斯坦福机器学习笔记(七)——高斯混合模型与EM算法
前记
博客的PDF资源已经上传CSDN,如有需要移步:GMM与EM算法 。GMM模型的Python代码请移步:利用Python实现高斯混合模型(GMM)
一 高斯混合模型
我们给定一个训练集 { x ( 1 ) , ⋯ , x ( m ) } \left\{ {{x}^{\left( 1 \right)}},\cdots ,{{x}^{\left( m \right)}} \right\} {x(1),⋯,x(m)} ,由于是高斯混合模型(Mixtures of Gaussians ,GMM)属于无监督算法,因此训练集中不会出现任何标签。
我们希望通过指定联合分布 p ( x ( i ) , z ( i ) ) = p ( x ( i ) ∣ z ( i ) ) p ( z ( i ) ) p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}} \right)=p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}} \right. \right)p\left( {{z}^{\left( i \right)}} \right) p(x(i),z(i))=p(x(i)∣∣z(i))p(z(i))来对数据进行建模。在这里我们假定 z ( i ) ∼ M u l t i n o m i a l ( ϕ ) {{z}^{\left( i \right)}}\sim Multinomial\left( \phi \right) z(i)∼Multinomial(ϕ) ,即 z ( i ) {{z}^{\left( i \right)}} z(i) 服从多项式分布, ϕ j ≥ 0 {{\phi }_{j}}\ge 0 ϕj≥0 , ∑ j = 1 k ϕ j = 1 \sum\nolimits_{j=1}^{k}{{{\phi }_{j}}}=1 ∑j=1kϕj=1 ,并且参数 能够推导出 ,同时我们假设 ,在上叙述中, 代表 的种类数。因此,我们的模型假定每个 是通过从 中随机选择 而生成的,然后 也是来自依赖于 的 个高斯分布。那么上述模型被称为高斯混合模型。在这里, 是隐式随机变量,这也将我们估计问题变得非常困难。
那么对于给定的数据集 { x ( 1 ) , ⋯ , x ( m ) } \left\{ {{x}^{\left( 1 \right)}},\cdots ,{{x}^{\left( m \right)}} \right\} {x(1),⋯,x(m)} ,高斯混合模型的对数似然函数如下:
ℓ ( ϕ , μ , Σ ) = ∑ i = 1 m log p ( x ( i ) ∣ z ( i ) ; ϕ , μ , Σ ) = ∑ i = 1 m log p ( x ( i ) ∣ z ( i ) ; μ , Σ ) p ( z ( i ) ; ϕ ) \begin{aligned} \ell(\phi, \mu, \Sigma) &=\sum_{i=1}^{m} \log p\left(x^{(i)} | z^{(i)} ; \phi, \mu, \Sigma\right) \\ &=\sum_{i=1}^{m} \log p\left(x^{(i)} | z^{(i)} ; \mu, \Sigma\right) p\left(z^{(i)} ; \phi\right) \end{aligned} ℓ(ϕ,μ,Σ)=i=1∑mlogp(x(i)∣z(i);ϕ,μ,Σ)=i=1∑mlogp(x(i)∣z(i);μ,Σ)p(z(i);ϕ)
然而,如果我们令上述函数的偏导数为0的话,那么在封闭区域内,我们无法直接解决这个问题。
随机变量 z ( i ) {{z}^{\left( i \right)}} z(i) 表示每个 x ( i ) {{x}^{\left( i \right)}} x(i) 属于 k k k 个高斯分布的概率大小。请注意,如果我们知道 z ( i ) {{z}^{\left( i \right)}} z(i) 是多少,那么最大似然问题就很容易了。 具体来说,我们可以将对数似然函数写成:
ℓ ( ϕ , μ , Σ ) = ∑ i = 1 m log p ( x ( i ) ∣ z ( i ) ; μ , Σ ) + log p ( z ( i ) ; ϕ ) \begin{aligned} \ell \left( \phi ,\mu ,\Sigma \right)=\sum\limits_{i=1}^{m}{\log p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}} \right.;\mu ,\Sigma \right)\text{+}\log p\left( {{z}^{\left( i \right)}};\phi \right)} \end{aligned} ℓ(ϕ,μ,Σ)=i=1∑mlogp(x(i)∣∣∣z(i);μ,Σ)+logp(z(i);ϕ)
由于 z ( i ) ∼ M u l t i n o m i a l ( ϕ ) {{z}^{\left( i \right)}}\sim Multinomial\left( \phi \right) z(i)∼Multinomial(ϕ) ,那么我们有 :
p ( z ( i ) ; ϕ ) = ∏ j = 1 k p ( z ( i ) = j ; ϕ ) = ∏ j = 1 k ϕ j 1 { z ( i ) = j } \begin{aligned} p\left( {{z}^{\left( i \right)}};\phi \right)=\prod\limits_{j=1}^{k}{p\left( {{z}^{\left( i \right)}}=j;\phi \right)}=\prod\limits_{j=1}^{k}{\phi _{j}^{1\left\{ {{z}^{\left( i \right)}}=j \right\}}} \end{aligned} p(z(i);ϕ)=j=1∏kp(z(i)=j;ϕ)=j=1∏kϕj1{z(i)=j}
同理,因为 x ( i ) ∣ z ( i ) = j ∼ N ( μ j Σ j ) {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}} \right.\text{= }j\sim \mathcal{N}\left( {{\mu }_{j}}{{\Sigma }_{j}} \right) x(i)∣∣z(i)= j∼N(μjΣj),那么我们有:
p ( x ( i ) ∣ z ( i ) ; μ , Σ ) = ∏ j = 1 k p ( x ( i ) ∣ z ( i ) = j ; μ , Σ ) = ∏ j = 1 k { 1 ( 2 π ) n 2 ∣ Σ j ∣ 1 2 exp ( - 1 2 ( x ( i ) − u j ) T Σ − 1 ( x ( i ) − u j ) ) } 1 { z ( i ) = j } \begin{aligned} & p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}} \right.;\mu ,\Sigma \right)=\prod\limits_{j=1}^{k}{p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}}=j \right.;\mu ,\Sigma \right)} \\ & \begin{matrix} {} & {} & {} & {} & {} \\ \end{matrix}=\prod\limits_{j=1}^{k}{{{\left\{ \frac{1}{{{\left( 2\pi \right)}^{\frac{n}{2}}}{{\left| {{\Sigma }_{j}} \right|}^{\frac{1}{2}}}}\exp \left( \text{-}\frac{1}{2}{{\left( {{x}^{\left( i \right)}}-{{u}_{j}} \right)}^{T}}{{\Sigma }^{-1}}\left( {{x}^{\left( i \right)}}-{{u}_{j}} \right) \right) \right\}}^{1\left\{ {{z}^{\left( i \right)}}=j \right\}}}} \\ \end{aligned} p(x(i)∣∣∣z(i);μ,Σ)=j=1∏kp(x(i)∣∣∣z(i)=j;μ,Σ)=j=1∏k{(2π)2n∣Σj∣211exp(-21(x(i)−uj)TΣ−1(x(i)−uj))}1{z(i)=j}
因此,对数似然函数可以写成:
