【扫盲】------Zipf分布
对于CDN的内容管理,有一个基本定律,就是大家常说对于内容的访问遵循80/20原则,也就是20%的内容,会占有80%的访问量。
这是一个定性的原则,定量来说,内容访问近似符合Zipf定律(Zipf's law), 这个定律是美国语言学家Zipf发现的,他在1932年研究英文单词的出现频率时,发现如果把单词频率从高到低的次序排列,每个单词出现频率和它的符号访问排名存在简单反比关系:

这里 r 表示一个单词的出现频率的排名,P(r)表示排名为r的单词的出现频率.
(单词频率分布中 C约等于0.1, a约等于1)
后人将这个分布称为齐夫分布,这个分布是一个统计型的经验规律,描述了这样一个定理:只有少数英文单词经常被使用,大部分的单词很少被使用。这个定理也在很多分布里面得到了验证,比如人们的收入,互联网的网站数量和访问比例,互联网内容和访问比例(其他分布两个常数有所不同,a越大,分布越密集,对于VOD来说某些时候符合双zipf分布)。
下面是某个系统VOD内容的访问分布,第一幅图是访问频率曲线,Y轴是内容的访问次数,X轴是内容根据访问次数的排名, 我们可以看到,多数访问集中于少量内容上:
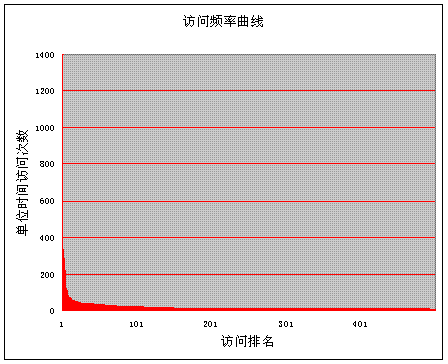
第二幅图是对数轴的访问频率曲线,源数据和上图一致,可以看到近似为一条直线:
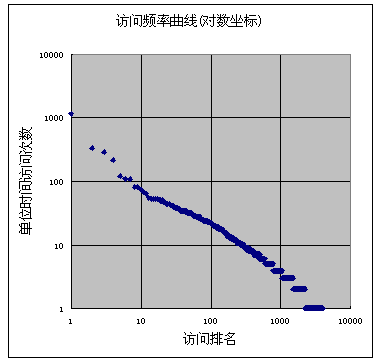
从曲线的斜率可以计算出,这里的内容访问频率分布,a约等于0.6(不同种类的内容a的大小也不一样)。
1、Zipf分布

Zipf分布介绍
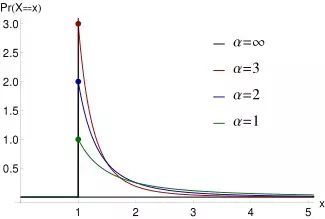
用X~Zipf(alpha,n)表示随机变量X具有带参数alpha和n的Zipf分布。带有参数alpha和n的Zipf随机变量X是有概率质量函数在里面。
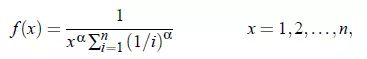
这里我们解释一下什么是概率质量函数:
在概率论中,概率质量函数 (Probability Mass Function,PMF)是离散随机变量在各特定取值上的概率。概率质量函数和概率密度函数不同之处在于:概率密度函数是对连续随机变量定义的,本身不是概率,只有对连续随机变量的取值进行积分后才是概率。
![]()
上面公式的含义为在随机变量X的映射函数下,所有样本空间中的结果在此映射下输出结果为x的概率。
属性如下:
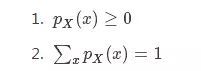
继续我们的介绍。对于所有正整数n和所有的alpha>0。Zipf分布可以用来解释人口中少数成员的相对受欢迎程度以及其他人口的相对默默无闻的程度。例子包括以下:
- 少部分网站获得了大量的点击量,大多数网站获得了适度的点击量,还有大量的网站几乎没有任何点击量。
- 图书馆有几本人人都想借的书(畅销书),大多数借阅的书(经典著作),还有大量几乎从未借过的书。
- 自然语言中使用频率很高的单词( "the" 和 "of" 排在英语前两位),大多数单词频率使用较低(如“butter”和“joke”),还有大量的词汇很少人用(如“defenestrate”,“lucubration” 或 “mascaron”等。
alpha = 1 和 n = 10 的概率质量函数如下图所示:
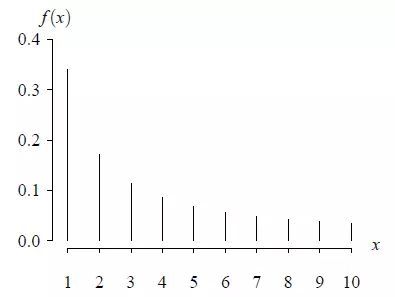
分母中的求和表示为:

另一种表现形式是:

X的累积分布函数:
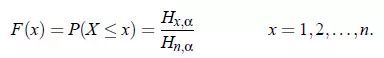
X的残存函数:
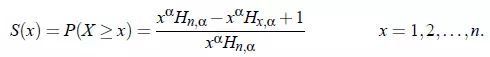
X的风险函数:
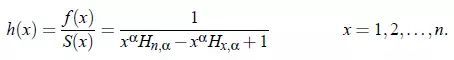
X的累积风险函数:
![]()
X的矩量母函数:
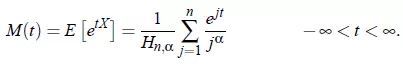
X的特征函数:
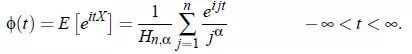
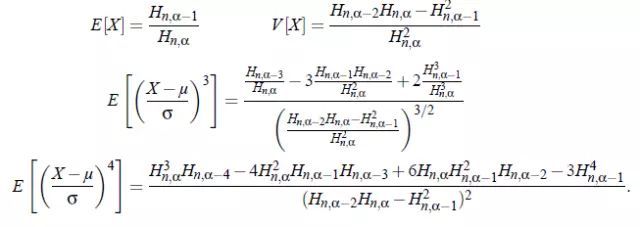
X的总体均值,方差,偏度,峰度:
2、Zeta分布
当n趋近于无限大时,Zipf分布就变成了Zeta分布。
Zeta分布介绍
X~Zeta(alpha)表示随机变量X的Zeta分布。参数alpha>1。
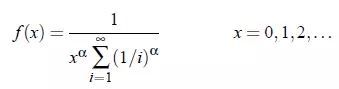
对于任何alpha> 1。alpha=2 的概率质量函数如下所示:
Zeta分布也可以认为是在离散概率分布中的帕累托分布。
帕累托分布以意大利经济学家 Vilfredo Pareto命名,他在1882年研究英国的财富分配情况时,发现前20%的人群拥有着社会80%的财富,这一现象可以用一个简单的概率分布函数来描述,即帕累托分布。
帕累托分布是一个skewed,厚尾(fat-tailed)分布。对于一个随机变量X来说,xm是X能取到的最小值,X的survival function是
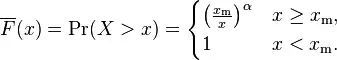
由此可以得到X的概率分布函数(c.d.f)
其中系数α为正,被称为shape parameter,或tail index。
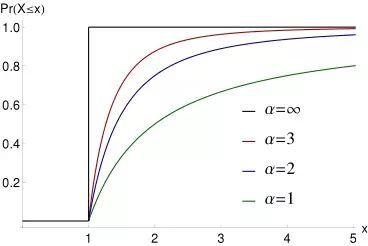
xm是1时,帕累托分布的累计概率分布函数图像为:
对应的密度函数为:
其他和Zipf类似,这里不再进一步描述。
3、Discrete uniform分布
Zipf分布满足上面的条件就会演变成离散均匀分布。
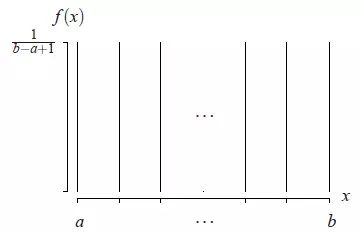
离散均匀分布介绍:
X∼discrete uniform(a,b)随机变量X和整数离散均匀分布参数a和b,a < b。

