Spark系列(一) —— SparkCore详解
1. =》Spark 引入
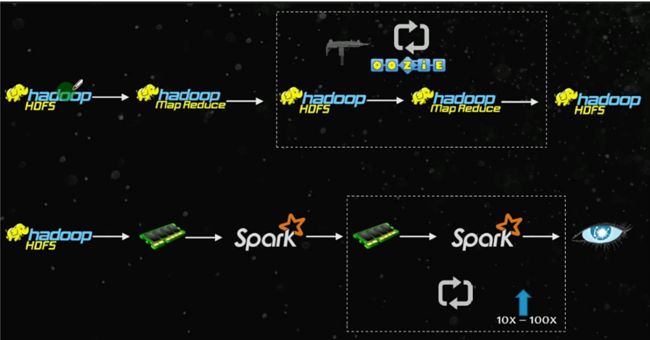
首先看一下 MapReudce 计算和 Spark 计算的区别:
MapReudce : 分布式计算框架
缺点:执行速度慢,shuffle 机制:数据需要输出到磁盘,而且每次 shuffle 都需要进行排序操作
框架的机制:只有 map 和 reduce 两个算子,对于比较复杂的任务,需要构建多个job来执行,当存在 job 依赖的时候,job 之间的数据需要落盘(输出到HDFS上),所以有IO瓶颈(磁盘IO,网络IO)。
Spark :基于内存的分布式计算框架
基于内存并不是所有数据都放在内存,只是说可以基于内存,速度很快。
Spark 是一个执行引擎,包括Spark SQL;Spark Streaming;MLib;Graphx,运行平台主要有:1. hadoop 即 yarn;2. Mesos(资源管理框架);3. standalone(spark自带的资源管理框架);4. local即本地;5. 云资源管理框架,例如阿里云等等
详细比较如下图:

如下图,MapReudce 运行时job之间的数据需要落盘(输出到HDFS上),Spark则是有选择性的放在内存中:
Spark运行模式(即spark应用运行在哪里)
local:本地运行(测试和开发)
standalone:使用spark自带的资源管理框架运行spark应用
yarn:将spark应用类似mr一样,提交到yarn上运行
mesos:类似yarn的一种资源管理框架
一般是standalone和yarn,更多的是yarn,特别大的公司,技术能力足够的情况下,有可能会选择mesos
2. =》SparkCore 案例
先用 WordCount 感受一下 spark 应用的编写。
这个案例主要是统计文本中的单词数量。
文件内容如下:
代码如下:
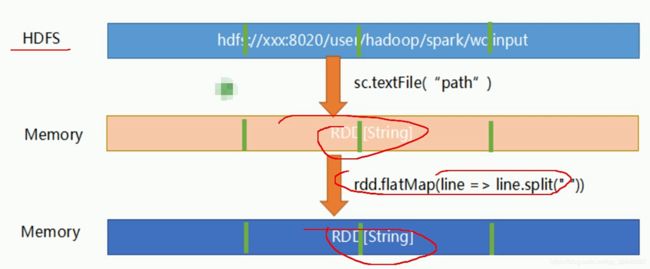
// 读取HDFS上的文件形成RDD
scala> var lines = sc.textFile("/spark/data/word.txt")
// scala> lines.map(line => line.split(" ")) 返回的数据结构:==> RDD[Array[String]]
// 以上操作之后,数据还是一行行的数据,只是每行数据从原来的一条字符串变成了一个数组的字符串,并不是
// 我们想要的效果,所以这里要使用flatMap
//转换处理
scala> var word = lines.flatMap(line => line.split(" ")) // 返回的数据结构:==> RDD[String]
scala> val word2 = words.map(word => (word,1)) // 返回的数据结构:==> RDD[(String,Int)]
scala> val wordCountRdd = words2.reduceByKey(_ + _)
scala> wordCountRdd.collect() // 先看一下统计结果
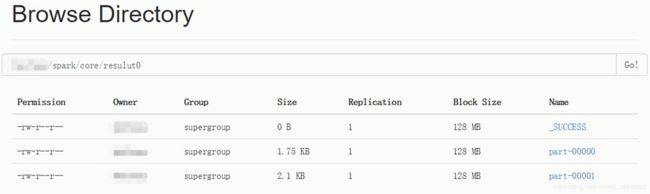
// 结果保存(要求输出文件夹不存在)
scala> wordCountRdd.saveAsTextFile("/spark/data/core/result0")
// 获取Top10单词
scala> wordCountRdd.sortBy(t => t._2 * -1).take(10)
scala> wordCountRdd.map(_.swap).top(10)打印出来的统计结果如下:
最后做成文件保存到HDFS上,如下:
这里可以把rdd当成是list,里面是一行一行的数据,注意rdd的数据以行为单位,每次操作都是对一行的数据进行操作。