ℓ ( ϕ , μ , Σ ) = ∑ i = 1 m log p ( x ( i ) ; μ , Σ ) + log p ( z ( i ) ; ϕ ) = ∑ i = 1 m ( ∑ j = 1 k 1 { z ( i ) = j } { − 1 2 ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) − n 2 log 2 π − 1 2 log ∣ Σ j ∣ } = ∑ i = 1 k 1 { z ( i ) = j } log ϕ j \begin{aligned} \ell(\phi, \mu, \Sigma) &=\sum_{i=1}^{m} \log p\left(x^{(i)} ; \mu, \Sigma\right)+\log p\left(z^{(i)} ; \phi\right) \\ &=\sum_{i=1}^{m}\left(\sum_{j=1}^{k} 1\left\{z^{(i)}=j\right\}\left\{-\frac{1}{2}\left(x^{(i)}-\mu_{j}\right)^{T} \Sigma_{j}^{-1}\left(x^{(i)}-\mu_{j}\right)-\frac{n}{2} \log 2 \pi-\frac{1}{2} \log \left|\Sigma_{j}\right|\right\}\right.\\ &=\sum_{i=1}^{k} 1\left\{z^{(i)}=j\right\} \log \phi_{j} \end{aligned} ℓ(ϕ,μ,Σ)=i=1∑mlogp(x(i);μ,Σ)+logp(z(i);ϕ)=i=1∑m(j=1∑k1{z(i)=j}{−21(x(i)−μj)TΣj−1(x(i)−μj)−2nlog2π−21log∣Σj∣}=i=1∑k1{z(i)=j}logϕj
那么,对 μ j {{\mu }_{j}} μj 求偏导有:
∂ ℓ ∂ μ j = ∑ i = 1 m 1 { z ( i ) = j } Σ j − 1 ( x ( i ) − μ j ) = 0 \begin{aligned} \frac{\partial \ell }{\partial {{\mu }_{j}}}=\sum\limits_{i=1}^{m}{1\left\{ {{z}^{\left( i \right)}}=j \right\}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)=0 \end{aligned} ∂μj∂ℓ=i=1∑m1{z(i)=j}Σj−1(x(i)−μj)=0
由于 Σ j {{\Sigma }_{j}} Σj是矩阵,那么:
∂ ℓ ∂ μ j = ∑ i = 1 m 1 { z ( i ) = j } Σ j − 1 ( x ( i ) − μ j ) = 0 \frac{\partial \ell}{\partial \mu_{j}}=\sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\} \Sigma_{j}^{-1}\left(x^{(i)}-\mu_{j}\right)=0 ∂μj∂ℓ=i=1∑m1{z(i)=j}Σj−1(x(i)−μj)=0
同理,对 Σ j {{\Sigma }_{j}} Σj 求偏导有:
μ j = ∑ i = 1 m 1 { z ( i ) = j } x ( i ) ∑ i = 1 m 1 { z ( i ) = j } \mu_{j}=\frac{\sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\} x^{(i)}}{\sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\}} μj=∑i=1m1{z(i)=j}∑i=1m1{z(i)=j}x(i)
其中用到了如下矩阵求导公式:
∂ ℓ ∂ Σ j = ∑ i = 1 m 1 { z ( i ) = j } { 1 2 ( x ( i ) − μ j ) ( x ( i ) − μ j ) T Σ j − 2 − 1 2 Σ j − 1 } = 0 \frac{\partial \ell}{\partial \Sigma_{j}}=\sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\}\left\{\frac{1}{2}\left(x^{(i)}-\mu_{j}\right)\left(x^{(i)}-\mu_{j}\right)^{T} \Sigma_{j}^{-2}-\frac{1}{2} \Sigma_{j}^{-1}\right\}=0 ∂Σj∂ℓ=i=1∑m1{z(i)=j}{21(x(i)−μj)(x(i)−μj)TΣj−2−21Σj−1}=0
因此,
{ ∂ ∣ Σ ∣ ∂ Σ = ∣ Σ ∣ Σ − 1 ∂ Σ − 1 ∂ Σ = Σ − 2 \left\{\begin{array}{l}{\frac{\partial|\Sigma|}{\partial \Sigma}=|\Sigma| \Sigma^{-1}} \\ {\frac{\partial \Sigma^{-1}}{\partial \Sigma}=\Sigma^{-2}}\end{array}\right. {∂Σ∂∣Σ∣=∣Σ∣Σ−1∂Σ∂Σ−1=Σ−2
由于 ∑ j = 1 k ϕ j = 1 \sum\nolimits_{j=1}^{k}{{{\phi }_{j}}}=1 ∑j=1kϕj=1 ,那么我们必须利用拉格朗日乘数法来求解 。因此构造如下函数:
Σ j = ∑ i = 1 m 1 { z ( i ) = j } ( x ( i ) − u j ) ( x ( i ) − u j ) T ∑ i = 1 m 1 ′ z ( i ) = j } \Sigma_{j}=\frac{\sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\}\left(x^{(i)}-u_{j}\right)\left(x^{(i)}-u_{j}\right)^{T}}{\sum_{i=1}^{m} 1^{\prime} z^{(i)}=j \}} Σj=∑i=1m1′z(i)=j}∑i=1m1{z(i)=j}(x(i)−uj)(x(i)−uj)T
那么分别对 ϕ j , α {{\phi }_{j}},\alpha ϕj,α 求偏导有:
f ( z ; ϕ , α ) = ∑ i = 1 m ∑ j = 1 k 1 { z ( i ) = j } log ϕ j + α ( 1 − ∑ j = 1 k ϕ j ) f(z ; \phi, \alpha)=\sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{z^{(i)}=j\right\} \log \phi_{j}+\alpha\left(1-\sum_{j=1}^{k} \phi_{j}\right) f(z;ϕ,α)=i=1∑mj=1∑k1{z(i)=j}logϕj+α(1−j=1∑kϕj)
那么我们可以得到:
{ ∂ f ∂ ϕ j = ∑ i = 1 m 1 { z ( i ) = j } ϕ j − α = 0 ∂ f ∂ α = 1 − ∑ j = 1 k ϕ j = 0 \left\{\begin{array}{c}{\frac{\partial f}{\partial \phi_{j}}=\sum_{i=1}^{m} \frac{1\left\{z^{(i)}=j\right\}}{\phi_{j}}-\alpha=0} \\ {\frac{\partial f}{\partial \alpha}=1-\sum_{j=1}^{k} \phi_{j}=0}\end{array}\right. {∂ϕj∂f=∑i=1mϕj1{z(i)=j}−α=0∂α∂f=1−∑j=1kϕj=0
带入上式有:
ϕ j = 1 α ∑ i = 1 m 1 { z ( i ) = j } \phi_{j}=\frac{1}{\alpha} \sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\} ϕj=α1i=1∑m1{z(i)=j}
那么有:
∑ j = 1 k ϕ j = ∑ j = 1 k 1 α ∑ i = 1 m 1 { z ( i ) = j } = 1 α ∑ i = 1 m ∑ j = 1 k 1 { z ( i ) = j } = 1 α ∑ i = 1 m 1 = m α = 1 \sum_{j=1}^{k} \phi_{j}=\sum_{j=1}^{k} \frac{1}{\alpha} \sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\}=\frac{1}{\alpha} \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{z^{(i)}=j\right\}=\frac{1}{\alpha} \sum_{i=1}^{m} 1=\frac{m}{\alpha}=1 j=1∑kϕj=j=1∑kα1i=1∑m1{z(i)=j}=α1i=1∑mj=1∑k1{z(i)=j}=α1i=1∑m1=αm=1
那么有:
{ α = m ϕ j = 1 m ∑ i = 1 m 1 { z ( i ) = j } \left\{\begin{array}{c}{\alpha=m} \\ {\phi_{j}=\frac{1}{m} \sum_{i=1}^{m} 1\left\{z^{(i)}=j\right\}}\end{array}\right. {α=mϕj=m1∑i=1m1{z(i)=j}
实际上,我们可以从上得知,如果 z ( i ) {{z}^{\left( i \right)}} z(i) 是已知的,那么高斯混合模型的最大似然估计变得几乎与我们在估计高斯判别分析模型的参数时所具有的相同,除了这里 z ( i ) {{z}^{\left( i \right)}} z(i)正在起到类标签的作用。
然而,在我们的密度估计问题中, z ( i ) {{z}^{\left( i \right)}} z(i)是未知的。我们可以做什么?
