DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition 论文赏析
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition 论文赏析
- 前言
- Abstract
- Introduction
- Motivation
- Contributions
- Related Work
- Approach
- Basic and Notations of Compressed Video
- Overview
- DMC Generator
- Experiments
前言
最近拜读了Facebook AI发表在CVPR2019的文章《DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition》,感觉网络结构设计的非常巧妙,因此将阅读后的感受记录下来供大家参考。
文章简介:
出处: CVPR 2019
题目: 《DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition》
作者: Z h e n g S h o u 1 , 2 , X u d o n g L i n 2 , Y a n n i s K a l a n t i d i s 1 , L a u r a S e v i l l a − L a r a 1 , 3 , M a r c u s R o h r b a c h 1 , S h i h − F u C h a n g 2 , Z h i c h e n g Y a n 1 Zheng Shou^{1,2},Xudong Lin^2, Yannis Kalantidis^1, Laura Sevilla-Lara^{1,3},Marcus Rohrbach^1, Shih-Fu Chang^2, Zhicheng Yan^1 ZhengShou1,2,XudongLin2,YannisKalantidis1,LauraSevilla−Lara1,3,MarcusRohrbach1,Shih−FuChang2,ZhichengYan1
单位: 1 F a c e b o o k A I , 2 C o l u m b i a U n i v e r s i t y , 3 U n i v e s i t y o f E d i n b u r g h ^1Facebook AI, ^2Columbia University, ^3Univesity of Edinburgh 1FacebookAI,2ColumbiaUniversity,3UnivesityofEdinburgh
文章地址: https://arxiv.org/abs/1901.03460
Abstract
摘要部分总共有8句话,每两句话为一组。前四句话可以划分为一类,为叙述研究背景。从而引出本文的方法,用1句话去叙述本文方法的特点。最后用2句话描述实验结果及本文方法的有效性。可以看出作者的逻辑性非常清晰,概括性非常强。整个摘要按照“背景→问题→当前解决方案→存在的问题→本文方法→优势→实验结果验证有效性“这样一条主线进行阐述。

Introduction
本文所用的数据是经过MPEG压缩的视频,具体的MEPG压缩后的视频是什么样子的,下面会大体介绍。
Motivation
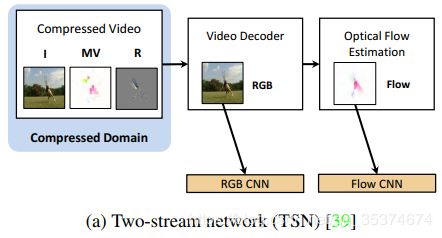
- 目前基于视频的动作识别效果最好、最流行的方法是双流网络。将静态的RGB帧和光流分别输入到两个深度神经网络中建模空间特征和时间特征。但是问题是光流的计算非常复杂,使算法的效率大大降低。(双流网络如图(a)所示)
- 原始的RGB视频中存在大量的重复性冗余信息,以致于掩盖了视频中的有效信息。(研究实验表明,一个时长1h,720p,222GB的视频通过MPEG压缩后仅有1GB)
- 为了克服光流计算成本大的缺点,后来研究人员采用视频压缩后的运动矢量(Motion Vector, MV)和残差来表征运动信息。但是运动矢量存在误差,并且分辨率低,导致运动信息不完整。
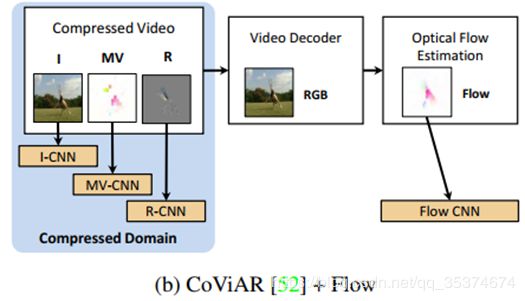
- 之前应用在压缩视频上的方法也是采用双流网络的思想,通过两个CNN分支处理运动矢量和残差。这样处理忽略了运动矢量和残差之间的联系,会影响模型的性能,如图(b)所示。(视频经过MPEG压缩后的运动矢量和残差之间是有联系的)
Contributions
关于本文的contribution,作者总结的已经很到位了,(偷个懒)直接将文中罗列的contributions拿过来了,如下所示:

首先,第一条是对本文整体框架的总结提炼,包含了所有的关键词,例如:本文的框架DMC-Net、压缩视频以及不需要光流;第二条是框架中的重点创新部分,即通过光流训练一个轻量生成网络来得到具有代表性的运动特征;第三条就是DMC-Net的有效性验证。
Related Work
相关工作部分从三个方面进行介绍,分别是:基于视频的动作识别、基于压缩视频的动作识别以及运动表征和光流估计。
本文的工作就是动作识别,所以作者先介绍了近年来在视频上做动作识别的相关工作,其中主流的方法主要包括双流网络、时间分割网络(Temporal Segment Network,TSN)以及3D卷积网络。主流方法的问题就是存在大量的参数需要训练学习,计算成本较高。引出下面的基于压缩视频的动作识别。
CVPR2018的文章《Compressed Video Action Recognition》第一次将深度结构直接应用在压缩视频,并取得了不错的效果。但是,其用到的运动矢量有一定的噪声,加上是将运动矢量和残差分开处理,忽略了它们之间的交互联系,所以存在一定局限性。
第三部分叙述了光流的特性,并引出本文方法,叙述了与光流的不同之处。

Approach
方法论部分从四个方面进行介绍。首先简单介绍了本文的基础,即MPEG-4压缩视频;随后重点介绍了本文的主要创新点,即DMC生成网络以及如何进行联合训练。最后简要说明了DMC-Net的推理性能。

Basic and Notations of Compressed Video
本文用的数据集是通过MPEG-4压缩后的压缩视频。这里简要说一下MPEG压缩,具体的压缩原理可以参考下面的文章。
一个RGB视频经过MPEG压缩之后会生成三种格式的“帧“(在这里暂且称之为帧,可能不是很准确),即:I-VOP(I-frame)、P-VOP(P-frame)和B-VOP(B-frame)。其中,压缩后,每个I帧后面跟着11个连续的P帧或B帧。具体是跟P帧、B帧亦或两者都有可以根据自己的任务而定。下面是三种帧的特点:



MPEG编码原理参考:http://blog.chinaunix.net/uid-20769562-id-598970.html
文章中只用到了I帧和P帧,其中P帧编码后包括运动矢量和残差。DMC正式通过运动矢量和残差来模拟光流。下面是对P帧即对应的运动矢量和残差可视化的结果:

如作者所说,运动矢量可以从一定程度上描述object的运动特征,而残差反应的是object的轮廓特征,即与运动目标的边缘对齐。用原文的话说就是:The residual is often well-aligned with the boundary of moving object, which is more important than the motion at other locations for action recognition.
Overview
下面看一下本文方法的整体框图:
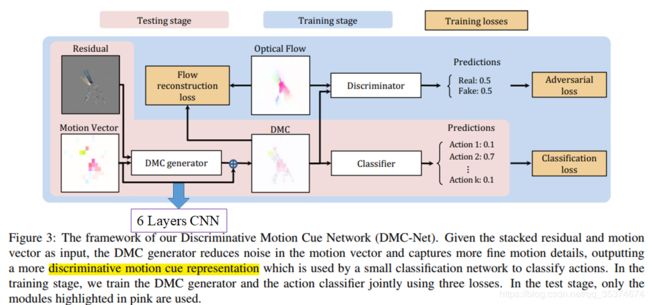
运动矢量和残差共同输入到DMC生成器中。这里DMC generator采用的是一个6层的CNN,结构如下所示:

至于为什么采用这样的结构,作者在文中分析了。如果采用其他的网络结构(比如ResNet、I3D等)会导致计算成本大大增加。为了选择合适的网络结构,作者通过网络结构搜索,找到了最优的结构,即如表2所示。
在训练DMC generator时是需要TV-L1光流作为监督信号来引导训练的(类似于AutoEncoder的原理),具体的训练方式以及loss在下一小节进行介绍。为了生成更具代表性和区别性的运动特征(先称之为DMC),作者引入了生成对抗网络(Generative Adversarial Network, GAN)的思想。采用一个判别器(discriminator)将真实光流和DMC分类。最后分类器采用两个ResNet分支分别对I帧(ResNet-152)和DMC(ResNet-18)进行分类。图中没有体现出双流分类网络,我想应该是都集成在Classifier中了。
在训练DMC generator和discriminator时采用交替训练规则(Alternating Training Procedure),即先固定DMC generator,训练discriminator;然后固定discriminator,训练DMC generator。
下面介绍将介绍每一部分的细节。
DMC Generator
在训练DMC generator的时候,用到了TV-L1光流监督信号。目的是使生成的DMC尽量趋近于真正的光流特征。在训练过程中,光流的重构误差采用的是均方误差(Mean Square Error,MSE):

