超大表关联的优化方法
我们在工作中经常会遇到某些业务表中的数据量随着系统上线运行时间的增加与日俱增,这些表在上线之初数据量不大,各种SQL语句运行速度也是杠杠的。
但随着数据量多了,表之间的关联效率就开始差强人意了。
很多的开发人员,对ORACLE数据库里面CBO优化器的原理不了解,当SQL跑得慢的时候,总是认为是表没有加索引,结果一个表上胡乱的加上了很多索引,查询效率不见得会提高了,反而影响了insert和update语句的速度。
我们今天模拟一下两个大表之间关联的优化,核心思想是分表。
首先建立两张测试表T1和T2,连续插入数据至每张表的体积达到2G。
create table t1 as select * from dba_objects;
insert into t1 select * from t1;
--连续插入多次,直至达到2G。
--下面的语句是查询表大小的
SELECT SEGMENT_NAME,
SEGMENT_TYPE,
TABLESPACE_NAME,
EXTENTS,
BLOCKS,
BYTES / 1024 / 1024 / 1024 GB
FROM DBA_SEGMENTS
WHERE SEGMENT_NAME = 'T1';
--再将表T1直接复制为T2
create table t2 as select * from t1;
两张表的数据量查得各有18783232行(1878W),姑且算得上是一个较大的表了。
select count(*) from t1; --- 1878W rows在两张表的OBJECT_ID列分别建立索引IDX_T1、IDX_T2;
CREATE INDEX idx_t1 ON t1(object_id);
CREATE INDEX IDx_t2 ON t2(object_id);为了保证统计信息的准确性,我们在这里还要收集下两张表的统计信息。oracle默认的收集粒度是30% ,我这里是测试环境,收集了100%,虽然时间花了3分钟。
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(OWNNAME => 'SCOTT',
TABNAME => 'T1',
ESTIMATE_PERCENT => 100,
METHOD_OPT => 'for all columns size 1',
CASCADE => TRUE,
NO_INVALIDATE => FALSE,
DEGREE => 8);
END;
/模拟优化的SQL语句如下
select * from t1,t2 where t1.object_id=t2.object_id;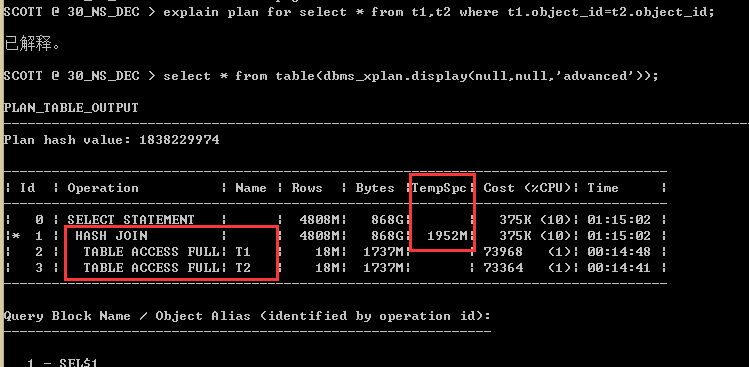
可以看到CBO根据其内置的算法,认为这个SQL应该走HASH JOIN,并且表的访问方式是全表扫描TABLE ACCESS FULL。
由于一个会话的PGA最大限制只有2G,所以这个SQL在执行的时候,PGA里面是放不下的,将会用到TEMP表空间。这里为了测试,另外在建立一个SCOTT_TEMP临时表空间,并指定大小5G,可扩展到32G。将其默认给SCOTT用户。
SQL>create TEMPORARY TABLESPACE scott_temp
tempfile 'E:\APP\ADMINISTRATOR\ORADATA\NSDEC\SCOTT_TEMP.DBF' size 5G
autoextend on next 100M maxsize unlimited;
SQL>alter user scott TEMPORARY TABLESPACE SCOTT_TEMP;执行语句
select * from t1,t2 where t1.object_id=t2.object_id;
可以看到用时将近2分钟,两个2G的表跑了2分钟,实际中所谓的大数据都是几十G上百G。那么将会基本跑不出结果的,或者速度极慢!!
我们可以按照HADOOP等大数据的方法来化解走HASH时数据量过大的问题,即将数据分而治之!!!
