Spark2.2.2+Scala2.11.8+Intellij IDEA安装和开发
我的这篇博客是参照其他博客,我只是吧其中踩过的一些坑,详细写了一下,可以先看我的博客,然后具体的一些安装可以参照如下博客:
安装spark和scala参照博客:https://blog.csdn.net/quiet_girl/article/details/75585709
配置IDEA参照博客:https://www.jianshu.com/p/a5258f2821fc
一定要先安装好你的spark版本,然后再根据Spark_HOME/jars目录下的scala.xxxx.jar去安装Scala版本,因为在IntelliJIDEA中,需要配置好scala-sdk,然后将程序编译打包成.jar,用spark-submit提交运行,所以要保持scala版本一致。
1.安装Spark2.2.2
1下载安装包
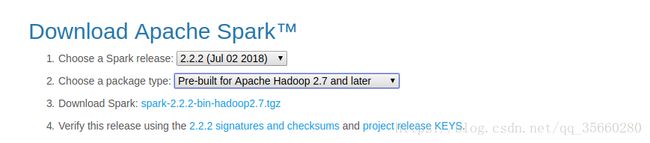
下载地址:http://spark.apache.org/downloads.html
下载版本: spark-2.2.2-bin-hadoop2.7.tgz
然后解压:
acer@acer-Aspire-V3-572G:~/下载/apk$ sudo tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz -C /usr/local/
acer@acer-Aspire-V3-572G:~/下载/apk$ cd /usr/local
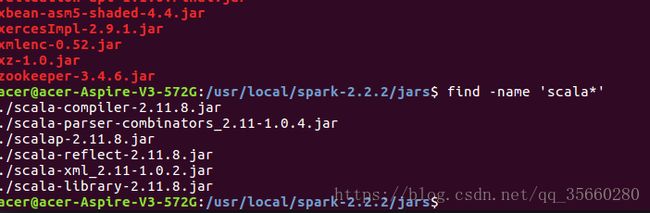
acer@acer-Aspire-V3-572G:~/下载/apk$ mv ./spark-2.2.2-bin-hadoop2.7 ./spark-2.2.2 //修改spark文件名字解压完成后可以查看你SPARK_HOME/jars目录下scala版本,如下图应该安装scala-2.11.8:
2配置环境变量