EM算法是一种迭代算法,有两个主要步骤。 应用于我们的问题,在E步骤中,它试图“猜测 z ( i ) {{z}^{\left( i \right)}} z(i) 的值。在M步骤中,它根据我们的猜测更新模型的参数。 由于在M步骤中我们假设第一部分中的猜测是正确的,因此最大化变得容易。 下面是高斯混合模型的EM算法的伪代码:

在E步骤中,给定 x ( i ) {{x}^{\left( i \right)}} x(i)并使用当前设置的参数最后结合贝叶斯准则,我们计算得到参数 z ( i ) {{z}^{\left( i \right)}} z(i) 的后验概率:
p ( z ( i ) = j ∣ x ( i ) , ; ϕ , μ , Σ ) = p ( x ( i ) ∣ z ( i ) = j ; μ , Σ ) p ( z ( i ) = j ; ϕ ) ∑ l = 1 k p ( x ( i ) ∣ z ( i ) = l ; μ , Σ ) p ( z ( i ) = l ; ϕ ) \begin{aligned} p\left( {{z}^{\left( i \right)}}=j\left| {{x}^{\left( i \right)}},;\phi ,\mu ,\Sigma \right. \right)=\frac{p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}}=j;\mu ,\Sigma \right. \right)p\left( {{z}^{\left( i \right)}}=j;\phi \right)}{\sum\limits_{l=1}^{k}{p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}}=l;\mu ,\Sigma \right. \right)p\left( {{z}^{\left( i \right)}}=l;\phi \right)}} \end{aligned} p(z(i)=j∣∣∣x(i),;ϕ,μ,Σ)=l=1∑kp(x(i)∣∣z(i)=l;μ,Σ)p(z(i)=l;ϕ)p(x(i)∣∣z(i)=j;μ,Σ)p(z(i)=j;ϕ)
在这里, p ( x ( i ) ∣ z ( i ) = j ; μ , Σ ) p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}}=j;\mu ,\Sigma \right. \right) p(x(i)∣∣z(i)=j;μ,Σ) 由样本 x ( i ) {{x}^{\left( i \right)}} x(i)在均值为 μ j {{\mu }_{j}} μj ,协方差矩阵为 Σ j {{\Sigma }_{j}} Σj 的高斯分布上的概率给出;同时, p ( z ( i ) = j ; ϕ ) p\left( {{z}^{\left( i \right)}}=j;\phi \right) p(z(i)=j;ϕ)由 ϕ j {{\phi }_{j}} ϕj给出。在E步骤中计算的 w j ( i ) w_{j}^{\left( i \right)} wj(i)的值表示我们对 z ( i ) {{z}^{\left( i \right)}} z(i) 的“软”猜测。
此外,通过将M步骤中的参数更新与我们确切知道 z ( i ) {{z}^{\left( i \right)}} z(i) 时的公式进行对比,你可以发现它们是相同的,除了没有表明每个数据点来自哪个高斯分布的指示函数 1 { z ( i ) = j } 1\left\{ {{z}^{\left( i \right)}}=j \right\} 1{z(i)=j} ,而我们现在将其改为
二 Jessen不等式
为了更好地理解EM算法的原理,我们必须对子EM算法中运用广泛的Jessen不等式进行详细推导。
设 f f f 是一个定义域为实数集的函数。回想一下,如果 ∀ x ∈ R , f ′ ′ ( x ) ≥ 0 \forall x\in R,{f}''\left( x \right)\ge 0 ∀x∈R,f′′(x)≥0 ,那么 f f f 是一个凸函数。当对于 f f f 的向量输入,这是广义的条件,它的海森 H H H(hessian)矩阵 是半正定,即 H ≥ 0 H\ge 0 H≥0 。如果 ∀ x ∈ R , f ′ ′ ( x ) > 0 \forall x\in R,{f}''\left( x \right)>0 ∀x∈R,f′′(x)>0 ,那么我们说 f f f是严格凸函数(在向量值情况下,相应的表述为 H H H必须是严格的半正定的,记为 H > 0 H>0 H>0 。
那么Jessen不等式可以这样表述为: f f f是凸函数,即 ∀ x ∈ R , f ′ ′ ( x ) > 0 \forall x\in R,{f}''\left( x \right)>0 ∀x∈R,f′′(x)>0 ,假定 X X X 是随机变量,那么有 E [ f ( X ) ] ≥ f ( E X ) E\left[ f\left( X \right) \right]\ge f\left( EX \right) E[f(X)]≥f(EX) 。而且,如果 f f f是严格凸函数时,那么当且仅当 p ( X = E [ X ] ) = 1 p\left( X=E\left[ X \right] \right)=1 p(X=E[X])=1 时, E [ f ( X ) ] ≥ f ( E X ) E\left[ f\left( X \right) \right]\ge f\left( EX \right) E[f(X)]≥f(EX) (即当 X X X 是常数时),其中, E ( X ) E\left( X \right) E(X)代表随机变量 的数学期望。其实这是Jessen不等式的一般形式,Jessen不等式的加权形式为: ∀ x ∈ R , f ′ ′ ( x ) ≥ 0 , q 1 , ⋯ , q n ∈ R + , ∑ i = 1 n q n = 1 \forall x\in R,{f}''\left( x \right)\ge 0,{{q}_{1}},\cdots ,{{q}_{n}}\in {{\mathbb{R}}^{+}},\sum\limits_{i=1}^{n}{{{q}_{n}}=1} ∀x∈R,f′′(x)≥0,q1,⋯,qn∈R+,i=1∑nqn=1 ,那么 ∑ i = 1 n q i f ( x i ) ≥ f ( ∑ i = 1 n q i x i ) \sum\limits_{i=1}^{n}{{{q}_{i}}f\left( {{x}_{i}} \right)\ge f\left( \sum\limits_{i=1}^{n}{{{q}_{i}}{{x}_{i}}} \right)} i=1∑nqif(xi)≥f(i=1∑nqixi) 恒成立。同理,如果当 f f f是个凹函数时,Jessen不等式的一般形式为: ∀ x ∈ R , f ′ ′ ( x ) ≤ 0 \forall x\in R,{f}''\left( x \right)\le 0 ∀x∈R,f′′(x)≤0 ,假定 X X X 是随机变量,那么有 E [ f ( X ) ] ≤ f ( E X ) E\left[ f\left( X \right) \right]\le f\left( EX \right) E[f(X)]≤f(EX) 。其加权形式为: ∀ x ∈ R , f ′ ′ ( x ) ≤ 0 , q 1 , ⋯ , q n ∈ R + , ∑ i = 1 n q n = 1 \forall x\in R,{f}''\left( x \right)\le 0,{{q}_{1}},\cdots ,{{q}_{n}}\in {{\mathbb{R}}^{+}},\sum\limits_{i=1}^{n}{{{q}_{n}}=1} ∀x∈R,f′′(x)≤0,q1,⋯,qn∈R+,i=1∑nqn=1 ,那么 ∑ i = 1 n q i f ( x i ) ≤ f ( ∑ i = 1 n q i x i ) \sum\limits_{i=1}^{n}{{{q}_{i}}f\left( {{x}_{i}} \right)\le f\left( \sum\limits_{i=1}^{n}{{{q}_{i}}{{x}_{i}}} \right)} i=1∑nqif(xi)≤f(i=1∑nqixi) 恒成立。下面对利用数学归纳法来证明Jessen不等式。
我们以 f f f是凸函数为例来证明Jessen不等式的加权形式。证明过程如下:
- 当 n = 1 n=1 n=1时, q 1 = 1 {{q}_{1}}=1 q1=1,那么 q 1 f ( x 1 ) = f ( x 1 ) = f ( q 1 x 1 ) {{q}_{1}}f\left( {{x}_{1}} \right)=f\left( {{x}_{1}} \right)=f\left( {{q}_{1}}{{x}_{1}} \right) q1f(x1)=f(x1)=f(q1x1) 恒成立。
- 当 n = 2 n=2 n=2时, q 1 + q 2 = 1 {{q}_{1}}+{{q}_{2}}=1 q1+q2=1 ,由于 f ′ ′ ( x ) ≥ 0 {f}''\left( x \right)\ge 0 f′′(x)≥0 ,那么根据不等式性质我们有: q 1 f ( x 1 ) + q 2 f ( x 2 ) ≥ f ( q 1 x 1 + q 2 x 2 ) {{q}_{1}}f\left( {{x}_{1}} \right)\text{+}{{q}_{2}}f\left( {{x}_{2}} \right)\ge f\left( {{q}_{1}}{{x}_{1}}+{{q}_{2}}{{x}_{2}} \right) q1f(x1)+q2f(x2)≥f(q1x1+q2x2)恒成立。
- 当 n ≥ 3 n\ge 3 n≥3时,假设当 n = k n=k n=k时 ∑ i = 1 k q i f ( x i ) ≤ f ( ∑ i = 1 n q i x i ) \sum\limits_{i=1}^{k}{{{q}_{i}}f\left( {{x}_{i}} \right)\le f\left( \sum\limits_{i=1}^{n}{{{q}_{i}}{{x}_{i}}} \right)} i=1∑kqif(xi)≤f(i=1∑nqixi)恒成立,那么只需证明,当 n = k + 1 n=k+1 n=k+1 时, ∑ i = 1 k + 1 q i f ( x i ) ≤ f ( ∑ i = 1 n q i x i ) \sum\limits_{i=1}^{k+1}{{{q}_{i}}f\left( {{x}_{i}} \right)\le f\left( \sum\limits_{i=1}^{n}{{{q}_{i}}{{x}_{i}}} \right)} i=1∑k+1qif(xi)≤f(i=1∑nqixi) 。那么 ∀ x ∈ R , f ′ ′ ( x ) ≥ 0 , q 1 , ⋯ , q k + 1 ∈ R + , ∑ i = 1 k + 1 q n = 1 \forall x\in R,{f}''\left( x \right)\ge 0,{{q}_{1}},\cdots ,{{q}_{k+1}}\in {{\mathbb{R}}^{+}},\sum\limits_{i=1}^{k+1}{{{q}_{n}}=1} ∀x∈R,f′′(x)≥0,q1,⋯,qk+1∈R+,i=1∑k+1qn=1 时,显然有:
∑ i = 1 k + 1 q i f ( x i ) = q k + 1 f ( x k + 1 ) + ∑ i = 1 k q i f ( x i ) = q k + 1 f ( x k + 1 ) + z k ∑ i = 1 k q i z k f ( x i ) ( z k = ∑ i = 1 k q i ) ≥ q k + 1 f ( x k + 1 ) + z k f ( ∑ i = 1 k q i z k x i ) ≥ f ( q k + 1 x k + 1 + z k ∑ i = 1 k q i z k x i ) = f ( ∑ i = 1 k + 1 q i x i ) \begin{aligned} & \sum\limits_{i=1}^{k+1}{{{q}_{i}}f\left( {{x}_{i}} \right)\text{=}}{{q}_{k+1}}f\left( {{x}_{k\text{+}1}} \right)\text{+}\sum\limits_{i=1}^{k}{{{q}_{i}}f\left( {{x}_{i}} \right)}\text{=}{{q}_{k+1}}f\left( {{x}_{k\text{+}1}} \right)\text{+}{{\text{z}}_{k}}\sum\limits_{i=1}^{k}{\frac{{{q}_{i}}}{{{\text{z}}_{k}}}f\left( {{x}_{i}} \right)\left( {{z}_{k}}=\sum\limits_{i=1}^{k}{{{q}_{i}}} \right)} \\ & \begin{matrix} {} & {} & {} & \ge {{q}_{k+1}}f\left( {{x}_{k\text{+}1}} \right) \\ \end{matrix}+{{\text{z}}_{k}}f\left( \sum\limits_{i=1}^{k}{\frac{{{q}_{i}}}{{{\text{z}}_{k}}}{{x}_{i}}} \right) \\ & \begin{matrix} {} & {} & {} & \ge \\ \end{matrix}f\left( {{q}_{k+1}}{{x}_{k\text{+}1}}+{{\text{z}}_{k}}\sum\limits_{i=1}^{k}{\frac{{{q}_{i}}}{{{\text{z}}_{k}}}{{x}_{i}}} \right)=f\left( \sum\limits_{i=1}^{k+1}{{{q}_{i}}{{x}_{i}}} \right) \\ \end{aligned} i=1∑k+1qif(xi)=qk+1f(xk+1)+i=1∑kqif(xi)=qk+1f(xk+1)+zki=1∑kzkqif(xi)(zk=i=1∑kqi)≥qk+1f(xk+1)+zkf(i=1∑kzkqixi)≥f(qk+1xk+1+zki=1∑kzkqixi)=f(i=1∑k+1qixi)
综合1)、2)、3)有,Jessen不等式恒成立。同理可证 f f f 是凹函数时的Jessen不等式恒成立。
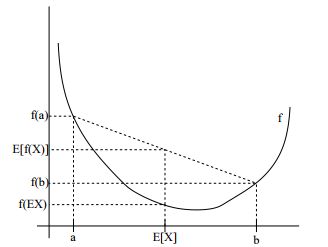
为了更好地理解Jessen不等式,我们来看上面的函数图。在图中, f f f是由实线表示的凸函数。 X X X是随机变量,各有0.5的概率取得变量 a a a和变量 b b b。因此, X X X的期望值由 a a a和 b b b之间的中点给出。我们还可以看到 f ( a ) f\left( a \right) f(a) , f ( b ) f\left( b\right) f(b)和 f ( E [ X ] ) f\left( E\left[ X \right] \right) f(E[X])在 y y y轴上的值。 E [ f ( X ) ] E\left[ f\left( X \right) \right] E[f(X)]现在是 f ( a ) f\left( a \right) f(a)和 f ( b ) f\left( b\right) f(b) 之间的中点。从我们的例子中,我们看到,因为 f f f是凸函数, E [ f ( X ) ] ≥ f ( E X ) E\left[ f\left( X \right) \right]\ge f\left( EX \right) E[f(X)]≥f(EX)恒成立。
因此,Jessen不等式也可以这样理解,当指定函数是凸函数时,函数值的加权平均大于等于自变量的加权平均后对应的函数值;当指定函数是凹函数时,函数值的加权平均小于等于自变量的加权平均后对应的函数值。
三 EM算法
假设我们有一个评估问题,其中有一个训练集 { x ( i ) , ⋯ , x ( m ) } \left\{ {{x}^{\left( i \right)}},\cdots ,{{x}^{\left( m \right)}} \right\} {x(i),⋯,x(m)} 由 m m m个独立的样本组成。我们希望利用数据来你拟合模型 p ( x , z ) p\left( x,z \right) p(x,z) 的参数,其中似然函数为:
ℓ ( θ ) = ∑ i = 1 m log p ( x ; θ ) = ∑ i = 1 m log ∑ p ( x , z ; θ ) \begin{aligned} \ell \left( \theta \right)=\sum\limits_{i=1}^{m}{\log p\left( x;\theta \right)=}\sum\limits_{i=1}^{m}{\log \sum{p\left( x,z;\theta \right)}} \end{aligned} ℓ(θ)=i=1∑mlogp(x;θ)=i=1∑mlog∑p(x,z;θ)
但是,明显寻找参数$\theta $ 极大似然估计是困难的。这里 z ( i ) {{z}^{\left( i \right)}} z(i) 是隐式随机变量;通常情况下,若果知道了 z ( i ) {{z}^{\left( i \right)}} z(i) ,那么极大似然估计就会很容易。
