【已解决!】spark程序报错:java.lang.IndexOutOfBoundsException: toIndex = 9
该篇文章意于记录报错,也给遇到相同问题的小伙伴提供排错思路!但是本人也没有什么好的解决方法,如果有,我会更新此文章
问题已经解决,请大家拉到最下面↓↓↓↓↓
记录下报错:
写了段spark代码,然后报错了
2018-07-30 17:19:28,854 WARN [task-result-getter-2] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Lost task 83.0 in stage 2.0 (TID 237, 30号机器, executor 100): TaskKilled (stage cancelled)
2018-07-30 17:19:28,855 ERROR [dag-scheduler-event-loop] scheduler.LiveListenerBus (Logging.scala:logError(70)) - SparkListenerBus has already stopped! Dropping event SparkListenerTaskEnd(2,0,ShuffleMapTask,TaskKilled(stage cancelled),org.apache.spark.scheduler.TaskInfo@7b0d2125,null)
2018-07-30 17:19:28,855 ERROR [dag-scheduler-event-loop] scheduler.LiveListenerBus (Logging.scala:logError(70)) - SparkListenerBus has already stopped! Dropping event SparkListenerTaskEnd(2,0,ShuffleMapTask,TaskKilled(stage cancelled),org.apache.spark.scheduler.TaskInfo@4ad83316,null)
2018-07-30 17:19:28,855 WARN [task-result-getter-0] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Lost task 175.0 in stage 2.0 (TID 295, 43号机器, executor 1): TaskKilled (stage cancelled)
2018-07-30 17:19:28,856 WARN [task-result-getter-1] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Lost task 2.0 in stage 2.0 (TID 131, 43号机器, executor 1): TaskKilled (stage cancelled)
2018-07-30 17:19:28,856 ERROR [dag-scheduler-event-loop] scheduler.LiveListenerBus (Logging.scala:logError(70)) - SparkListenerBus has already stopped! Dropping event SparkListenerTaskEnd(2,0,ShuffleMapTask,ExceptionFailure(java.lang.IndexOutOfBoundsException,toIndex = 9,[Ljava.lang.StackTraceElement;@a6236c8,java.lang.IndexOutOfBoundsException: toIndex = 9
at java.util.ArrayList.subListRangeCheck(ArrayList.java:1004)
at java.util.ArrayList.subList(ArrayList.java:996)
at org.apache.hadoop.hive.ql.io.orc.RecordReaderFactory.getSchemaOnRead(RecordReaderFactory.java:161)
at org.apache.hadoop.hive.ql.io.orc.RecordReaderFactory.createTreeReader(RecordReaderFactory.java:66)
at org.apache.hadoop.hive.ql.io.orc.RecordReaderImpl.(RecordReaderImpl.java:202)
at org.apache.hadoop.hive.ql.io.orc.ReaderImpl.rowsOptions(ReaderImpl.java:539)
at org.apache.hadoop.hive.ql.io.orc.OrcRawRecordMerger$ReaderPair.(OrcRawRecordMerger.java:183)
at org.apache.hadoop.hive.ql.io.orc.OrcRawRecordMerger$OriginalReaderPair.(OrcRawRecordMerger.java:226)
at org.apache.hadoop.hive.ql.io.orc.OrcRawRecordMerger.(OrcRawRecordMerger.java:437)
at org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.getReader(OrcInputFormat.java:1215)
at org.apache.hadoop.hive.ql.io.orc.OrcInputFormat.getRecordReader(OrcInputFormat.java:1113)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:246)
at org.apache.spark.rdd.HadoopRDD$$anon$1.(HadoopRDD.scala:245)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:203)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:94)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:105)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748) 在代码当中,我将三张表分别读取出来,然后做join,但是我发现程序运行很快就报错了,我一开始猜想的时候,以为是我spark程序的问题,调了半天。经过别人提醒,有可能是数据异常!!!
然后我就在读取每一张表之后做count(强制触发读表操作,结果发现A表的count就出了问题)
因此我把读取A表的sql拿到hive中执行,果然:
2018-07-30 17:32:59,516 Stage-1 map = 69%, reduce = 100%, Cumulative CPU 4831.3 sec
2018-07-30 17:33:00,583 Stage-1 map = 95%, reduce = 100%, Cumulative CPU 4831.3 sec
2018-07-30 17:33:01,633 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4831.3 sec
MapReduce Total cumulative CPU time: 0 days 1 hours 20 minutes 31 seconds 300 msec
Ended Job = job_1525840870040_80806 with errors
Error during job, obtaining debugging information...
