zookeeper基础学习(一)
一、什么是zookeeper
Zookeeper是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务
它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等
二、为什么用zookeeper
1、大部分分布式应用需要一个主控、协调器或者控制器来管理物理分布的子进程(如资源、任务分配等)
2、目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
3、协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
4、zookeeper可以提供通用的分布式锁服务,用以协调分布式应用
三、zookeeper的特性
zookeeper是简单的
zookeeper是富有表现力的
zookeeper具有高可用性
zookeeper采用松耦合交互方式
zookeeper是一个资源库
四、安装zookeeper
准备三个虚拟机、zookeeper的tar包、java环境
1、下载zookeeper并解压(略)、配置java环境(略)
2、将zookeeper/conf/zoo.cfg.template重命名为zoo.cfg
3、在安装目录下新建一个data目录然后在下面新建一个myid的文件存入一个当前节点的ID

4、修改配置
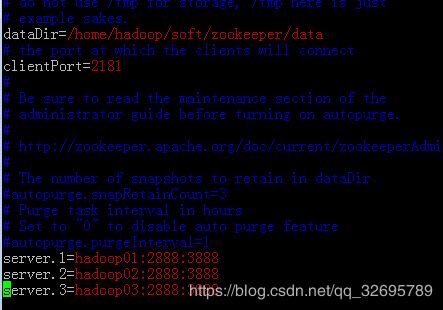
dataDir即为刚才创建的目录路径用于存储快照文件snapshot的目录
server.myid=IP:follower和leader之间的通信端口:投票选举端口
把所有zookeeper节点都在此处配置如果用域名需要再/etc/hosts下做对应配置
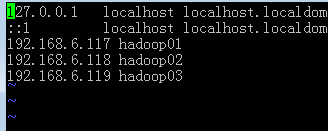
保存退出。然后在另外两台虚拟机上做相同的操作不过myid必须要保持各不相同
5、切换至安装目录下的bin目录
使用命令启动:./zkServer.sh start/stop(停止)/restart(重启)/status(查看状态)

其他两台机器做相同的操作(使用查看状态命令可以查看到谁是follwer谁是leader)
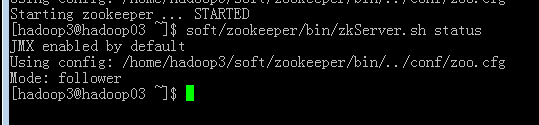
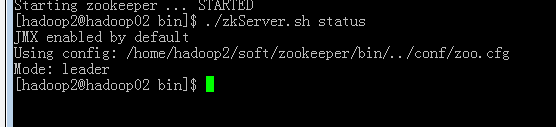

启动成功
五、zookeeper的数据模型
1、层次化的目录结构,命名符合常规文件系统规范
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3、节点Znode可以包含数据和子节点,但是EPHEMERAL类型的节点不能有子节点
4、Znode中的数据可以有多个版本,比如某一个路径下存有多个数据版本,那么查询这个路径下的数据就需要带上版本
客户端应用可以在节点上设置监视器
5、节点不支持部分读写,而是一次性完整读写
注:znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等等。
六、zookeeper的节点
1、Znode有两种类型,短暂的(ephemeral)和持久的(persistent)
2、Znode的类型在创建时确定并且之后不能再修改
3、短暂znode的客户端会话结束时,zookeeper会将该短暂znode删除,短暂znode不可以有子节点
4、持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除
5、Znode有四种形式的目录节点,PERSISTENT、PERSISTENT_SEQUENTIAL、EPHEMERAL、EPHEMERAL_SEQUENTIAL
备注:znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和 服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了;持久化目录节点,这个目录节点存储的数据不会丢失;顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名;临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超时,这种节点会被自动删除;临时自动编号节点
关于zookeeper的基础这篇先介绍到这儿之后会介绍zookeeper的节点角色、读写机制、API接口代码、观察、工作原理等等
本人QQ/wechat:806751350
本人github地址:https://github.com/linminlm