为什么不用 groupByKey 而选择 reduceByKey ,groupByKey 可能导致加载所有的 key-value对 到内存中,如果有某些 key 有特别多的 value,会导致 OOM , Spark 的源码 PairRDDFunctions 类中明确写道建议使用 reduceByKey,有更好的性能
3. =》Spark 应用的监控
应用监控
1. 运维人员有专门的监控工具进行监控,比如:zabbix 等,可以监控服务器是否正常:内存、cpu、网络、磁盘IO、网络IO ,服务进程是否存在
2. 使用CM (CDH),Ambari (Apache)
3 .软件自带的 web 界面进行监控
4. oozie 等调度工具监控 job 的运行情况,调度异常,执行 java 程序发送短信
jps / jps | grep ...
针对正在运行的应用,可以通过webUI来查看,端口号默认4040,如果是运行在yarn上,直接在yarn的监控界面查看即可端口号默认8088
对于已经执行完的job,可以通过 Spark 的 job history 服务来查看,端口号默认18080
4. =》Spark 应用结构
MapReduce应用架构:
一个应用就是一个 job
一个 job 包含两个 stage,分别是 map 阶段和 reduce 阶段
每个阶段一个 task 任务(mapTask/ReduceTask)
执行任务的角色来讲:ApplicationMaster + container
Spark应用架构
一个应用可以包含多个 job,如下 图1 所示的 0-11 个job
一个job可以包含多个 stage,如下 图2 所示的 3 个stage
一个stage可以包含多个 task,如下 图3 所示的 5 个task
====》图一:
====》图2:
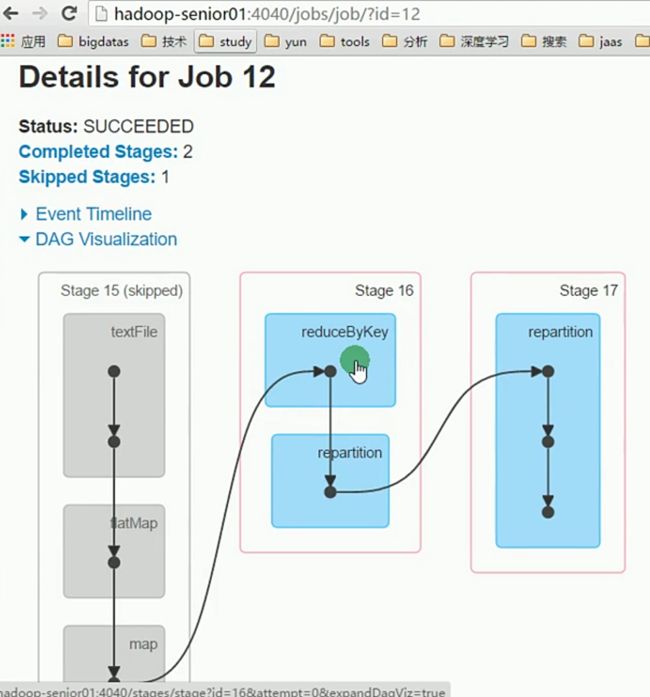
====》图3:
执行任务的角色来讲:
Driver + Executor
Driver :进行初始化操作的进程, main 方法的运行的JVM的地方,主要功能是:saprkContext上下文创建,RDD构建,RDD调度,RDD运行资源调度
Executor:真正运行Task任务的进程。
完整的运行架构如下:
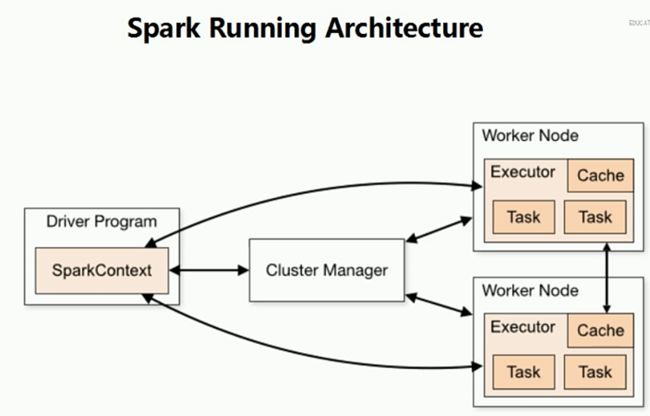
5. =》Spark on yarn 运行方式
bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class com.bigdata.spark.app.core.SparkWordCount \
/home/logs-analyzer.jar
脚本参数讲解:
--master 给定运行的spark应用的执行位置信息
--deploy-mode 给定driver在哪执行
client: driver 在执行spark-submit的那台机器上运行
cluster:driver 在集群中任选一台机器运行
--driver-memory MEM:指定driver运行时候的JVM的内存大小,默认1G,一般情况下要求比单个executor的内存要大。因为应用执行的结果是有可能返回给driver的。
--driver-cores MEM:spark on yarn cluster,给定driver运行需要多少个core,默认一个
--executor-memory MEM:指定单个executor的内存大小
--executor-cores NUM:运行环境为standalone/yarn,给定应用运行过程中每个executor包含的core数目 yanr默认1
--num-executors NUM:盛情多少个executor,默认2,这里即是nodemanager中的container数目
6. =》Spark RDD Job提交执行流程讲解
Spark应用的执行过程:
- 1. client 向资源管理服务(ResourceManager,Master等)申请运行的资源(driver资源),如果是client模式下,driver的资源不用进行申请操作,因为driver是在本地启动的,直接就有资源支持启动。只有在集群其他机器上,才需要申请。