在hadoop用户(也就是安装了hadoop集群的用户)下配置,使用sudo vi ~/.bashrc打开环境配置文件,增加如下内容:
export SPARK_HOME=/opt/Hadoop/spark-2.1.0-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH使用source ~/.bashrc使之立即生效。
3修改配置文件
因为我是安装的单机版本,所以没有配置slaves,安装以下操作在$SPARK_HOME/conf/文件夹下操作,因为文件夹中只有默认配置文件,所以使用下面的命令,复制一份并重命名:
cp spark-env.sh.template spark-env.sh
使用sudo vim spark-env.sh打开文件,配置如下内容:
export SCALA_HOME=/usr/local/scala-2.11.8 //这一行可以在安装好scala后再进行配置
export JAVA_HOME=/usr/local/jdk1.8.0_181
export SPARK_MASTER_IP=127.0.0.1
export SPARK_WORKER_MEMORY=1g #注意:这个大小根据自己的情况可以改动
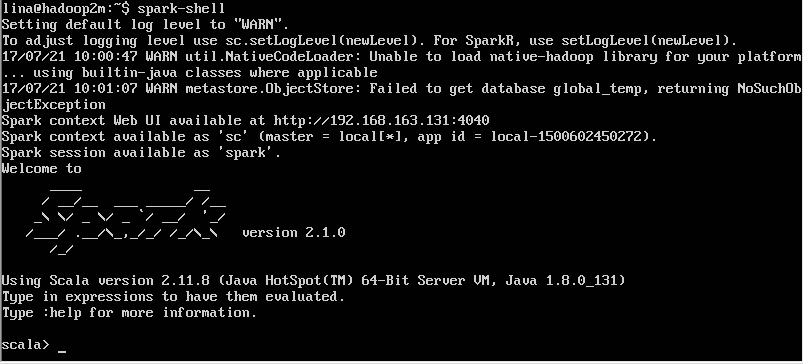
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop启动hadoop集群,使用spark-shell测试(根目录下即可),结果如下图(图是我盗来的,所以版本不一致):
2 scala安装
安装参照上面的我贴出的博客地址,教程很多,也很简单
3 安装IDEA
安装过程略
在IDEA中配置Scala,直接启动IDEA,然后file->setting
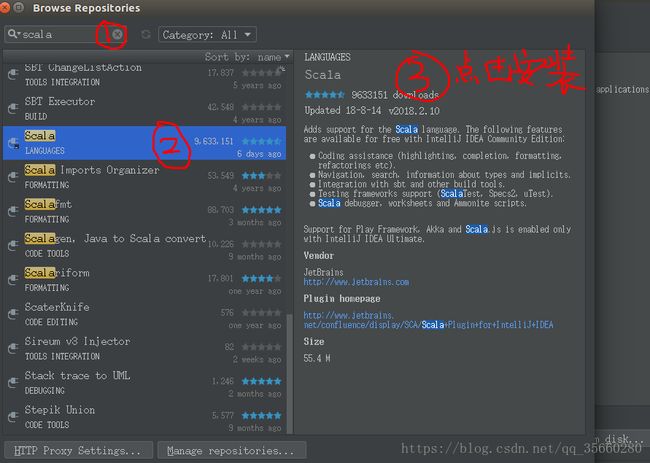
安装好scala插件后,就可以新建一个java工程file->new ->project
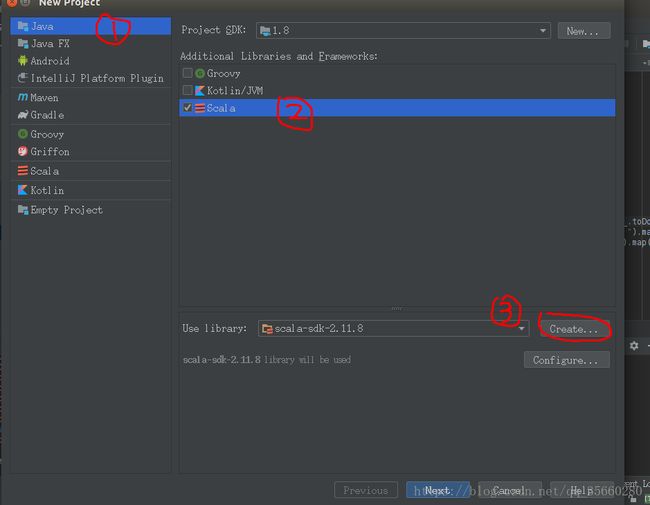
