SVM算法 K-means的python实现
arg
argument of the maximum/minimum
arg max f(x): 当f(x)取最大值时,x的取值
arg min f(x):当f(x)取最小值时,x的取值
s.t.是subject to (such that)的缩写,受约束的意思。
按中文习惯可以翻译成:使得...满足...(约束条件)
在求解最优化问题中,拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush Kuhn Tucker)条件是两种最常用的方法。在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件
(1)无约束条件
这是最简单的情况,解决方法通常是函数对变量求导,令求导函数等于0的点可能是极值点。将结果带回原函数进行验证即可
2)等式约束条件
设目标函数为f(x),约束条件为h_k(x)

则解决方法是消元法或者拉格朗日法。消元法比较简单不在赘述,这里主要讲拉格朗日法,因为后面提到的KKT条件是对拉格朗日乘子法的一种泛化。

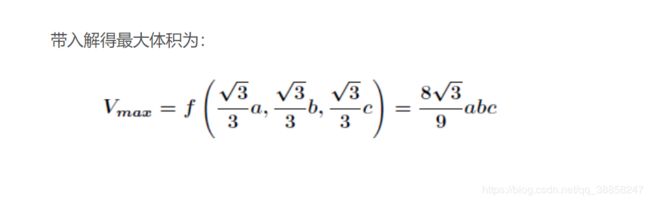
3)不等式约束条件(KKT
http://www.cnblogs.com/zhangchaoyang/articles/2726873.html
https://blog.csdn.net/johnnyconstantine/article/details/46335763
4.如果数据集中存在噪点的话----松弛变量
https://blog.csdn.net/d__760/article/details/80387432
5.数据并不是线性可分----核函数
K-Means算法
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
def loadDataSet(fileName):
'''
加载测试数据集,返回一个列表,列表的元素是一个坐标
'''
dataList = []
with open(fileName) as fr:
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine))
dataList.append(fltLine)
return dataList
def randCent(dataSet, k):
'''
随机生成k个初始的质心
'''
n = np.shape(dataSet)[1] # n表示数据集的维度
centroids = np.mat(np.zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = np.mat(minJ + rangeJ * np.random.rand(k,1))
return centroids
def kMeans(dataSet, k):
'''
KMeans算法,返回最终的质心坐标和每个点所在的簇
'''
m = np.shape(dataSet)[0] # m表示数据集的长度(个数)
clusterAssment = np.mat(np.zeros((m,2)))
centroids = randCent(dataSet, k) # 保存k个初始质心的坐标
clusterChanged = True
iterIndex=1 # 迭代次数
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = np.inf; minIndex = -1
for j in range(k):
distJI = np.linalg.norm(np.array(centroids[j,:])-np.array(dataSet[i,:]))
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print("第%d次迭代后%d个质心的坐标:\n%s"%(iterIndex,k,centroids)) # 第一次迭代的质心坐标就是初始的质心坐标
iterIndex+=1
for cent in range(k):
ptsInClust = dataSet[np.nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = np.mean(ptsInClust, axis=0)
return centroids, clusterAssment
def showCluster(dataSet, k, centroids, clusterAssment):
'''
数据可视化,只能画二维的图(若是三维的坐标图则直接返回1)
'''
numSamples, dim = dataSet.shape
if dim != 2:
return 1
mark = ['or', 'ob', 'og', 'ok','oy','om','oc', '^r', '+r', 'sr', 'dr', ' # draw all samples mark = ['Pr', 'Pb', 'Pg', 'Pk','Py','Pm','Pc','^b', '+b', 'sb', 'db', ' plt.show() if __name__ == '__main__': dataMat = np.mat(loadDataSet('./testSet')) #mat是numpy中的函数,将列表转化成矩阵 k = 4 # 选定k值,也就是簇的个数(可以指定为其他数) showCluster(dataMat, k, cent, clust)
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)
cent, clust = kMeans(dataMat, k)