在这种情况下,EM算法给出了一种有效的估计最大值似然的方法.最大化 ℓ ( θ ) \ell \left( \theta \right) ℓ(θ)明显可能很困难,我们的策略是重复构造一个上确界(E-step),然后优化这个上下限(M-step)。
对于每一个 ,令 Q i {{Q}_{i}} Qi是 z z z的函数,且有 ∑ z Q i ( z ) = 1 \sum\nolimits_{z}{{{Q}_{i}}\left( z \right)=1} ∑zQi(z)=1, Q i ( z ) ≥ 0 {{Q}_{i}}\left( z \right)\ge 0 Qi(z)≥0 。那么根据Jessen不等式,我们有:
∑ i log p ( x ( i ) ; θ ) = ∑ i log ∑ p ( x ( i ) , z ; θ ) = ∑ i log ∑ z ′ ′ Q i ( z ( i ) ) p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) ≥ ∑ i ∑ z ′ Q i ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} \sum_{i} \log p\left(x^{(i)} ; \theta\right) &=\sum_{i} \log \sum p\left(x^{(i)}, z ; \theta\right) \\ &=\sum_{i} \log \sum_{z^{\prime \prime}} Q_{i}\left(z^{(i)}\right) \frac{p\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)} \\ & \geq \sum_{i} \sum_{z^{\prime}} Q_{i}\left(z^{(i)}\right) \log \frac{p\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)} \end{aligned} i∑logp(x(i);θ)=i∑log∑p(x(i),z;θ)=i∑logz′′∑Qi(z(i))Qi(z(i))p(x(i),z(i);θ)≥i∑z′∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ)
具体地说, f ( x ) = log x = ln x f\left( x \right)=\log x=\ln x f(x)=logx=lnx是凹函数,因为 ∀ x ∈ R + , f ′ ′ ( x ) = - 1 x 2 < 0 \forall x\in {{\mathbb{R}}^{+}},{f}''\left( x \right)=\text{-}\frac{1}{{{x}^{2}}}<0 ∀x∈R+,f′′(x)=-x21<0 。
现在,对于任何一组分布 Q i {{Q}_{i}} Qi ,公式(3)为 ℓ ( θ ) \ell \left( \theta \right) ℓ(θ) 给出了一个下界。 Q i {{Q}_{i}} Qi 有很多可能的选择。我们应该用哪一种?如果我们有一些目前想猜测的参数 θ \theta θ,很自然地让似然函数在 θ \theta θ 处的下界变小是我们的目标。即我们将使上面的不等式在 θ \theta θ 处等号成立。
为了一个特殊 θ \theta θ 是的上界变小,我们的推动过程中需要涉及Jessen不等式去等的条件。为了使等号成立,我们知道期望是常变量时将会带来高效率。即我们要求:
p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) = c \begin{aligned} \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\theta \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}\text{=}c \end{aligned} Qi(z(i))p(x(i),z(i);θ)=c
对于不依赖于 z ( i ) {{z}^{\left( i \right)}} z(i) 的常数 c c c ,只要满足 Q i ( z ( i ) ) ∝ p ( x ( i ) , z ( i ) ; θ ) {{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)\propto p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\theta \right) Qi(z(i))∝p(x(i),z(i);θ)如下条件即可。实际上,由于 ∑ z Q i ( z ( i ) ) = 1 \sum\nolimits_{z}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)=1} ∑zQi(z(i))=1 ,那么我们有:
Q i ( z ( i ) ) = p ( x ( i ) , z ( i ) ; θ ) ∑ z p ( x ( i ) , z ; θ ) = p ( x ( i ) , z ( i ) ; θ ) p ( x ( i ) ; θ ) = p ( z ( i ) ∣ x ( i ) ; θ ) \begin{aligned} Q_{i}\left(z^{(i)}\right) &=\frac{p\left(x^{(i)}, z^{(i)} ; \theta\right)}{\sum_{z} p\left(x^{(i)}, z ; \theta\right)}=\frac{p\left(x^{(i)}, z^{(i)} ; \theta\right)}{p\left(x^{(i)} ; \theta\right)} \\ &=p\left(z^{(i)} | x^{(i)} ; \theta\right) \end{aligned} Qi(z(i))=∑zp(x(i),z;θ)p(x(i),z(i);θ)=p(x(i);θ)p(x(i),z(i);θ)=p(z(i)∣x(i);θ)
因此,我们只是将 Q i {{Q}_{i}} Qi设置为 z ( i ) {{z}^{\left( i \right)}} z(i) 的后验分布, z ( i ) {{z}^{\left( i \right)}} z(i)是 x ( i ) {{x}^{\left( i \right)}} x(i) 的条件概率,且被$\theta $ 参数化。
现在,对于 Q i {{Q}_{i}} Qi 的选择,式(1)给出了我们试图最大化的对数似然的下界,这是E步骤。算法的M步骤中,最大化式(1)的参数 θ \theta θ ,从而获得一个新参数 。反复执行这两个步骤。上述就是EM算法的两个过程,具体流程如下所示:
R e p e a t u n t i l c o n v e r g e n c e { ( E - S t e p ) F o r e a c h i , s e t Q i ( z ( i ) ) = p ( z ( i ) ∣ x ( i ) ; θ ) ( M − s t e p ) S e t θ : = a r g m a x θ ∑ i ∑ z ( i ) Q i ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} & Repeat\text{ }until\text{ }convergence\text{ }\{ \\ & \begin{matrix} {} & {} & {} \\ \end{matrix}\left( E\text{-}Step \right) For\text{ }each\text{ }i,\text{ }set \\ & \begin{matrix} {} & {} & {} & {} \\ \end{matrix}\begin{matrix} {} & {} & {} & {} \\ \end{matrix}{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)=p\left( {{z}^{\left( i \right)}}\left| {{x}^{\left( i \right)}} \right.;\theta \right) \\ & \begin{matrix} {} & {} & {} \\ \end{matrix}\left( M-step \right)\text{ }Set\text{ } \\ & \begin{matrix} \begin{matrix} {} & {} & {} & {} \\ \end{matrix} & {} & {} & {} \\ \end{matrix}\theta \text{ }:=\text{ }arg\text{ }\underset{\theta }{\mathop{max}}\,\sum\limits_{i}{\sum\limits_{{{z}^{\left( i \right)}}}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\theta \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}}} \\ & \\ \end{aligned} Repeat until convergence {(E-Step)For each i, setQi(z(i))=p(z(i)∣∣∣x(i);θ)(M−step) Set θ := arg θmaxi∑z(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ)