- 2. 启动 driver
- 3. driver 向资源管理服务(ResourceManager,Master等)申请运行的资源(executor资源,可以理解为内存等资源)
- 4. 启动 executor
- 5. rdd 构建 和 rdd 执行
① Driver中RDD的构建
② RDD job被触发 (需要将RDD的具体执行步骤提交到executor中执行)
③ Driver中的DAGScheduler将RDD划分为Stage阶段
④ Driver中的TaskScheduler将一个一个stage提交到executor上执行
具体如下图:
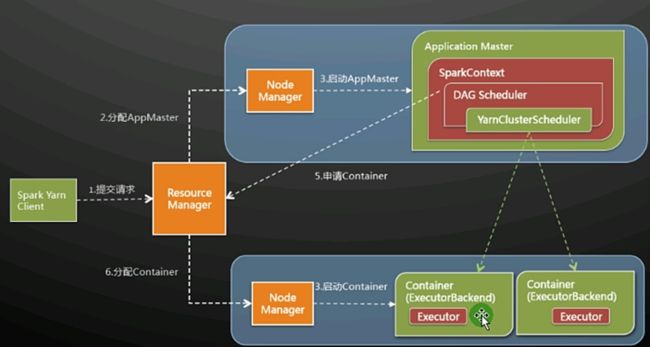
7. =》Spark内存资源管理机制
这里只讨论 Spark1.6 版本之后的内存管理机制:
内存管理分3个部分:
1. Reserved Memory:固定300M,不能进行修改,作用主要是加载class相对比较固定的对象以及计算最小Spark的Executor内存 = 1.5 * Reserved Memory = 450M
2. User Memory:用户代码中使用到的内存,默认占比 1 - spark.memory.fraction - 300M,即默认占比 25% - 300M
3. Spark Memory:Spark应用执行过程中进行数据缓存和shuffle操作使用到的内存
spark.memory.fraction:0.75,即默认占比 75%
缓存(Storage Memory,spark中所有数据缓存,包括RDD)和 shuffle(Execution Memory)的内存分配是动态的。spark.memory.storageFraction:默认0.5 => storage最少固定占用的内存大小比例
- a. 如果 Storage Memory 和 Execution Memory 都是空的(都有容量)如果有数据需要缓存,storage会占用execution部分的空余内存,同理,execution也会占用storage部分的空余内存。
- b. 如果 Storage Memory 满了,Execution Memory 有空余,如果有数据缓存操作,storage会占用execution部分的空余内存
如果有执行过程内存需要,execution操作会占用storage部分的内存,会将storage部分存储的数据进行删除
- c. 如果 Storage Memory 有空余,Execution Memory 满了,如果数据有缓存操作,不能占用execution部分的内存。
如果有执行过程内存需要,execution操作会占用storage部分的内存
备注:execution过程中使用到的内存是不允许进行删除操作的,storage的数据可以进行删除。
举个例子,假设Sparrk应用申请到了 1G 的资源,那么如何分配:
Reserved Memory : 300M
Spark Memory : (1G - 300M) * 0.75 = 543M , 其中Storage Memory最小 543M * 0.5 = 271M
User Memory : 1G - 300M - 543M = 181M
Spark 动态资源分配:
含义:指 Executor 的数量可以根据 job 中需要的资源来申请。有的job需要的Executor多,有的少,根据不同的Job的情况调整分配的 Executor 的数量,可以保证job能够快速执行,也保证不会出现资源浪费。
现阶段来讲,SparkStreaming中实现的不太好,SparkCore和SparkSQL都可以应用。
注意,下面的参数如果要配置,需要全部配置上去。
spark.dynamicAllocation.enabled:false,开启动态资源分配(true)
spark.dynamicAllocation.initialExecutors:初始化的时候给定默认executor的数量
spark.dynamicAllocation.maxExecutors:动态资源最多允许分配多少资源