概率质量函数如下图所示:
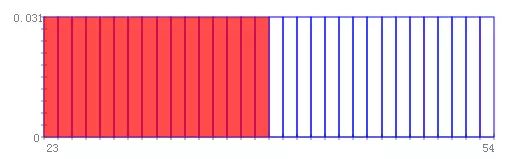
例如:a23,n=32,则:
X的累积分布函数:
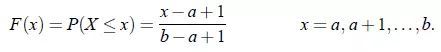
X的残存函数:
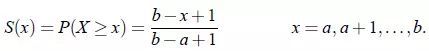
X的风险函数:
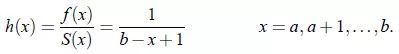
X的累积风险函数:
![]()
X的中位数m:
![]()
X的特征函数:
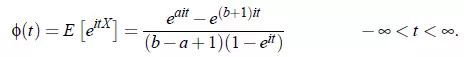
X的总体均值,方差,偏度,峰度:
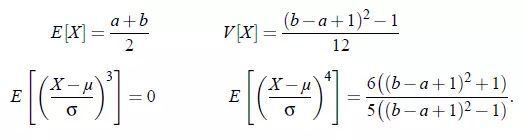
4、Rectangular分布

离散均匀分布满足上面的条件就会演变成Rectangular分布。
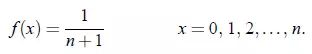
概率质量函数,n=5 如下图所示:
其他和离散均匀分布类似,这里不再进一步描述。
5、Beta-binomial分布

贝塔-二项式分布介绍:
反过来当满足a=b=1时,贝塔-二项式分布符合了Rectangular分布。
贝塔-二项分布:二项分布中的参数p不是固定的值,是服从Beta(a,b)分布。
计算公式:
![]()
其中L(p|k)表示二项式分布的最大似然估计计算方式。然后将
![]()
整合到p得:

期望:

二项分布就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
如果随机变量X服从二项分布,记为:
![]()
恒有
![]()
当n相当大时,只要p不太靠近0或1, 特别是当nπ和n(1-π)都大于5时,二项分布B(n,π)近似正态分布。
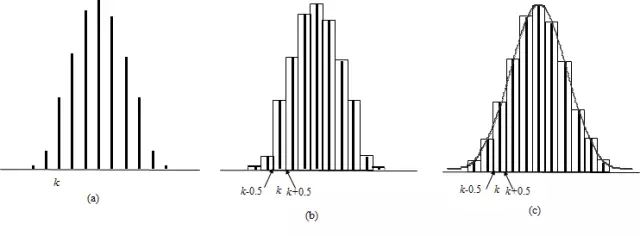
(a)概率函数直条图;(b)连续性校正直方图;(c)正态近似图
贝塔分布是一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,在机器学习和数理统计学中有重要应用。贝塔分布中的参数可以理解为伪计数,伯努利分布的似然函数可以表示为,表示一次事件发生的概率,它为贝塔有相同的形式,因此可以用贝塔分布作为其先验分布。
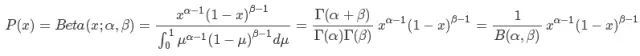
其中,B(a,b)是beta函数。
首先,现实生活中我们通常需要估计一件事情发生的概率,如抛一次硬币为正面的概率。我们可以进行统计的方式给出答案,比如抛了100次硬币,其中有30次向上,我们就可以说这个硬币为正面的概率是0.3。当然我们可以从另外一个角度回答问题,比我对实验的公信度进行怀疑,我就可以说为正面的概率是0.3的可能性是0.5,为0.2的可能性是0.2,为0.4的概率是0.3,给出硬币为正面的概率的分布,即伯努利实验中p的分布。给出参数的分布,而不是固定值,的好处有很多。
- 一,如抛100次中,30次向上,和抛100000次中30000次向上,两者估计p的值都是0.3。但后者更有说服力。如果前者实验得到p为0.3的置信度是0.5的话,后者实验得到p为0.3的置信度就有可能是0.9,更让人信服。
- 二,估计一个棒球运动员的击球命中率。如果我们统计一个新棒球运动员的比赛次数,发现,3场比赛中,他击中2次,那么我们可以说他的击球命中率是2/3么?显然不合理,因为因为根据棒球的历史信息,我们知道这个击球率应该是0.215到0.36之间才对。但如果我们给出的是击球明中率的分布,而不是固定的值,就可以表示我们对当前击球命中率估计的置信度,提供了更加丰富的信息。因为只观察了三次比赛,所以我们得到运动员命中率为2/3的概率是0.1,表示我们对这个命中率值不确定。
由前面可知,我们的需求是为了模拟模型参数的模型,beta分布是来模拟”取值范围是从0到1时的模型的参数的分布”。比如就求抛硬币为正的概率p为例。如果我们知道p的取值,我们就可以计算抛10次硬币,其中有1次向上的概率是
![]()
有3次向上的概率是
![]()
有6次向上的概率是P
![]()
那么我们如何求p值呢? 前面说的有两种方法,一个是给固定的值 ,一个给值的密度分布函数。我们这里介绍后者,假设p值符合Beta分布。即
![]()
那么现在我们又做了10次实验,其中4次为正,6次为反,称为信息X。那么我们现在要计算得到信息X后概率p的分布,即P(p|X),根据贝叶斯条件概率计算公式
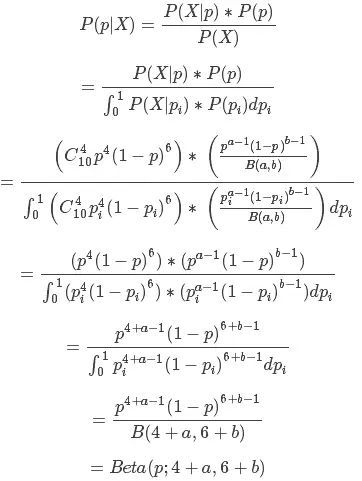
这里使用最大似然估计计算P(X|p),即
![]()
其中分子分母中
![]()
和是B(a,b)函数是常数项可以约去,最后得到:
![]()
总结:目的是计算得到p的概率分布,而不是固定的值。首先根据之前的经验或者统计,假设p服从Beta(a,b)分布,a表示之前统计中为正的次数,b为之前统计中为负的次数。接着,根据新做的实验或者新到达的信息X,来修正p的分布,修正后的p同样是服从Beta分布,只不过是参数由(a,b)变成(a+m,b+n),m表示新得到的信息中为正的次数,n表示新得到的信息中为负的次数。这样的修正过程可以很直观的被理解,而且修改前后是兼容的,很好的体现了一个学习修正的过程。
用X~betabinomial(a,b,n)来表示随机变量X具有a、b和n的贝塔-二项分布,其中a、b > 0和n为正整数。贝塔-二项式随机变量X与参数A、b和n具有概率质量函数。
贝塔-二项式随机变量是一个具有随机参数p的二项随机变量,它是具有与参数a和b的beta分布。
n = 20 的概率质量函数和3个不同参数如下图所示:
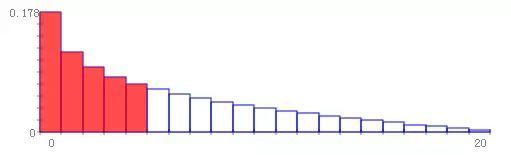
a = 0.7、b = 2

a = 2、b = 2
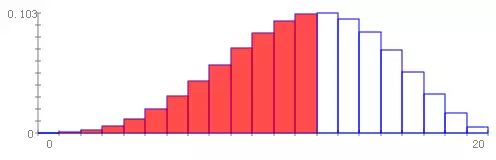
a = 6、b =4
X的总体均值,方差,偏度,峰度:

转自:
博客园:http://www.cnblogs.com/peon/articles/6146230.html
知乎:https://zhuanlan.zhihu.com/p/31917252