Examining task ID: task_1525840870040_80806_m_000011 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000085 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000312 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000133 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000041 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000445 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000298 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000291 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000108 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000065 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000058 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000182 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000389 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000438 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000488 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000238 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000343 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000149 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000451 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000141 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000484 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000245 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000377 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000360 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000000 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000059 (and more) from job job_1525840870040_80806
Examining task ID: task_1525840870040_80806_m_000426 (and more) from job job_1525840870040_80806
Task with the most failures(4):
-----
Task ID:
task_1525840870040_80806_m_000011
URL:
http://0.0.0.0:8088/taskdetails.jsp?jobid=job_1525840870040_80806&tipid=task_1525840870040_80806_m_000011
-----
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:179)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row
at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:52)
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.java:170)
... 8 more
Caused by: java.lang.ArrayIndexOutOfBoundsException: 10
at org.apache.hadoop.hive.ql.exec.vector.udf.VectorUDFAdaptor.evaluate(VectorUDFAdaptor.java:117)
at org.apache.hadoop.hive.ql.exec.vector.expressions.VectorExpression.evaluateChildren(VectorExpression.java:118)
at org.apache.hadoop.hive.ql.exec.vector.expressions.gen.FilterDoubleColumnBetween.evaluate(FilterDoubleColumnBetween.java:55)
at org.apache.hadoop.hive.ql.exec.vector.VectorFilterOperator.processOp(VectorFilterOperator.java:100)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:815)
at org.apache.hadoop.hive.ql.exec.TableScanOperator.processOp(TableScanOperator.java:98)
at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:157)
at org.apache.hadoop.hive.ql.exec.vector.VectorMapOperator.process(VectorMapOperator.java:45)
... 9 more
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 908 Reduce: 1099 Cumulative CPU: 4831.3 sec HDFS Read: 3284591273 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 days 1 hours 20 minutes 31 seconds 300 msec
所以hive也报错,也是数组下标越界(这张表是ORC格式),我想应该是这个表中对应分区的部分数据损坏,导致字段缺失等类似问题!
暂时还未想到解决方法,但愿有好的方法,来填这个坑
==========================================华丽的分割线===========================================
时隔多久,我终于解决这个问题了,喜(喜闻乐见)大(大快人心)普(普天同庆)奔(奔走相告)
其实是这个错误拖了一段时间,最近相对闲了点所以才又开始思考这个问题,其实无非就以下几种方法:
1、看报错的代码为什么错,debug,看看下标越界之前都有哪些变量,变量的值都是什么(但是,好像我们这里的环境不太允许debug,或者说比较麻烦)
2、百度/google/必应,搜索相关类的报错(别搜索报错类型,搜索报错类型,只会告诉你下标越界是因为集合长度不够),所以我搜索了RecordReaderFactory这个类
3、如果搜索一段时间都找不到相关的问题,那么就要大胆的猜测,小心的求证,复现bug很重要(其实百度就是为了提供猜测的方向,避免满世界乱猜)!只要能复现,能知道问题所在,就能精准解决~
我搜索到的相关issue:
https://issues.apache.org/jira/browse/HIVE-14650
https://issues.apache.org/jira/browse/HIVE-13432
https://issues.apache.org/jira/browse/HIVE-14004
https://issues.apache.org/jira/browse/HIVE-13974
其实好像都和我的错误不那么一样,但是在14650这个issue中,我看到了一段留言
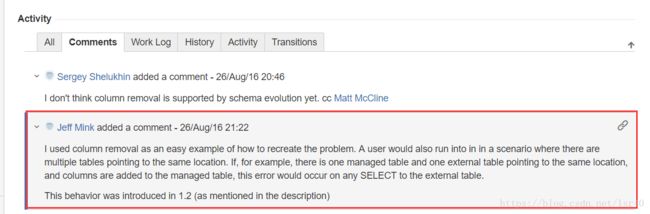 中文翻译过来就是:这个错误可以很简单的复现,当一个用户将多个表指向同一个路径的时候就有可能会出现这种问题,例如:一张manager表(内部表),一张external表(外部表),指向同一个路径,然后在内部表中添加了新的字段。这样对于外部表做任何的select操作都会有这样的报错!
中文翻译过来就是:这个错误可以很简单的复现,当一个用户将多个表指向同一个路径的时候就有可能会出现这种问题,例如:一张manager表(内部表),一张external表(外部表),指向同一个路径,然后在内部表中添加了新的字段。这样对于外部表做任何的select操作都会有这样的报错!
我觉得看到曙光了,因此我就实际测试了下,对的,我发现我查询的那张表确实是external表,所以我查询了那个路径的内部表(查询方式有两种,如果你有权限去hive的元数据库中查,那要确认下命令是什么,大概是通过location这个字段去查表名,另一种查询方式就是用嘴问你们公司相关开发人员,他们肯定会知道的),发现确实内部表比external表多了一个字段!但是这种情况使用hive查询不会报错,但是使用spark查询就各种不行,所以确认问题之后就简单了~
解决方法:
在hive中新建一张字段全的表,以后就用这张表了,或者直接把之前的external表删了(external表删除并不会删除数据,所以不用担心),然后新建一张名字一样,但是字段全的表就可以了。
但是建完表之后如果原来那张表是分区表,那还需要加载分区,加载分区通过两种命令:一是一个分区一个分区的加载,二是分区修复命令,命令如下:
--分区修复(当然是这种方式比较简单啊,但是要检查下成功了没有)
MSCK REPAIR TABLE 表名;
--成功了会有如下信息:
Partitions not in metastore: 表名:date_id=20180905/XXX=xxx
Repair: Added partition to metastore
数据库.表名:date_id=20180905/XXX=xxx
--一个一个分区手动添加(分区少,或者单纯测试的时候可以用用,分区多还是算了吧)
alter table 表名 add partition (date_id='20180905',XXX=xxx);
--检查分区情况
show partitions 数据库.表名到此就可以完美解决这个bug了,当然如果你要改源码重新打包编译七七八八的也ok,但是还是要考虑到今后的维护,一定要用最简单的方法来解决问题,我觉得我这个解决方法是最简单的了!
希望以后遇到所有的坑,我也能像这次一样填上!!!阿门~