题目:将25兆的数据读入内存中,并且根据数据中经度和维度,计算距离,将距离小于10千米的地址存入内存中,速度越快越好(只是POI底层的一个操作)
数据如下:
分别是用户ID 系统时间 纬度 经度 地点ID
具体思路:
将数据读入内存中 ,使用哈希表做索引去重,将location存入vector中,对vector进行两层迭代,计算距离值,将距离值小于10千米的存入内存中。
优化:
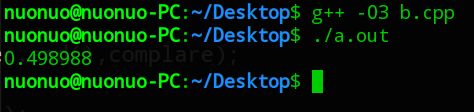
1)g++ -O3 编译优化(Linux版)
我们先看一下O3优化的成果
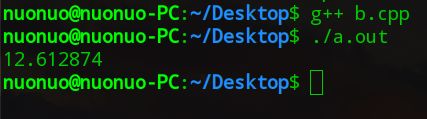

显而易见,-O3的优化是非常显著的。
1.介绍
gcc and g++分别是gnu的c & c++编译器 gcc/g++在执行编译工作的时候,总共需要4步
1.预处理,生成.i的文件[预处理器cpp]
2.将预处理后的文件不转换成汇编语言,生成文件.s[编译器egcs]
3.有汇编变为目标代码(机器代码)生成.o的文件[汇编器as]
4.连接目标代码,生成可执行程序[链接器ld]
2.参数设定
-O
接下来是-O变量。这个选项控制所有的优化等级。使用优化选项会使编译过程耗费更多的时间,并且占用更多的内存,尤其是在提高优化等级的时候。
-O设置一共有五种:-O0、-O1、-O2、-O3和-Os。你只能在/etc/make.conf里面设置其中的一种。
除了-O0以外,每一个-O设置都会多启用几个选项,请查阅gcc手册的优化选项章节,以便了解每个-O等级启用了哪些选项及它们有何作用。
让我们来逐一考察各个优化等级:
•-O0:这个等级(字母“O”后面跟个零)关闭所有优化选项,也是CFLAGS或CXXFLAGS中没有设置-O等级时的默认等级。这样就不会优化代码,这通常不是我们想要的。
•-O1:这是最基本的优化等级。编译器会在不花费太多编译时间的同时试图生成更快更小的代码。这些优化是非常基础的,但一般这些任务肯定能顺利完成。
•-O2:-O1的进阶。这是推荐的优化等级,除非你有特殊的需求。-O2会比-O1启用多一些标记。设置了-O2后,编译器会试图提高代码性能而不会增大体积和大量占用的编译时间。
•-O3:这是最高最危险的优化等级。用这个选项会延长编译代码的时间,并且在使用gcc4.x的系统里不应全局启用。自从3.x版本以来gcc的行为已经有了极大地改变。在3.x,-O3生成的代码也只是比-O2快一点点而已,而gcc4.x中还未必更快。用-O3来编译所有的软件包将产生更大体积更耗内存的二进制文件,大大增加编译失败的机会或不可预知的程序行为(包括错误)。这样做将得不偿失,记住过犹不及。在gcc 4.x.中使用-O3是不推荐的。
•-Os:这个等级用来优化代码尺寸。其中启用了-O2中不会增加磁盘空间占用的代码生成选项。这对于磁盘空间极其紧张或者CPU缓存较小的机器非常有用。但也可能产生些许问题,因此软件树中的大部分ebuild都过滤掉这个等级的优化。使用-Os是不推荐的。
但是在Windows下与Linux下的命令参数不同,有关请参考gcc官方手册
2)尽可能只调用一个函数,用宏定义替代函数,用乘法替代除法,用+=代替++,去掉printf
在追求速度的条件下,print是非常费时的一项操作
但是有时候全部都放到主函数效果并不好,子函数的变量可以随之释放掉,但是主函数却不可以
在汇编中所有+=都是要被转变成++的,替它省一步,将省很多时间哟!毕竟你做的可是几万次几十万次几百万次
3)用deque结构代替vetcor
deque是双向队列Double ended queue;can be accessed with random access iterator
deque是双端队列,是可以在两端扩展和收缩的连续容器。一般deque的实现是基于某种形式的动态数组,允许单个元素用随机获取迭代器随机读取,数组容量自动管理。
