elk日志分析平台 (1) Elasticsearch
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
安装
[root@server1 ~]# rpm -ivh elasticsearch-7.6.1-x86_64.rpm
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
Created elasticsearch keystore in /etc/elasticsearch
根据提示我们先reload,再设置开机启动。
[root@server1 ~]# systemctl daemon-reload
[root@server1 ~]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
这时候先不要进行启动,应为肯定会报错,我们需要先改变主配置文件。
[
root@server1 elasticsearch]# cd /etc/elasticsearch/
[root@server1 elasticsearch]# vim elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
cluster.name: my-es ##首先设置一个集群的名字。
# ------------------------------------ Node ------------------------------------
node.name: server1 ##先设置一个单点 后面写主机名的话要加解析
# ----------------------------------- Memory -----------------------------------
bootstrap.memory_lock: true ##锁定内存,开启这个软件默认为1个G的内存,所以虚拟机至少要2个G的内存。这个设置在jvm.options文件中-Xms1g-Xmx1g这两个配置进行设置。
# ---------------------------------- Network -----------------------------------
network.host: 192.168.122.11 ##监听地址
http.port: 9200 ##监听端口
# --------------------------------- Discovery ----------------------------------
cluster.initial_master_nodes: ["server1"] ##这个需要设置,不设置会报错。
锁定内存一般是我们机器内存值的一半,如果我们内存不够用的话可以手动设置。
vim jvm.options
################################################################
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms512m ##设置到512M内存
-Xmx512m
下来再设定限制
[root@server1 vm]# vim /etc/security/limits.conf
elasticsearch soft memlock unlimited ##软限
elasticsearch hard memlock unlimited ##硬限
elasticsearch - nofile 65535
elasticsearch - nproc 4096
如果使用systemd那么要添加如下参数,不然不生效
[root@server1 vm]# vim /usr/lib/systemd/system/elasticsearch.service
# Specifies the maximum size of virtual memory
LimitMEMLOC=infinity
设置完成之后先将swap关掉。
echo 1 > /proc/sys/vm/swappiness
[root@server1 vm]# swapoff -a
[root@server1 vm]# vim /etc/fstab ##将swap注释掉
现在启动。
[root@server1 vm]# netstat -anltp
tcp6 0 0 192.168.122.11:9200 :::* LISTEN 10720/java ##对外端口
tcp6 0 0 192.168.122.11:9300 :::* LISTEN 10720/java ##集群中通信
我们使用端口进行查看,可以看到如下界面就表示完成了,之后就可以进行下一步操作。

下载一个包并解压。
[root@server1 ~]# unzip elasticsearch-head-master.zip
再下载一个nodejs-9.11.2-1nodesource.x86_64.rpm的软件包。并安装。
[root@server1 ~]# rpm -ivh nodejs-9.11.2-1nodesource.x86_64.rpm
之后再下载一个phantomjs-2.1.1-linux-x86_64.tar.bz2的压缩包。但是这个包也可以不下载,如果网速快的话可以直接在网上进行拉取。
[root@server1 ~]# tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2
解压完成将二进制程序复制到/usr/local/bin/下就可以直接使用了
[root@server1 ~]# cd phantomjs-2.1.1-linux-x86_64/
[root@server1 phantomjs-2.1.1-linux-x86_64]# ls
bin ChangeLog examples LICENSE.BSD README.md third-party.txt
[root@server1 phantomjs-2.1.1-linux-x86_64]# cd bin/
[root@server1 bin]# ls
phantomjs
[root@server1 bin]# cp phantomjs /usr/local/bin/
再进入压缩包的目录进行安装
[root@server1 elasticsearch-head-master]# npm install --registry=https://registry.npm.taobao.org
之后将监听端口进行更改
vim elasticsearch-head-master/_site/app.js
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.122.11:9200"; ##将localhost改为ip地址
