpy(sig->rlim, current->signal->rlim, sizeof sig->rlim);
task_unlock(current->group_leader);
posix_cpu_timers_init_group(sig);
tty_audit_fork(sig);
sched_autogroup_fork(sig);
sig->oom_score_adj = current->signal->oom_score_adj;
sig->oom_score_adj_min = current->signal->oom_score_adj_min;
mutex_init(&sig->cred_guard_mutex);
return 0;
}
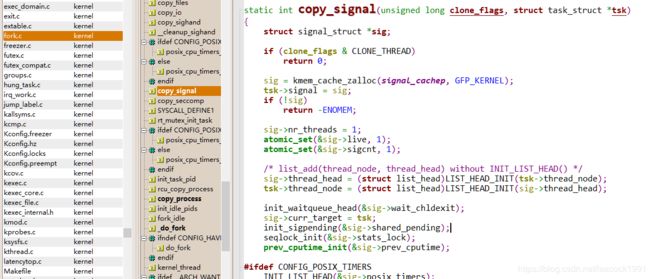
copy_signal 函数会分配一个新的 signal_struct,并进行初始化。
copy_mm 函数( copy_process)复制进程内存空间
\kernel\fork.c
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)
return 0;
/* initialize the new vmacache entries */
vmacache_flush(tsk);
if (clone_flags & CLONE_VM) {
mmget(oldmm);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
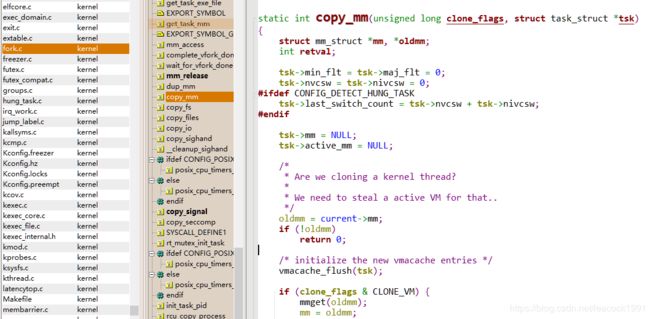
mm_struct 结构表示进程的内存空间
copy_mm 函数中调用 dup_mm,分配一个新的 mm_struct 结构,调用 memcpy 复制这个结构
dup_mmap 用于复制内存空间中内存映射的部分。
copy_process 分配 pid,设置 tid,group_leader,并且建立进程之间的亲缘关系。
\kernel\fork.c
copy_process 函数
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
......
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
......
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
fork 的第二件大事:唤醒新进程
函数 wake_up_new_task (_do_fork)
\kernel\sched\core.c
/*
1. wake_up_new_task - wake up a newly created task for the first time.
2. 3. This function will do some initial scheduler statistics housekeeping
3. that must be done for every newly created context, then puts the task
4. on the runqueue and wakes it.
*/
void wake_up_new_task(struct task_struct *p)
{
struct rq_flags rf;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, rf.flags);
p->state = TASK_RUNNING;
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected CPU might disappear through hotplug
*
* Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,
* as we're not fully set-up yet.
*/
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p, &rf);
update_rq_clock(rq);
post_init_entity_util_avg(&p->se);
activate_task(rq, p, ENQUEUE_NOCLOCK);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
/*
* Nothing relies on rq->lock after this, so its fine to
* drop it.
*/
rq_unpin_lock(rq, &rf);
p->sched_class->task_woken(rq, p);
rq_repin_lock(rq, &rf);
}
#endif
task_rq_unlock(rq, p, &rf);
}
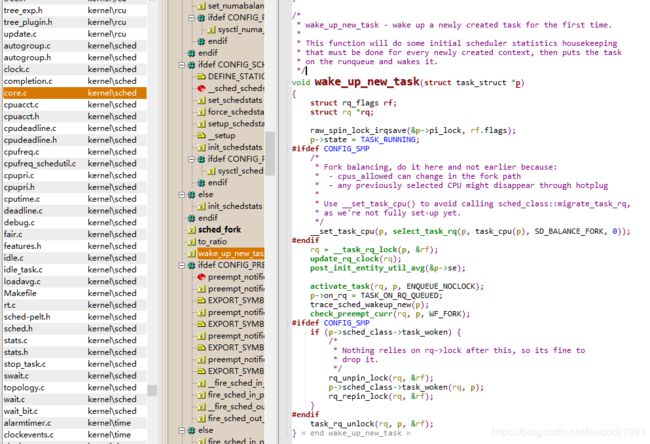
-
将进程的状态设置为 TASK_RUNNING
-
调用 activate_task 函数进而调用调用 enqueue_task
activate_task 函数
\kernel\sched\core.c
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible--;
enqueue_task(rq, p, flags);
}

enqueue_task 函数
\kernel\sched\core.c
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
if (!(flags & ENQUEUE_NOCLOCK))
update_rq_clock(rq);
if (!(flags & ENQUEUE_RESTORE))
sched_info_queued(rq, p);
p->sched_class->enqueue_task(rq, p, flags);
}

如果是 CFS 的调度类,则执行相应的 enqueue_task_fair
** enqueue_task_fair 函数 (enqueue_task )**
kernel\sched\fair.c
/*
* The enqueue_task method is called before nr_running is
* increased. Here we update the fair scheduling stats and
* then put the task into the rbtree:
*/
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
if (p->in_iowait)
cpufreq_update_this_cpu(rq, SCHED_CPUFREQ_IOWAIT);
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
......