因此它有和vector相似的函数,但在序列的开始也有高效的插入和删除。但不像vector,deque的元素并不是严格连续存储的。
vector和deque有相似的接口和相似的目的,但内部实现截然不同。
4)用指针代替数组下标
这一步,我们首先想到的是用哈希表做一个索引,申请一个足够大的空间,以数据中地址编号作为数组下标(可以先遍历一遍,找出最小的地址编号是多少,最大的地址编号是多少,可以省很多事),在此基础上,我们用指针代替数组下标加快时间
5)距离计算基于Haversine进行坐标转换和三角函数拟合
首先根据球面模型,推导出球面余弦公式
根据公式我们进行变换得到Haversine(主要变换是消除了cos(jb-ja)项,解决了短距离求算时,对精度要求很高但是系统浮点数运算精度达不到的问题)
通过测试,我们发现,系统占用CPU主要进行的是对三角函数的计算。为了消除三角函数运算,我们将经纬度转换成地理坐标(x,y,z)
x = cos(lat)*cos(lon);
y = cos(lat)*sin(lon);
z = sin(lat);
这样在求夹角AOB的时候就可以只做点乘运算(x1*x2+y1*y2+z1*z2)从而避免大量三角函数的运算,在进行arccos()运算的时候我们将其转变成角度,AB弧长 = 夹角AOB * 地球半径R。
因为我们计算的距离较小(小于200千米其实就在一个城市)我们可以将sinAOB近似成AOB,由此我们可以将Math.acos(cosAOB)R 改为Math.sqrt(1 - cosAOBcosAOB)*R。
当距离小于200千米的时候,由于距离过小,我们可以将经纬度看成是垂直的,这个时候对于AB两点,我们只需求其对角线即可
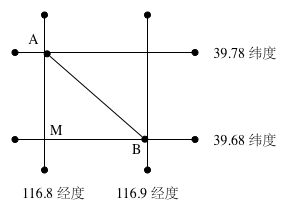
南北方向AM = R(地球半径)*rad(纬度差);
东西方向BM = R(地球半径)*rad(经度差)*cos<rad(纬度差)>
代码
到这里,整个计算距离公式我们只剩下一个cos函数,我们使用泰勒公式将其展开,因为不需要精度非常准确,我们泰勒公式只展开到二级多项式。
6)进一步优化
在同一经线,纬度每差1度,实地距离大约为111千米;
在纬线上,经度每差1度,实际距离为111×cosθ千米。(其中θ表示该纬线的纬度.在不同纬线上,经度每差1度的实际距离是不相等的)。
前边讲了,因为我们需要计算距离小于10千米的,我们的数据产生于一个城市,相差不超过200千米,基于这个我们将经纬度看成是相互垂直的。此时我们只需要计算两点之间经度差值大于0.1或者维度差值大于0.1,经度或者维度相差0.1则距离相差11.1千米,对于这样的地点对,我们就可以不计算其具体距离,跳过它。

我们将判断加上之后运行时间减少了一倍。


7)算法优化
我们将存好的地点按照维度从小到大进行排序,在做循环的时候,如果两个地址对的纬度相差大于0.1,我们就跳出内层循环。至此,我们花费在计算距离上的时间已经缩短到0.06s(在前边所有优化的前提下)加上把文件读取到内存的时间0.38s
STL库中的sort函数ccomplare是不能返回等于,只有明确的0和1。
将数据全部放入内存时数据结构的选取:
如果申请二维数组的话,30000*30000大小的数组是开不出来的,在Windows下,vector也有可能报错,因为vector申请的是连续的数组空间,这也就意味着,即使你的电脑还有1个G的内存可以用,但是仍然可能开不出来这么大的空间,但是用链表的话速度就达不到。
运行时间对比

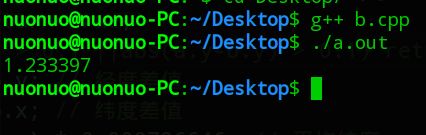
Linux下运行时间
参考资料
GCC官方文档
基于三次多项式拟合三角函数的地理空间距离计算算法
总结:
所有的投机取巧都不如算法来的快哈哈哈哈哈哈哈哈哈哈
源码及数据