我们怎么知道EM是否收敛?假设 θ ( t ) {{\theta }^{\left( t \right)}} θ(t) 和 θ ( t + 1 ) {{\theta }^{\left( t+1 \right)}} θ(t+1) 连续两次迭代的参数。接下来我们将证明 ℓ ( θ ( t ) ) ≤ ℓ ( θ ( t + 1 ) ) \ell \left( {{\theta }^{\left( t \right)}} \right)\le \ell \left( {{\theta }^{\left( t+1 \right)}} \right) ℓ(θ(t))≤ℓ(θ(t+1)),这也将解释EM为什么总是单调提高对数似函数。这个结果的关键在于我们对${{Q}_{i}}$的选择。具体来说,在EM算法的迭代过程中,参数将从开始 θ ( t ) {{\theta }^{\left( t \right)}} θ(t) ,那么我们令 Q i ( t ) ( z ( i ) ) = p ( z ( i ) ∣ x ( i ) ; θ ( t ) ) Q_{i}^{\left( t \right)}\left( {{z}^{\left( i \right)}} \right)=p\left( {{z}^{\left( i \right)}}\left| {{x}^{\left( i \right)}} \right.;{{\theta }^{\left( t \right)}} \right) Qi(t)(z(i))=p(z(i)∣∣x(i);θ(t)) 。我们在前面看到,这个选择确保了Jensen不等式能够取等。因此:
ℓ ( θ ( t + 1 ) ) ≥ ∑ i ∑ z ( i ) Q i ( t ) ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ( t + 1 ) ) Q i ( t ) ( z ( i ) ) ≥ ∑ i ∑ z ( i ) Q i ( t ) ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ( t ) ) Q i ( t ) ( z ( i ) ) = ℓ ( θ ( t ) ) \begin{aligned} & \ell \left( {{\theta }^{\left( t+1 \right)}} \right)\ge \sum\limits_{i}{\sum\limits_{{{z}^{\left( i \right)}}}{Q_{i}^{\left( t \right)}\left( {{z}^{\left( i \right)}} \right)}\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};{{\theta }^{\left( t+1 \right)}} \right)}{Q_{i}^{\left( t \right)}\left( {{z}^{\left( i \right)}} \right)}} \\ & \begin{matrix} {} & {} & \ge \\ \end{matrix}\sum\limits_{i}{\sum\limits_{{{z}^{\left( i \right)}}}{Q_{i}^{\left( t \right)}\left( {{z}^{\left( i \right)}} \right)}\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};{{\theta }^{\left( t \right)}} \right)}{Q_{i}^{\left( t \right)}\left( {{z}^{\left( i \right)}} \right)}} \\ & \begin{matrix} {} & {} & = \\ \end{matrix}\ell \left( {{\theta }^{\left( t \right)}} \right) \\ \end{aligned} ℓ(θ(t+1))≥i∑z(i)∑Qi(t)(z(i))logQi(t)(z(i))p(x(i),z(i);θ(t+1))≥i∑z(i)∑Qi(t)(z(i))logQi(t)(z(i))p(x(i),z(i);θ(t))=ℓ(θ(t))
那么,令 Q i = Q i ( t ) {{Q}_{i}}\text{=}Q_{i}^{\left( t \right)} Qi=Qi(t) , θ = θ ( t + 1 ) \theta \text{=}{{\theta }^{\left( t\text{+}1 \right)}} θ=θ(t+1)。为了得到式(2),我们令
θ ( t + 1 ) = a r g m a x θ ∑ i ∑ z ( i ) Q i ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} {{\theta }^{\left( t\text{+}1 \right)}}\text{=}arg\text{ }\underset{\theta }{\mathop{max}}\,\sum\limits_{i}{\sum\limits_{{{z}^{\left( i \right)}}}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\theta \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}}} \end{aligned} θ(t+1)=arg θmaxi∑z(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ)
因此,在 θ = θ ( t + 1 ) \theta \text{=}{{\theta }^{\left( t\text{+}1 \right)}} θ=θ(t+1) 处,该公式必须等于或大于在 θ ( t ) {{\theta }^{\left( t \right)}} θ(t) 处的。
因此,EM是的似然函数单调收敛。在我们的EM算法的编写,我们说我们运行它直到收敛。鉴于我们刚刚展示的结果,一个合理的收敛性测试检查是连续迭代之间 ℓ ( θ ) \ell \left( \theta \right) ℓ(θ)之间的误差是否小于一些容差参数,如果 ℓ ( θ ) \ell \left( \theta \right) ℓ(θ)改进过慢,那么我们说EM算法收敛。
那么如果我们定义如下函数:
J ( Q , θ ) = ∑ i ∑ z ( i ) Q i ( z ( i ) ) log p ( x ( i ) , z ( i ) ; θ ) Q i ( z ( i ) ) \begin{aligned} J\left( Q,\theta \right)=\sum\limits_{i}{\sum\limits_{{{z}^{\left( i \right)}}}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\theta \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}}} \end{aligned} J(Q,θ)=i∑z(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);θ)
