欢迎关注哈希大数据微信公众号【哈希大数据】
1 KNN算法基本介绍
K-Nearest Neighbor(k最邻近分类算法),简称KNN,是最简单的一种有监督的机器学习算法。也是一种懒惰学习算法,即开始训练仅仅是保存所有样本集的信息,直到测试样本到达才开始进行分类决策。
KNN算法的核心思想:要想确定测试样本属于哪一类,就先寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后判断这K个样本中大部分所属的类型,就认为是该测试样本的类型。也就是所谓的“近朱者赤近墨者黑”,根据与其最近的k个样本的类型决定其自身的类型。因此K的确定和测算距离的方式是影响样本最终分类准确率的重要因素。
常用的测算距离的方法是多维空间的欧式距离法。
其优点为:易于理解,实现简单,无需估计参数,无需训练。
缺点为:需要保存所有的训练数据,内存开销大,而且训练数据较多时会导致很高的算法复杂度,训练数据类型不均匀可能会导致预测准确率下降。
2 标准数据集介绍
我们将采用scikit-learn库中自带的鸢尾花数据集进行测试。可以在D:\anaconda python\pkgs\scikit-learn-0.19.0-np113py36_0\Lib\site-packages\sklearn\datasets\data路径下查看元数据,部分数据实例如下图(共计150条数据)。

鸢尾花数据集包括鸢尾花的测量数据(特征属性)以及其所属的类别。
测量数据特征包括: 萼片长度、萼片宽度、花瓣长度、花瓣宽度
所属类别有三类: Iris Setosa,Iris Versicolour,Iris Virginica ,用数字0,1,2表示。
#通过python加载鸢尾花数据集
from sklearn import datasetsiris = datasets.load_iris()
# 获取鸢尾花属性数据并查看数据特征
iris_X = iris.dataprint(iris.data.shape)
# 获取鸢尾花类别数据
iris_y = iris.target
拆分****数据集****为训练数据和测试数据:
# 方法一:使用python的train_test_split库进行数据集拆分
iris_train_X , iris_test_X, iris_train_y ,iris_test_y = train_test_split(iris_X, iris_y, test_size=0.2,random_state=0)
# 方法二:随机选择部分数据(20%)作为测试集(适用于少量数据)
np.random.seed(0)
select = np.random.permutation(len(iris_y))
iris_X_train = iris_X[select[:-30]]
iris_y_train = iris_y[indices[:-30]]
iris_X_test = iris_X[indices[-30:]]
iris_y_test = iris_y[indices[-30:]]
3 KNN算法python实现
在此我们将直接使用python的scikit-learn 库中的 neighbors.KNeighborsClassifier类,通过KNN算法对测试集中鸢尾花进行分类。
首先进行类的初始化
knn =KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform')
参数介绍
l n_neighbors=5,就是KNN中的k,默认为5。
l weights='uniform',是距离计算中使用的权重,默认为'uniform' 是等权加权,也可以选'distance'是按照距离的倒数进行加权,也可以自己设置其他加权方式。(给距离增加权重,如果越近的距离权重越高,能在一定程度上避免样本分布不平均的问题)
l metric='minkowski'、p=2,表示采用的是欧氏距离的计算。
计算距离的方式默认为闵可夫斯基距离,是一组距离的定义。
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离:
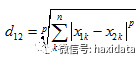
。
其中p=1时,为曼哈顿距离;p=2时,为欧氏距离;p→∞时,为切比雪夫距离。根据变参数p的不同,闵氏距离可以表示一类的距离。
l algorithm='auto',是分类时采取的算法,有'brute'、'kd_tree'和'ball_tree',三种默认按照数据特征从这三种中选择最合适的。其中kd-tree基于欧氏距离的特性可以快速处理20维以内的数据集,balltree基于更一般的距离特性,适合处理高维数据。(三种算法的具体实现之后会进行详细介绍)
l leaf_size=30,是kd_tree或ball_tree生成的树的树叶(二叉树中未分枝的节点)的大小。
l n_job=1,是并行计算的线程数量,默认是1,输入-1则设为CPU的内核数。
# ****提供数据集进行训练
knn.fit(iris_X_train, iris_y_train)
# ****预测测试集数据鸢尾花类型
predict_result = knn.predict(iris_X_test)print(predict_result)
# ****计算预测的准确率
print(knn.score(iris_X_test, iris_y_test))
4 完整源码及输出结果
!/usr/bin/python
-- coding: utf-8 --
KNN调用
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
导入鸢尾花数据并查看数据特征
iris = datasets.load_iris()
print('数据量',iris.data.shape)
拆分属性数据
iris_X = iris.data
拆分类别数据
iris_y = iris.target
方法一:拆分测试集和训练集,并进行预测
iris_train_X , iris_test_X, iris_train_y ,iris_test_y = train_test_split(iris_X, iris_y, test_size=0.2,random_state=0)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(iris_train_X, iris_train_y)
knn.predict(iris_test_X)
方法二:拆分测试集和训练集
np.random.seed(0)
permutation随机生成0-150的系列
indices = np.random.permutation(len(iris_y))
iris_X_train = iris_X[indices[:-30]]
iris_y_train = iris_y[indices[:-30]]
iris_X_test = iris_X[indices[-30:]]
iris_y_test = iris_y[indices[-30:]]
knn = KNeighborsClassifier()
提供训练集进行顺利
knn.fit(iris_X_train, iris_y_train)
预测测试集鸢尾花类型
predict_result = knn.predict(iris_X_test)
print('预测结果',predict_result)
计算预测的准确率
print('预测准确率',knn.score(iris_X_test, iris_y_test))
输出结果
"D:\anaconda python\python3.6.exe" D:/machine_learning/coding/knntest.py
数据量 (150, 4)
预测结果 [0 2 0 0 2 0 2 1 1 1 2 2 2 1 0 1 2 2 0 1 1 2 1 0 0 0 2 1 2 0]
预测准确率 0.933333333333
Process finished with exit code 0