安装完成之后运行,并且打入后台。
[root@server1 elasticsearch-head-master]# npm run start &
[1] 11182
Started connect web server on http://localhost:9100
启动完成后访问9100端口,但是上面显示的为未连接,因为新版本需要进行配置,需要同意跨域连接。修改主配置文件
[root@server1 elasticsearch-head-master]# vim /etc/elasticsearch/elasticsearch.yml
# ---------------------------------- Network -----------------------------------
http.cors.enabled: true ##添加这两行
http.cors.allow-origin: "*"
[root@server1 elasticsearch-head-master]# systemctl restart elasticsearch.service
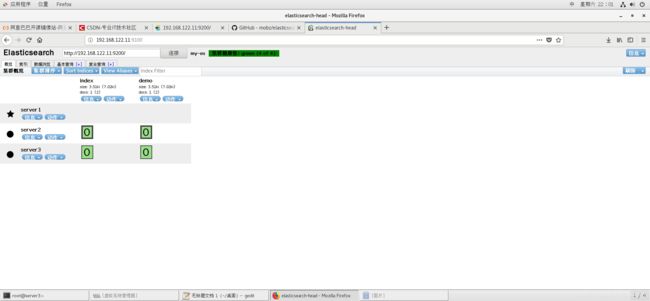
重启完成后刷新9100端口的页面,这样就看到已经连接。
下来我们点击复合查询,进行上传,验证之后进行提交,可以看到已经完成。再次刷新就可以看到


下来我们再起两台虚拟机。目的是为了选举master
另外两台虚拟机安装elasticsearch
vim /etc/security/limits.conf##设置限额
vim /usr/lib/systemd/system/elasticsearch.service ##锁定内存
swapoff -a ##关闭swap分区
vim /etc/fstab
echo 1> /proc/sys/vm/swappiness
vim /etc/elasticsearch/jvm.options##调整锁定内存
vim /etc/elasticsearch/elasticsearch.yml##配置主配置文件
注意填写集群名称(三个名称要相同)
设置主机名
设置监听ip地址和端口
在三个节点都设置如下:
# --------------------------------- Discovery ----------------------------------
discovery.seed_hosts: ["server1", "server2", "server3"]
cluster.initial_master_nodes: ["server1", "server2", "server3"]
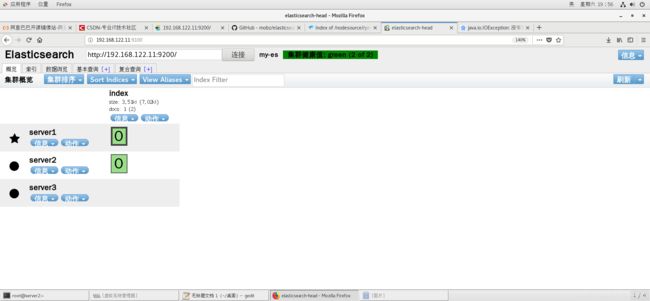
设置完成启动elasticsearch.service再刷新网页可以看到节点已经添加,前面是星的表示为master。
全都出现后可以再添加目录,这时候就多了一组分片,分片实现的都是一主一从的形式。
节点优化
ES集群中的节点分配不同角色,每种角色干的活都不一样。
Master
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。建议集群中Master节点的个数为奇数个,如3个或者5个。
设置一个几点为Master节点的方式如下:
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
Data Node
主要负责集群中数据的索引和检索,一般压力比较大。建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
设置一个几点为Data Node节点的方式如下:
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
Coordinating Node
主要功能是来分发请求和合并结果的。
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
Ingest Node
Ingest node专门对索引的文档做预处理,实际中不常用,除非文档在索引之前有大量的预处理工作需要做。Ingest node设置如下:
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
我们将server1设置为master,在server1的主配置文件中添加master的参数,之后将服务重启,
[root@server1 ~]# systemctl restart elasticsearch.service
Job for elasticsearch.service failed because the control process exited with error code. See "systemctl status elasticsearch.service" and "journalctl -xe" for details.
这里我们发现服务启动失败,这是查看日志。
[root@server1 ~]# cat /var/log/elasticsearch/my-es.log
Caused by: java.lang.IllegalStateException: Node is started with node.data=false, but has shard data: [/var/lib/elasticsearch/nodes/0/indices/xSExAmCLSyWN-uWVzjZVOw/0, /var/lib/elasticsearch/nodes/0/indices/dwmG-ID9Q_u4MwtTqjpcfw/0]. Use 'elasticsearch-node repurpose' tool to clean up ##日志显示这个节点有数据,如果要当master需要将数据清理。
这时需要进入/usr/share/elasticsearch/bin/下,所有命令在这个目录中。
[root@server1 bin]# ./elasticsearch-node repurpose
Node successfully repurposed to master and no-data ##这样就可以做master节点没有数据了。
再启动服务就可以正常启动
[root@server1 bin]# systemctl restart elasticsearch.service
使用配置
在server2和3的主配置文件中添加
node.master: true ##这个选项三个节点都打开,因为需要选举才确定谁是master
node.data: true
node.ingest: false
search.remote.connect: false
启动完成后刷新页面master已经给到了server1,并且server1上已经不存数据。