分而治之的方法有两种,一种是最习惯上手的分区,另一个是分表。
我们这里采用分区的方式来优化。按照T1、T2的表结构添加一列P_VALUE并按照P_VALUE进行LIST分区。
CREATE TABLE P_T1(
P_VALUE NUMBER,
OWNER VARCHAR2(30),
OBJECT_NAME VARCHAR2(128),
SUBOBJECT_NAME VARCHAR2(30),
OBJECT_ID NUMBER,
DATA_OBJECT_ID NUMBER,
OBJECT_TYPE VARCHAR2(19),
CREATED DATE,
LAST_DDL_TIME DATE,
TIMESTAMP VARCHAR2(19),
STATUS VARCHAR2(7),
TEMPORARY VARCHAR2(1),
GENERATED VARCHAR2(1),
SECONDARY VARCHAR2(1),
NAMESPACE NUMBER,
EDITION_NAME VARCHAR2(30)
)
PARTITION BY list(P_VALUE)
(
partition p0 values (0),
partition p1 values (1),
partition p2 values (2),
partition p3 values (3),
partition p4 values (4)
);同理创建分区表P_T2;
CREATE TABLE P_T2(
P_VALUE NUMBER,
OWNER VARCHAR2(30),
OBJECT_NAME VARCHAR2(128),
SUBOBJECT_NAME VARCHAR2(30),
OBJECT_ID NUMBER,
DATA_OBJECT_ID NUMBER,
OBJECT_TYPE VARCHAR2(19),
CREATED DATE,
LAST_DDL_TIME DATE,
TIMESTAMP VARCHAR2(19),
STATUS VARCHAR2(7),
TEMPORARY VARCHAR2(1),
GENERATED VARCHAR2(1),
SECONDARY VARCHAR2(1),
NAMESPACE NUMBER,
EDITION_NAME VARCHAR2(30)
)
PARTITION BY list(P_VALUE)
(
partition p0 values (0),
partition p1 values (1),
partition p2 values (2),
partition p3 values (3),
partition p4 values (4)
);将T1、T2表的数据分别插入到P_T1和P_T2中去。
insert into p_t1 nologging select ora_hash(object_id,4), a.* from t1 a ;
insert into p_t2 nologging select ora_hash(object_id,4), a.* from t2 a ;所以,
语句
select * from t1,t2 where t1.object_id=t2.object_id;就变成了如下五组语句:
select * from p_t1,p_t2 where p_t1.object_id=p_t2.object_id and p_t1.p_value=0 and p_t2.p_value=0
union all
select * from p_t1,p_t2 where p_t1.object_id=p_t2.object_id and p_t1.p_value=1 and p_t2.p_value=1
union all
select * from p_t1,p_t2 where p_t1.object_id=p_t2.object_id and p_t1.p_value=2 and p_t2.p_value=2
union all
select * from p_t1,p_t2 where p_t1.object_id=p_t2.object_id and p_t1.p_value=3 and p_t2.p_value=3
union all
select * from p_t1,p_t2 where p_t1.object_id=p_t2.object_id and p_t1.p_value=4 and p_t2.p_value=4;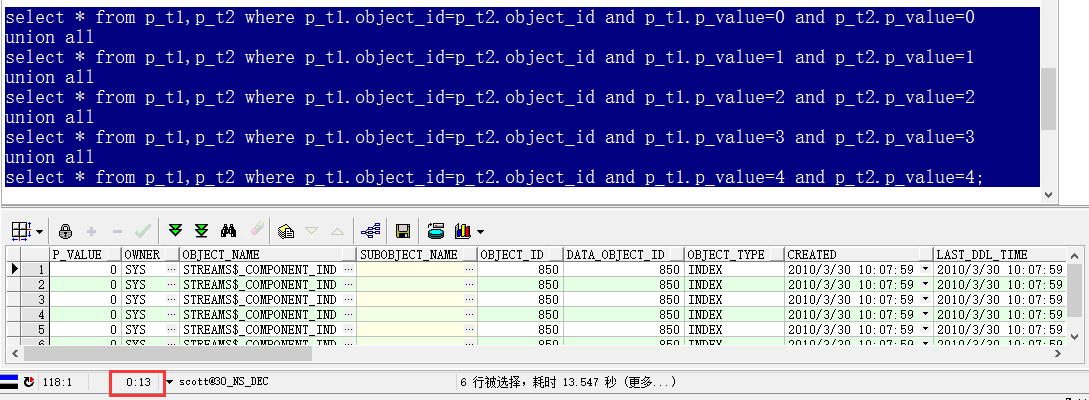
ORACLE数据库是行存储,全表扫描时 扫描一行数据只能将所有的列都扫了,所以PGA是放不下那么大的数据的,放到temp表空间后再来做关联,IO吞吐量也会变大,更何况磁盘的速度还远不如内存呢,所以大表与大表之间做连接走hash的时候,也会是很慢的!当然,再慢也还是会比NESTED LOOP强太多太多!。
按照分区、分表的思维,这样五条SQL跑完的时间将会大大缩小了。
另外,还可以使用PLSQL编程将这操作编写脚本,进行封装。更加方便。