spark.dynamicAllocation.minExecutors:0,动态资源最少允许分配多少资源
8. =》Spark RDD
工作中用到的API最多的就是4个:flatMap,filter,map,reduceByKey
RDD(弹性分布式数据集):
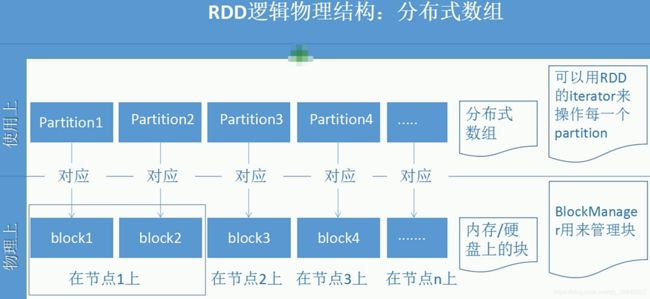
数据存储在HDFS上是以block形式存在的,spark读取并形成RDD的时候,没有限制条件的情况下,每一个block对应一个分区。每一个分区进行操作的时候,同样是一个分区对应一个分区,如下图4个分区,进行flatMap操作的时候,也是上面的4个分区进行操作生下一步的一一对应的4个分区。
弹性:可以存在给定不同数目的分区、数据缓存的时候可以缓存一部分数据,也可以缓存全部数据。
分布式:分区可以分布到不同的executor上执行,也就是不同的workwer/NM上。
数据集:内部存储是数据。
RDD中的数据是不可变的,是分区的。操作过程中不断形成新的RDD。
RDD五大特性:
1. 一系列的分片,类似Hadoop中的split
2.在每个分片上都有一个函数去迭代、执行、计算它
3. RDD之间一系列依赖
4. 对于key-value的RDD可指定一个partitioner,告诉它如何分片;常用的有hash,range
5. 数据本地化:要运行的计算最好在哪(几)个机器上运行,为什么会有哪几个呢?比如,Hadoop默认有3个位置,或者spark cache到内存是可能通过StorageLevel1设置了多个副本,所以一个partiton可能返回多个最佳位置。
RDD构建底层原理:
- 1. RDD分区数量 = InputFormat的getSplit方法返回的集合中split的数量
- 2. RDD中不包含数据,只包含数据存储的位置信息,这里的RDD指的是应用运行的第一个RDD,比如split,rdd的计算转换不算做构建。
RDD的创建:
- 1. 外部数据(非内存数据):基于MapReduce的InputFormat进行创建
sc.textFile ==> 底层使用TextInputFormat读取数据形成RDD;使用旧API
sc.newAPIHadoopFile ==> 底层使用TextInputFormat读取数据形成RDD;使用新API,可以指定使用哪个InputFormat读取数据。例如,读取redis的数据,只需要指定redis的InputFormat即可。
- 2. 内存中数据:基于序列化进行创建
val seq = List (1,2,3,4,5)
用户应用new SparkContext后,集群就会为在Worker上分配executor,但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,如此根据CPU的使用情况来分配executor数量,没有固定分配数量模式。
一个rdd分成几个partition,则有几个task,task被分配到节点中,每个节点的executor有几个core,则有几个task可以被并行执行,最大并行度即为节点数*core(虚拟核,并不是每个节点的cpu物理核,但一般虚拟核<=物理核) 。
假设:有5个节点,每个节点的executor有2个core;有1万条数据组成一个rdd,分成10个partition,则有10个task 。则每个节点分配到两个task并行执行。
9. =》RDD三大类型API
Spark应用的一般步骤:
创建上下文 => 读取RDD => RDD的转换 => 数据结果
RDD的方法类型(API类型)
1. transformation (transformation 算子):转换操作
功能:有一个RDD产生一个新的RDD。不会触发job的执行,在这些类型的API调用过程中,只会构建RDD依赖,也称为构建RDD的执行逻辑图(DAG图),即依赖关系。
2. action (action算子)::动作/操作
功能:触发rdd的job执行,并将rdd对应的job提交到executor上执行,最终的结果输出到其它文件系统,或者返回给driver.每次有一个action算子,spark监控页面上该应用的job页面