}
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
cfs_rq->h_nr_running++;
if (cfs_rq_throttled(cfs_rq))
break;
update_load_avg(se, UPDATE_TG);
update_cfs_shares(se);
}
if (!se)
add_nr_running(rq, 1);
hrtick_update(rq);
}
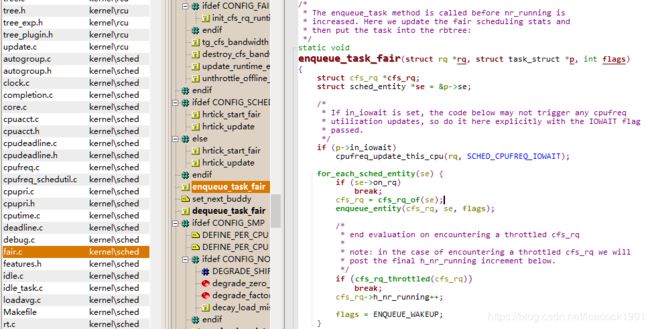
在 enqueue_task_fair 中取出的队列就是 cfs_rq,然后调用 enqueue_entity
enqueue_entity 函数 ( enqueue_task_fair )
kernel\sched\fair.c
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED);
bool curr = cfs_rq->curr == se;
/*
* If we're the current task, we must renormalise before calling
* update_curr().
*/
if (renorm && curr)
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq);
......
if (!curr)
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}
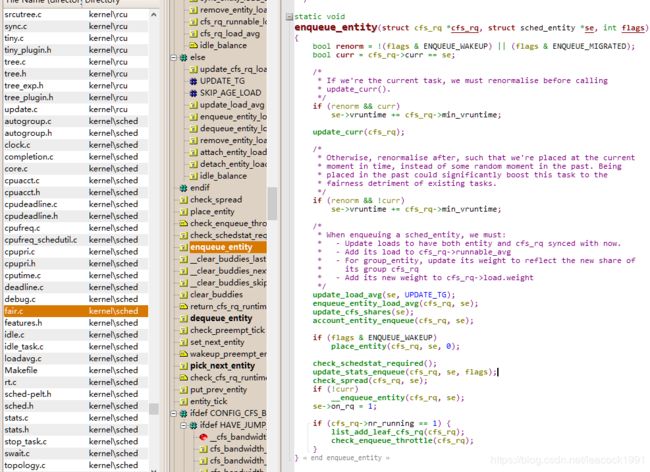
将这个队列上运行的进程数目加一 add_nr_running(rq, 1);
- 调用 check_preempt_curr
\kernel\sched\core.c
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
if (p->sched_class == rq->curr->sched_class) {
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
} else {
for_each_class(class) {
if (class == rq->curr->sched_class)
break;
if (class == p->sched_class) {
resched_curr(rq);
break;
}
}
}
/*
* A queue event has occurred, and we're going to schedule. In
* this case, we can save a useless back to back clock update.
*/
if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq, true);
}
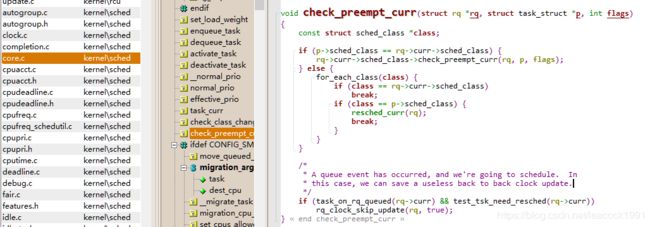
查看是否能够抢占当前进程
调用相应的调度类的 rq->curr->sched_class->check_preempt_curr(rq, p, flags)
对于 CFS 调度类来讲,调用的是 check_preempt_wakeup。
** check_preempt_wakeup 函数**
\kernel\sched\fair.c
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
struct task_struct *curr = rq->curr;
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
......
if (test_tsk_need_resched(curr))
return;
......
find_matching_se(&se, &pse);
update_curr(cfs_rq_of(se));
if (wakeup_preempt_entity(se, pse) == 1) {
goto preempt;
}
return;
preempt:
resched_curr(rq);
......
}
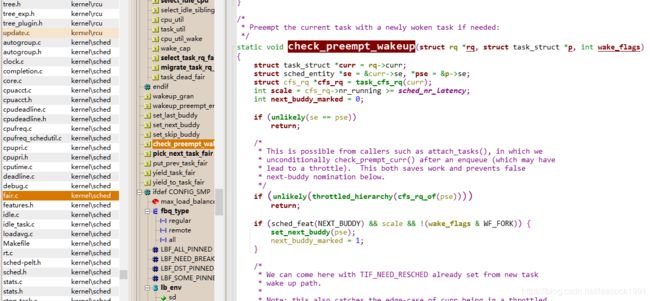
前面调用 task_fork_fair 的时候,设置 sysctl_sched_child_runs_first 了,已经将当前父进程的 TIF_NEED_RESCHED 设置了,则直接返回。
否则,check_preempt_wakeup 还是会调用 update_curr 更新一次统计量,然后wakeup_preempt_entity 将父进程和子进程 PK 一次,看是不是要抢占,如果要则调用 resched_curr 标记父进程为TIF_NEED_RESCHED。
fork 是一个系统调用,从系统调用返回的时候,是抢占的一个好时机
fork 系统调用的过程图
图片来自极客时间趣谈linux操作系统
参考资料:
趣谈Linux操作系统(极客时间)链接:
http://gk.link/a/10iXZ
欢迎大家来一起交流学习