从之前推导可以得知 ℓ ( θ ) ≥ J ( Q , θ ) \ell \left( \theta \right)\ge J\left( Q,\theta \right) ℓ(θ)≥J(Q,θ) 。那么EM算法也可以看成通过不断迭代, J ( Q , θ ) J\left( Q,\theta \right) J(Q,θ)不断逼近 ℓ ( θ ) \ell \left( \theta \right) ℓ(θ) 的过程,其中E步骤是最大化 Q Q Q(自我检查),然后M步骤就是最大化 θ \theta θ 。具体示意图如下所示。

四 再看高斯混合模型
根据我们对EM算法的一般定义,让我们回到我们在高斯混合中拟合参数 ϕ \phi ϕ, μ \mu μ和 Σ \Sigma Σ的旧例子上。
E步骤很简单。按照上面的算法推导,我们简单地令,
w j ( i ) = Q i ( z ( i ) = j ) = p ( z ( i ) = j ∣ x ( i ) ; ϕ , μ , Σ ) \begin{aligned} w_{j}^{\left( i \right)}={{Q}_{i}}\left( {{z}^{\left( i \right)}}=j \right)=p\left( {{z}^{\left( i \right)}}=j\left| {{x}^{\left( i \right)}} \right.;\phi ,\mu ,\Sigma \right) \end{aligned} wj(i)=Qi(z(i)=j)=p(z(i)=j∣∣∣x(i);ϕ,μ,Σ)
这里, Q i ( z ( i ) = j ) {{Q}_{i}}\left( {{z}^{\left( i \right)}}=j \right) Qi(z(i)=j)表示在分布 Q i {{Q}_{i}} Qi下 z ( i ) = j {{z}^{\left( i \right)}}=j z(i)=j的概率。
接下来是M步骤,我们需要最大化参数 ϕ \phi ϕ , μ \mu μ和 Σ \Sigma Σ。首先我们化简似然函数。其过程如下:
ℓ ( ϕ , μ , Σ ) = ∑ i = 1 m ∑ z ( i ) Q i ( z ( i ) ) log p ( x ( i ) , z ( i ) ; ϕ , μ , Σ ) Q i ( z ( i ) ) = ∑ i = 1 m ∑ j = 1 k Q i ( z ( i ) = j ) log p ( x ( i ) ∣ z ( i ) = j ; μ , Σ ) p ( z ( i ) = j ; ϕ ) Q i ( z ( i ) = j ) = ∑ i = 1 m ∑ j = 1 k w j ( i ) log 1 ( 2 π ) n 2 ∣ Σ j ∣ 1 2 exp ( - 1 2 ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) ) ϕ j w j ( i ) = ∑ i = 1 m ∑ j = 1 k w j ( i ) ( - n 2 log 2 π − 1 2 log ∣ Σ j ∣ + log ϕ j − log w j ( i ) − 1 2 ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) ) \begin{aligned} & \ell \left( \phi ,\mu ,\Sigma \right)=\sum\limits_{i=1}^{m}{\sum\limits_{{{z}^{\left( i \right)}}}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}\log \frac{p\left( {{x}^{\left( i \right)}},{{z}^{\left( i \right)}};\phi ,\mu ,\Sigma \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}} \right)}} \\ & \begin{matrix} {} & {} \\ \end{matrix}=\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{{{Q}_{i}}\left( {{z}^{\left( i \right)}}=j \right)}\log \frac{p\left( {{x}^{\left( i \right)}}\left| {{z}^{\left( i \right)}}=j \right.;\mu ,\Sigma \right)p\left( {{z}^{\left( i \right)}}=j;\phi \right)}{{{Q}_{i}}\left( {{z}^{\left( i \right)}}=j \right)}} \\ & \begin{matrix} {} & {} \\ \end{matrix}=\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}}\log \frac{\frac{1}{{{\left( 2\pi \right)}^{\frac{n}{2}}}{{\left| {{\Sigma }_{j}} \right|}^{\frac{1}{2}}}}\exp \left( \text{-}\frac{1}{2}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right) \right){{\phi }_{j}}}{w_{j}^{\left( i \right)}}} \\ & \begin{matrix} {} & {} \\ \end{matrix}\text{=}\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}}\left( \text{-}\frac{n}{2}\log 2\pi -\frac{1}{2}\log \left| {{\Sigma }_{j}} \right|+\log {{\phi }_{j}}-\log w_{j}^{\left( i \right)}-\frac{1}{2}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right) \right)} \\ \end{aligned} ℓ(ϕ,μ,Σ)=i=1∑mz(i)∑Qi(z(i))logQi(z(i))p(x(i),z(i);ϕ,μ,Σ)=i=1∑mj=1∑kQi(z(i)=j)logQi(z(i)=j)p(x(i)∣∣z(i)=j;μ,Σ)p(z(i)=j;ϕ)=i=1∑mj=1∑kwj(i)logwj(i)(2π)2n∣Σj∣211exp(-21(x(i)−μj)TΣj−1(x(i)−μj))ϕj=i=1∑mj=1∑kwj(i)(-2nlog2π−21log∣Σj∣+logϕj−logwj(i)−21(x(i)−μj)TΣj−1(x(i)−μj))
那么首先最大化 μ j {{\mu }_{j}} μj, ℓ ( ϕ , μ , Σ ) \ell \left( \phi ,\mu ,\Sigma \right) ℓ(ϕ,μ,Σ)对 μ j {{\mu }_{j}} μj求偏导有:
∂ ℓ ∂ μ j = ∂ ∂ μ j ∑ i = 1 m ∑ j = 1 k w j ( i ) ( - n 2 log 2 π − 1 2 log ∣ Σ j ∣ + log ϕ j − log w j ( i ) − 1 2 ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) ) = − ∑ i = 1 m 1 2 w j ( i ) ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) = ∑ i = 1 m w j ( i ) Σ j − 1 ( x ( i ) − μ j ) \begin{aligned} & \frac{\partial \ell }{\partial {{\mu }_{j}}}=\frac{\partial }{\partial {{\mu }_{j}}}\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}}\left( \text{-}\frac{n}{2}\log 2\pi -\frac{1}{2}\log \left| {{\Sigma }_{j}} \right|+\log {{\phi }_{j}}-\log w_{j}^{\left( i \right)}-\frac{1}{2}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right) \right)} \\ & \begin{matrix} {} & {} \\ \end{matrix}=-\sum\limits_{i=1}^{m}{\frac{1}{2}w_{j}^{\left( i \right)}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)} \\ & \begin{matrix} {} & {} \\ \end{matrix}=\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)} \\ \end{aligned} ∂μj∂ℓ=∂μj∂i=1∑mj=1∑kwj(i)(-2nlog2π−21log∣Σj∣+logϕj−logwj(i)−21(x(i)−μj)TΣj−1(x(i)−μj))=−i=1∑m21wj(i)(x(i)−μj)TΣj−1(x(i)−μj)=i=1∑mwj(i)Σj−1(x(i)−μj)