上就会多一条job记录。
transformation 算子执行和DAG创建都是在driver上完成的。DAG中间过程的执行是在action算子提交之后,到executor上执行
3. persist (RDD缓存/RDD持久化):
rdd将数据进行缓存操作或者清除缓存的rdd数据。或者数据进行了checkpoint(只在streaming中使用)
rdd.cache() 数据缓存到内存中
rdd.persist(xxx) 数据缓存到指定级别的存储系统中(内存/内存+磁盘/磁盘)
rdd.unpersist() 清除缓存数据
如下图,绿色的点就表示从绿色点的位置读取数据。原本reduceByKey触发的时候是从开始第一个RDD的数据源读取数据,但是如果cache()之后,后面的步骤会直接从cache()的位置读数据。缓存在内存中,那直接读,很快。缓存在磁盘中,是存储在本地磁盘,不需要通过网络IO,同样很快。

下图为缓存的信息,如图所示,缓存是以分区为最小单位的。缓存整数个分区。如果有内存就多存一点,否则就少存一点。具体见之前讲到的内存管理机制。图上是缓存了两个分区,如果只缓存一个分区,那么只有一个分区的数据会从内存读,另外一个分区的数据会从原始数据源开始读。

缓存级别如下:

10. =》SparkCore案例:分组排序TopN实现
按照第一个字段分组;同一组中按照第二个字段排序;每一组中,获取出现最多的钱k个数据。
案例数据如下:

案例代码如下:
val path = "data/groupsort.txt"
// 1. 创建SparkContext上下文
val conf = new SparkConf()
.setMaster("local")
.setAPPName("wordcount")
val sc = new SparkContext(conf)
// 2. 创建RDD
val rdd = sc.textFile(path)
// 3. RDD操作
val arrRDD = rdd.map(_.split(" ")) //一行数据整体做考虑的用map,一行数据单个元素做考虑的用faltMap
val tupleRDD = arrRDD.map(arr => (arr(0),arr(1).toInt))
val groupedRDD:RDD[(String,Iterable[Int])] = tupleRDD.groupByKey() // 注意groupByKey()之后的数据结构,key不变,而value变成了一个迭代器
val resultRDD = groupedRDD.map { // 下面开始组内排序
case (item1,iter) => { // 这里item1是key,iter是value
// 对iter进行排序然后获取数值最大的前k个数据
val topKItem2 = iter.toList //迭代器没有排序方法,需要转换成list
.sorted //list是有排序方法的,默认是升序排列
.takeRight(K) //因为是升序,要去取最大的,所以从右边开始获取K个元素,返回一个list
// 返回结果
(item1,topKItem2) // (key,(value1,value2,value3))的形式
topKItem2.map(item2 => (item1,item2 )) // (key,value1),(key,value2),(key,value3)的形式
}
}
// 4. 结果输出
resultRDD.forEachPartition (iter => { // 优先选择forEachPartition API
iter.foreach(println)
})
resultRDD.saveAsTextFile("result/topn")
Spark优化:
1.代码优化
a.如果一个RDD只使用一次,那么不赋值,直接转换操作 ( 链式编程 )。