通过最小化MSE,使得DMC接近于真实光流。但是,作者提到MSE loss基于数据服从高斯分布的假设,并且输出是smooth and blurry。真实的光流图像并不是光滑的,运动目标区域明显区别于背景。因此,为了得到具有分辨性的类光流特征,作者加入了GAN的思想,并使用Adversarial Loss训练,如下所示:
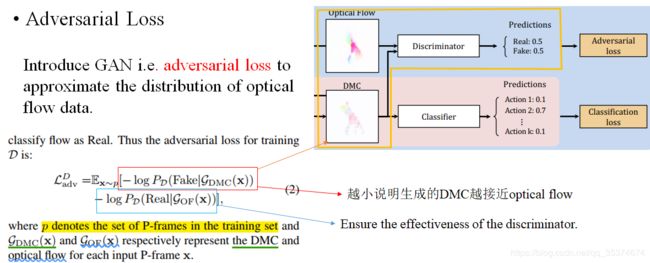
该部分为GAN的部分。看Adversarial Loss的红色框内的部分,为DMC generator生成错误的概率,也就是判别器可以轻松的识别DMC为假光流;而蓝色框部分为判断光流为真的概率,log内的概率P越大,说明判别器性能越好。我们的目标是DMC越接近光流越好,即使判别器将DMC判断为真光流最好。因此通过最小化该loss,既能保证DMC generator生成更加有效的DMC又可以保证discriminator性能最佳。
以上为训练discriminator时采用的Loss,在训练DMC generator时用到的Loss如下所示:

DMC generator与分类器是联合训练的。Total loss如下所示:
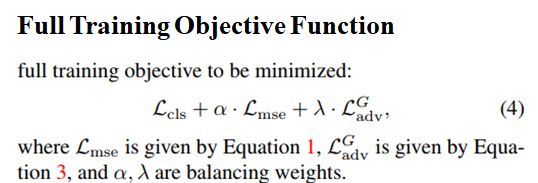
总的loss函数是分类器的loss L c l s L_{cls} Lcls、光流重构误差 L m s e L_{mse} Lmse以及adversarial loss L a d v G L_{adv}^G LadvG的加和。
总结: 以上便是本人对文章的拙见。我感觉作者的设计非常巧妙,思想新颖。通过压缩视频来模拟光流,充分利用了motion vector和residual之间的关联性,在保证识别精度的同时提升了模型的计算效率。将GAN的思想引入到网络结构中,为获得更有效的DMC特征提供了保障。(PS:通过听各位专家的报告我发现,不少模型中都引入了GAN的思想来辅助训练)
Experiments
实验部分包括5部分。如下图所示:

实验用到的数据集有:UCF-101,HMDB-51,Kinetics-n50(在Kinetics-400中采样出来部分数据)。作者首先简单介绍了用到的数据集。然后又介绍了具体的实验细节,所有的视频先被resized为340256大小。在数据输入网络前,都被cropped为224224大小。具体的如何翻转增强没有明确给出。
介绍完细节之后,就是对模型的效率以及有效性的分析。
上图是对模型效率的分析,可以看到DMC-Net(红色点)在保证精度的同时,能够节省大量的计算时间。

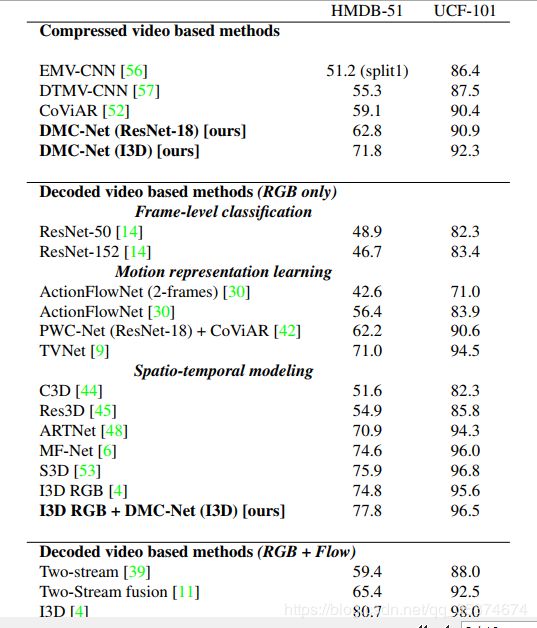
上图是可视化DMC的效果图。可以看到与Motion Vector相比,DMC生成的特征噪声更少,更有效。与其他方法相比,本文的方法同样能取得优越的效果。(在这里只截取部分实验结果,具体实验分析可通过阅读原文了解)
以上均是在下的一得之见,仅供参考。如有理解不到位的地方,还请大家批评指正,谢谢~