那么令上式等于0有:
μ j = ∑ i = 1 m w j ( i ) x ( i ) ∑ i = 1 m w j ( i ) \begin{aligned} {{\mu }_{j}}=\frac{\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}{{x}^{\left( i \right)}}}}{\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}}} \end{aligned} μj=i=1∑mwj(i)i=1∑mwj(i)x(i)
同理,接下来最大化 Σ j {{\Sigma }_{j}} Σj, ℓ ( ϕ , μ , Σ ) \ell \left( \phi ,\mu ,\Sigma \right) ℓ(ϕ,μ,Σ)对 Σ j {{\Sigma }_{j}} Σj求偏导有:
∂ ℓ ∂ Σ j = ∂ ∂ Σ j ∑ i = 1 m ∑ j = 1 k w j ( i ) ( - n 2 log 2 π − 1 2 log ∣ Σ j ∣ + log ϕ j − log w j ( i ) − 1 2 ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) ) = − ∑ i = 1 m 1 2 w j ( i ) ( x ( i ) − μ j ) T Σ j − 1 ( x ( i ) − μ j ) − ∑ i = 1 m 1 2 log ∣ Σ j ∣ = − 1 2 ∑ i = 1 m w j ( i ) [ Σ j − 1 − Σ j − 2 ( x ( i ) − μ j ) ( x ( i ) − μ j ) T ] \begin{aligned} & \frac{\partial \ell }{\partial {{\Sigma }_{j}}}=\frac{\partial }{\partial {{\Sigma }_{j}}}\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}}\left( \text{-}\frac{n}{2}\log 2\pi -\frac{1}{2}\log \left| {{\Sigma }_{j}} \right|+\log {{\phi }_{j}}-\log w_{j}^{\left( i \right)}-\frac{1}{2}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right) \right)} \\ & \begin{matrix} {} & {} \\ \end{matrix}=-\sum\limits_{i=1}^{m}{\frac{1}{2}w_{j}^{\left( i \right)}{{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}\Sigma _{j}^{-1}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}-\sum\limits_{i=1}^{m}{\frac{1}{2}\log \left| {{\Sigma }_{j}} \right|} \\ & \begin{matrix} {} & {} \\ \end{matrix}=-\frac{1}{2}\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}\left[ \Sigma _{j}^{-1}-\Sigma _{j}^{-2}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right){{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}} \right]} \\ \end{aligned} ∂Σj∂ℓ=∂Σj∂i=1∑mj=1∑kwj(i)(-2nlog2π−21log∣Σj∣+logϕj−logwj(i)−21(x(i)−μj)TΣj−1(x(i)−μj))=−i=1∑m21wj(i)(x(i)−μj)TΣj−1(x(i)−μj)−i=1∑m21log∣Σj∣=−21i=1∑mwj(i)[Σj−1−Σj−2(x(i)−μj)(x(i)−μj)T]
那么令上式等于0,我们有:
Σ j = ∑ i = 1 m w j ( i ) ( x ( i ) − μ j ) ( x ( i ) − μ j ) T ∑ = 1 m w j ( i ) \begin{aligned} {{\Sigma }_{j}}=\frac{\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right){{\left( {{x}^{\left( i \right)}}-{{\mu }_{j}} \right)}^{T}}}}{\sum\limits_{=1}^{m}{w_{j}^{\left( i \right)}}} \end{aligned} Σj==1∑mwj(i)i=1∑mwj(i)(x(i)−μj)(x(i)−μj)T
最后我们利用拉格朗日乘数法来最大化 ϕ j {{\phi }_{j}} ϕj。由于 ∑ j = 1 k ϕ j = 1 \sum\limits_{j=1}^{k}{{{\phi }_{j}}}=1 j=1∑kϕj=1,那么我们根据上述似然函数构造如下函数:
L ( ϕ ) = ∑ i = 1 m ∑ j = 1 k w j ( i ) log ϕ j + β ( 1 − ∑ j = 1 k ϕ j ) \begin{aligned} \mathcal{L}\left( \phi \right)=\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}\log {{\phi }_{j}}+}}\beta \left( 1-\sum\limits_{j=1}^{k}{{{\phi }_{j}}} \right) \end{aligned} L(ϕ)=i=1∑mj=1∑kwj(i)logϕj+β(1−j=1∑kϕj)
因此我们有:
∂ L ∂ ϕ j = ∑ i = 1 m w j ( i ) ϕ j − β = 0 ∂ L ∂ β = 1 − ∑ j = 1 k ϕ j = 0 \begin{aligned} & \frac{\partial \mathcal{L}}{\partial {{\phi }_{j}}}=\sum\limits_{i=1}^{m}{\frac{w_{j}^{\left( i \right)}}{{{\phi }_{j}}}}-\beta =0 \\ & \frac{\partial \mathcal{L}}{\partial \beta }=1-\sum\limits_{j=1}^{k}{{{\phi }_{j}}}=0 \\ \end{aligned} ∂ϕj∂L=i=1∑mϕjwj(i)−β=0∂β∂L=1−j=1∑kϕj=0
由于 ∑ j = 1 k w j ( i ) = 1 \sum\limits_{j=1}^{k}{w_{j}^{\left( i \right)}=1} j=1∑kwj(i)=1,那么可以求得:
ϕ j = 1 m ∑ i = 1 m w j ( i ) \begin{aligned} {{\phi }_{j}}=\frac{1}{m}\sum\limits_{i=1}^{m}{w_{j}^{\left( i \right)}} \end{aligned} ϕj=m1i=1∑mwj(i)
对于高斯混合模型(GMM)的个人理解:GMM就是首先假设 个分类,且每个分类服从于不同的高斯分布,且这 个不同的高斯分布的协方差矩阵完全相同。并且给这些高斯分布不同的初始概率(权重)。之后通过EM算法进行跟新模型的所有参数直至似然函数收敛。最终每组数据的 个不同分类的概率,去除概率最大对应的类别作为预测分类。