b.对于多次使用的RDD,需要对 rdd 进行 cache 操作 ( rdd.cache() ),记住使用完成后,需要释放 ( rdd.unpersist() )。当然,如果只是SparkCore或者SparkSQL程序,job不是很多的情况下,也可以不释放,等应用执行完关闭的时候会自动清空内存,但是在运行过程中就不会释放了。
c. 优先选择 reduceByKey 和 aggregateByKey 替代 groupByKey。原因:groupByKey可能导致OOM,性能没有前两个API好(前两个API存在combine操作,在聚合之前会进行combine,和mapreduce的combine一模一样)
2. 资源优化 (见上第7点:Spark内存资源管理机制)
3.数据倾斜优化
导致原因:数据重新分配(shuffle)不均匀导致的,某几个key有大量的value,可能会导致某些 task 处理数据过多(分组的时候一个 key对应一个分区对应一个task),执行速度比较慢,或者出现OOM,去task监控界面看各个task的执行时间是否差距很大并且有异常即可判断是否出现数据倾斜。把数据拉下来,把这个代码统计之后看一下,各个分区的数据是多少。如何看:
rdd.foreachPartition(iter => {
iter.toList.size 或者 iter.count(t => true)
})
a. 更改分区策略(机制<自定义数据分区器>+分区数)例如groupByKey可以传参分区器和分区数。
b. 两阶段聚合
把 key 转换成 (random.nextInt(100),key),其中 random.nextInt(100) 表示0-99的随机值,这样聚合的时候就会先按照第一个元素(随机数)比较,然后再按第二个元素比较,这样就会把原来某个key的数据拆分到多个分区。第一阶段按随机数+key进行聚合,第二阶段将随机数去掉,再按key进行聚合。
只适用于聚合类shuffle操作(groupByKey、reduceByKey等),不适用于非聚合类shuffle操作(join等),可以将 reduce join 转为 map join
11. =》RDD依赖和RDD容错机制
RDD依赖
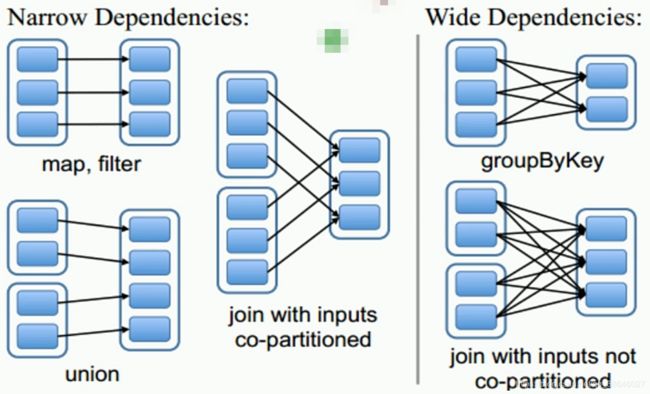
窄依赖:子RDD的每个分区的数据来常数个父RDD分区;父RDD的每个分区的数据到子RDD的时候在一个分区中进行处理。
父RDD和子RDD 一对一、多对一
常用方法:map、flatmap、filter、union、join(这种join要求两个父RDD具有相同的partitioner(指相同key的数据在两个父RDD中是在相同的分区,比如都在1分区或者都在2分区,不可能一个在1分区,一个在2分区)同时两个父RDD的分区数目一致)等
宽依赖:子RDD的每个分区的数据来自所有父RDD分区;父RDD的每个分区的数据都有可能分配到所有的子RDD分区中。
父RDD和子RDD 多(所有)对多
常用方法:xxxxByKey、join ( 不满足上面窄依赖join条件的join) 、repartition、distinct等。
如下图,左边是窄依赖,右边是宽依赖。
SparkCore 的容错:
1. driver宕机:
client:程序直接挂了
cluster:saprk on standalone/mesos:通过spark-submit的参数:--supervise可以指定driver宕机的时候,在其他的节点上重新恢复。
spark on yarn:自动恢复4次
2. executor宕机:
直接自动在worker或者nodeManager上重新启动一个executor重新执行任务
3. task 执行失败:
自动进行恢复,最大失败次数4次
4. 如果后续rdd执行过程中,出现数据丢失,容错方式为:lineage(生命线)==》 rdd的依赖。提供的一种容错机制,当子rdd执行失败的时候,可以从父rdd进行恢复操作;如果父rdd的执行结果进行了缓存操作,子rdd直接从缓存位置获取结果数据。如果cache的不是全部数据的话,那么部分数据从缓存中读取,其他数据从父rdd的数据来源读取(会存在父RDD代码逻辑的执行)。如果 子rdd失败的是单个分区,那么如果父rdd和子rdd的关系是窄依赖,只需回复父rdd对应分区的数据即可。如果关系是宽依赖,需要将所有父rdd的数据都执行一遍。