其中第三步,导入之间安装好的scala-2.11.8,我解压目录时/usr/local/scala-2.11.8

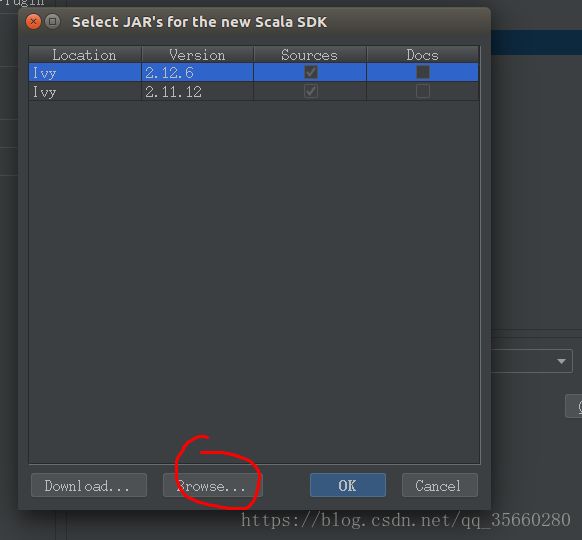
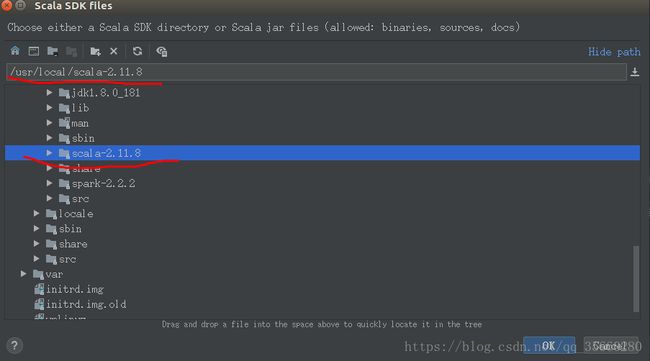
设置project名字,finish即可
接下来需要导入spark中的jars,和导入scala
file -> projectStructure ->Libraries

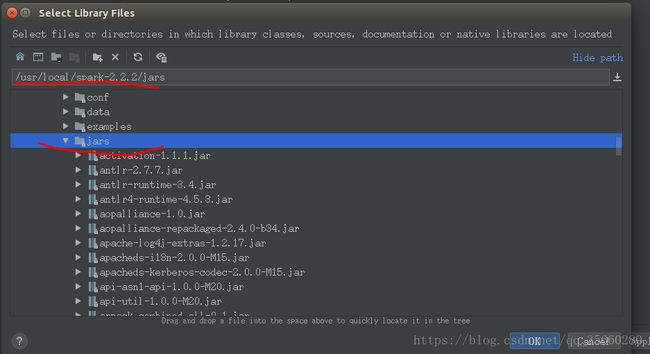
导入jars,一整个文件夹,然后继续配置Globel Libraries,将scala-2.11.8导入
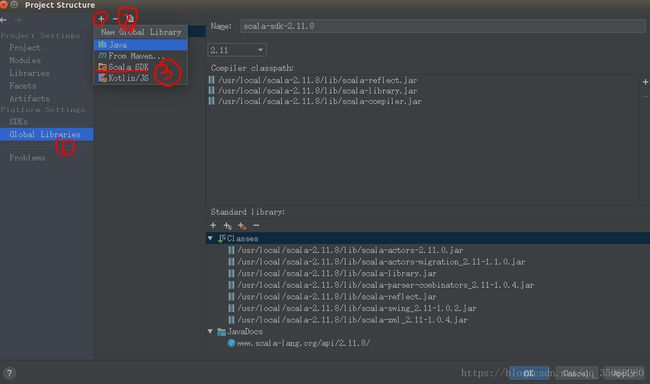
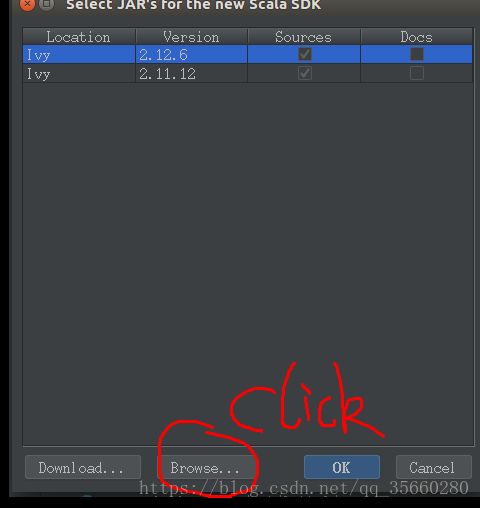

然后就可以在src下新建一个new -> package ,命名为test,然后在包下new->scala class 创建SparkDemo
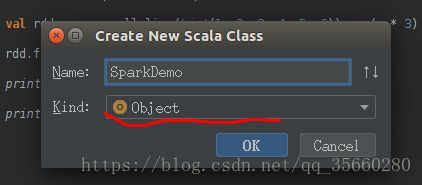
记住这里应该选择Object
代码如下:
package test
import org.apache.spark._
object SparkDemo {
def main(args:Array[String]){
val masterUrl = "local[1]"
val sparkconf = new SparkConf().setAppName("helenApp").setMaster(masterUrl)
val sc = new SparkContext(sparkconf)
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6)).map(_ * 3)
rdd.filter(_ > 10).collect().foreach(println)
