爬虫-反爬一:boss直聘cookies反爬怎么治
文章目录
- 絮叨一下
- 分析
- 开撸
- 1.新建爬虫
- 2.分析页面布局
- 3.步骤
- 1.设置middlewares以及settings(核心)
- 2.boss_spider.py
- 3.item.py
- 4.运行
- 5. 效果
- 写给看到最后的你
絮叨一下
boos直聘,想必对于找工作的同志都非常熟悉,以其'招人快 人才多 匹配准 公开透明'等优点位居行业的前沿,,,当然我不是来打广告的,我是来安排他的.
今天就用scrapy框架配合selenium进行岗位,薪资.待遇,公司 等信息进行爬取
对于反爬,自己的需求不是很高自然这种方法应该是最简单的
分析
boss直聘网站: www.zhipin.com
他的反爬还是很讨厌的,信息都是用cookies渲染生成的,cookies时效很短,很快就失效了,快速访问还会封掉你的ip ,封了ip第一反映就使用代理吧,使用代理你就会发现,会提示ip异常,然后进验证,,完了 看来需要接入接码平台了,,啊啊啊 , 好麻烦
,当然了首页是没有反爬的,那就慢一点,虽然这一点都不像爬虫的正确姿势
但对于一些反爬机制,有不懂js的时候,这似乎也是一种选择
开撸

主要抓取职位,薪资,公司名字,待遇,要求
1.新建爬虫
打开终端或者是cmd 输入命令
新建项目
scrapy startproject boss
进入boss目录
cd boss
新建爬虫
scrapy genspider boss_spider 'zhipin.com'
使用pycharm打开
2.分析页面布局
查看url :
第一页: https://www.zhipin.com/c101120100/?query=python&page=1&ka=page-1
其中&ka=page-1可以省略
第二页:https://www.zhipin.com/c101120100/?query=python&page=2
一共10页
查看数据
想要的数据全都保存在ul列表下
那我们就可以去遍历ul
3.步骤
我们知道了地址知道了数据的存放位置 就可以开始了
1.设置middlewares以及settings(核心)
因为我们要使用selenium,需要截获他的response对象,然后在进行转换
我们新建一个类
如果你不清楚selenium的使用也没有关系,可以查看这篇文章
selenium详细介绍
如果你还不明白scrapy的中间件可以参考这篇文章,要不在往下看你将会很迷糊
scrapy详细
from scrapy import signals
from selenium import webdriver
import time
from scrapy.http.response.html import HtmlResponse
class CookiesMiddlewares(object):
def __init__(self):
print("初始化浏览器")
self.driver = webdriver.Chrome()
def process_request(self,request,spider):
self.driver.get(request.url)
time.sleep(5)
# 我们等待5秒钟,让其加载
source = self.driver.page_source
#获取页面的源码
response = HtmlResponse(url=self.driver.current_url,body=source,request=request,encoding='utf-8')
# Response 对象用来描述一个HTTP响应
return response
# 这样我们就获取到了所有的信息,并返回response
setting 中将机器人协议设置成false
ROBOTSTXT_OBEY = False
开启下载延迟
DOWNLOAD_DELAY = 3
开启请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
}
开启中间件
DOWNLOADER_MIDDLEWARES = {
'boss.middlewares.CookiesMiddlewares': 543,
}
2.boss_spider.py
import scrapy
from boss.items import BossItem
class BossSpiderSpider(scrapy.Spider):
name = 'boss_spider'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/c101120100/?query=python&page=1']
base_url = 'https://www.zhipin.com'
def parse(self, response):
job = response.xpath ("//div[@class='job-list']/ul/li")
for i in job:
job_name = i.xpath (".//span[@class='job-name']/a/text()").get ()
print(job_name)
money = i.xpath (".//span[@class='red']/text()").get ()
name = i.xpath (".//h3[@class='name']/a/text()").get ()
tags = i.xpath (".//div[@class='tags']/span/text()").getall ()
tags = ''.join (tags)
info_desc = i.xpath (".//div[@class='info-desc']/text()").get ()
yield BossItem (job_name=job_name, money=money, name=name, tags=tags, info_desc=info_desc)
# 获取下一页的地址
page = response.xpath("//div[@class='page']/a[last()]/@href").get()
next_url = self.base_url + page
if not next_url:
print("退出")
return
else:
print ("下一页地址:",next_url)
yield scrapy.Request (next_url)
这一部分没啥好解释的,如果看不明白可以查看这篇文章
scrapy详细介绍
3.item.py
import scrapy
class BossItem(scrapy.Item):
job_name = scrapy.Field()
money = scrapy.Field()
name = scrapy.Field()
tags = scrapy.Field()
info_desc = scrapy.Field()
4.运行
新建项目命名cmd
from scrapy import cmdline
cmdline.execute('scrapy crawl boss_spider -o boss.csv'.split())
# -o boss.csv 使用csv格式进行保存,当然在Pipeline中写也是一样的,不要忘记打开pipline
5. 效果
这样就开始爬取了,如果你想不显示浏览器可以设置成无界面模式.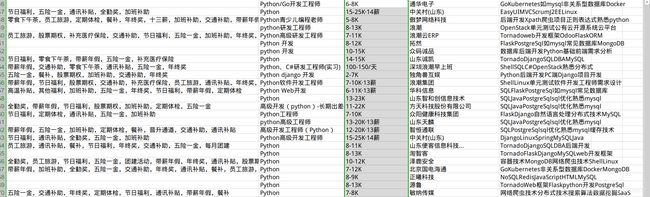
稍等片刻后,400多招聘信息就全部保存了
然后便可以做分析用
写给看到最后的你
朋友,感谢你看到了最后,新手报道,技术不成熟的地方请多多指点,感谢!
公众号:Linux下撸python
期待和你再次相遇
愿你学的愉快