11. =》Spark应用调度详解、Stage划分规则、SparkContext源码解析
Spark应用的组成
Driver+Executors
Driver:SparkContext上下文的构建、RDD的构建、RDD的调度
Executor:具体task执行的位置
一个application ==> 多个 jobs ==> 多个stages ==> 多个tasks
job的产生:由于调用了RDD的action类型的API,所以触发rdd对应的job提交到executor中执行。
Stage:划分规则:当rdd的DAG图进行提交之前,Driver中的SparkContext中的DAGScheduler会对DAG进行划分,形成Stage;从DAG图的最后往前推,直到遇到一个宽依赖的API,那么就形成一个Stage,继续直到第一个RDD。Stage的执行是由依赖关系的,前一个Stage的数据结果是后一个Stage的数据输入;只有上一个Stage中的所有task都执行完了下一个Stage才会执行。
Stage的意义:数据本地化。
Task:executor 中执行的最小单位,task 实质上就是分区,一个分区的数据的代码执行就是一个task.
分区:从数据的分布情况来讲
task:从数据的执行逻辑情况来讲,每个task中的执行逻辑是一样的,只有处理的数据不一样,代码逻辑其实就是rdd的API组成的一个执行链
Saprk应用提交流程:
1. RDD调用transformation类型的API形成RDD的DAG执行图
2. RDD调用action类型的API触发job执行的提交操作
3. SparkContext中的DAGScheduler对RDD的DAG执行图进行Stage划分
4. SparkContext中的TaskScheduler对Stage进行task任务提交执行,将task提交到executor中执行(进行调度操作)
5. 等待task执行完成,当一个stage的所有task均执行完成后,开始下一个stage的调度执行,直到job执行完成。
Spark应用的执行过程:
Driver+Executor
spark on yarn: client: driver:负责applicationmaster的资源申请和任务调度
applicatonMaster:Executor中的资源申请
Executor: Task执行
cluster: Driver(applicatonMaster):资源申请和任务调度
Executor: Task执行
12. =》Spark Shuffle机制
上一个stage的数据到下一个stage需要进行一个重新的分配,在此过程中存在shuffle.
只存在于RDD的宽依赖中,有一个宽依赖就有一个shuffle过程。
mapreduce shuffle 是先把数据读到内存中,内存满的时候溢写到磁盘,形成一个一个文件,等到mapTask执行完成后进行合并。然后reduceTask去拿数据。
Spark shuffle 由 Spark shuffle manager 进行管理,参数spark.shuffle.manager:sort
shuffle优化:
-1. Spark shuffle manager : sort
当task的数量小于200的时候,会自动启动by_pass模式(没有数据排序的操作)
saprk.shuffle.sort.bypassMergeThreshold:200
-2. Spark shuffle manager :hash
当应用中的数据不需要进行排序的时候,可以直接考虑使用hash shuffle manager;当使用Spark shuffle manager的时候(当分区数比较多的时候),需要将参数:saprk.shuffle.consolidateFiles设置为true,表示开启文件合并功能。
未完待续:本文会比较长,打算把所有 SparkCore 的东西都总结在这一篇文章中,后续基本会每天更新一点。