println(rdd.reduce(_ + _))
println("hello world")
}
}
然后就可以右键 选择’Run 'SparkDemo'
打包jar包,使用spark-submit提交
file->projectStructure->Artifacts
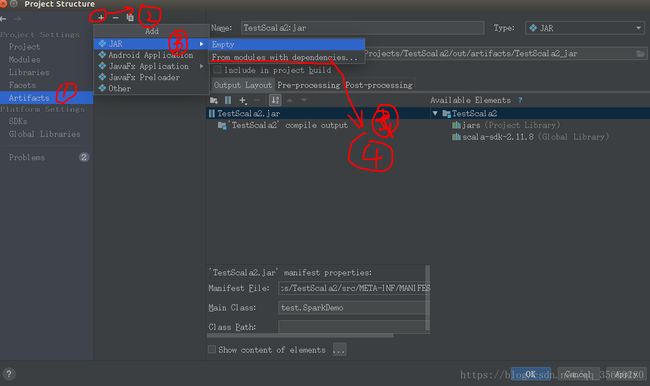
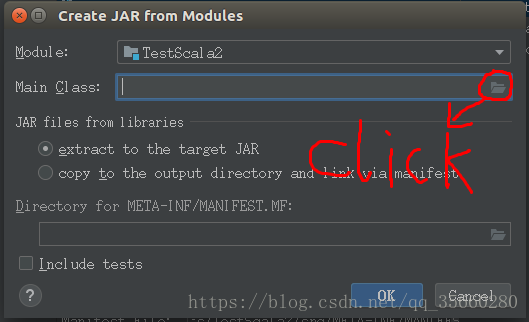
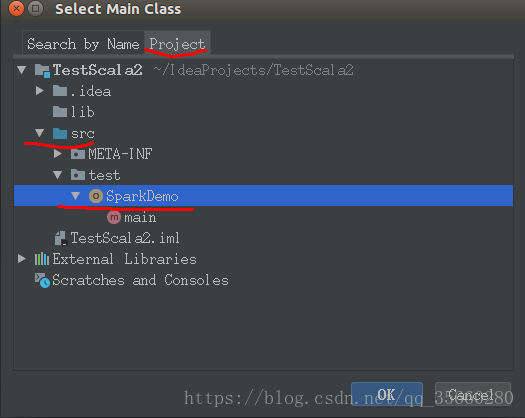
配置完成,点击ok
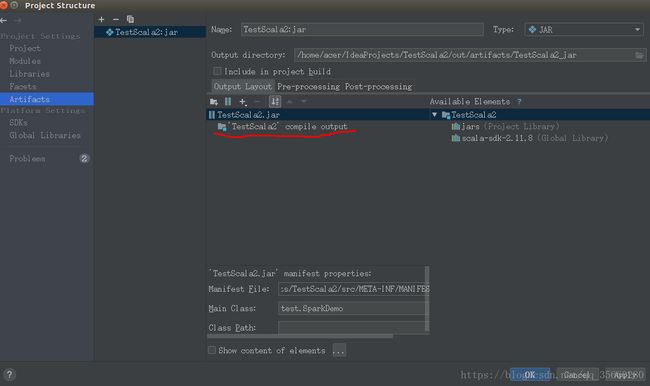
只留这一个文件
注意:打包的jar包不需要把spark源码也搞进去的,因为集群上本身就有spark代码,所以就留下以下这两个文件即可~~~ 点击apply –ok
在主界面,Build—Build Artifacts。开始编译~~~ 编译OK后会多出一个out目录,里面有最终jar包
在spark集群上运行jar 包
cd 到/usr/local/spark-2.2.2/下
hadoop@acer-Aspire-V3-572G:/usr/local/spark-2.2.2$ ./bin/spark-submit --class test.SparkDemo --master local /home/acer/IdeaProjects/TestScala2/out/artifacts/TestScala2_jar/TestScala2.jar
//--class 后面是主类,其中test是包名,SparkDemo是主类名
/home/acer/IdeaProjects/TestScala2/out/artifacts/TestScala2_jar/TestScala2.jar 这个时jar包路径
--master local 表示在本地执行配置IDEA参照博客:https://www.jianshu.com/p/a5258f2821fc