最近经过一段对tensorflow和faster-rcnn的学习,并且亲身去跑了两个不同框架下的faster-rcnn代码,所以就在这里做一下总结。
这里,我就主要记录一下自己在跑tensorflow框架下的faster-rcnn。
首先,就是硬件要求,因为自己是做计算机图像,目标识别,所以最重要的一个提升效率的装备就是GPU,也就是显卡。现在能在GPU上进行运算,可以让我们的时间成本大大降低,当然,仅在CPU下也可以去跑,只是时间有些浪费。当然,自己还没有解决能并行GPU的运算,所以这里只能做到使用一块GPU。
具体环境要求:
1.Ubuntu 16.04系统、CUDA 8.0和cudnn(可以支持NVIDIA的GPU运算,当然有很多人在说这个环境,可以再参考其他相关文章)
2.python版本opencv和gpu版本的tensorflow
自己的python版本是2.7的, 所以自己就找了2.7版本的opencv和tensorflow(必须是gpu版,因为我们要使用gpu),当然至于去哪里找,大家都很清楚,我就不多说了。
那么我们有了硬件和具体环境,就开始我们的目标识别之旅吧!
一、数据集准备
我们在做目标识别时,大家都知道要有训练集、验证集以及测试集,当然数据集格式也有很多种,我们这里使用的是pascal_voc数据格式。我们在想训练自己数据集时,就可以仿照经典的VOC2007数据集去做,这里我就简单说一下,如下图是voc2007数据集文件夹格式
JPEGImages--------用来保存你的数据图片,当然,对于faster-rcnn来讲,所有的图片必须是jpg/jpeg格式,其他格式的话要转换一下。另外,一定要对图片进行编号,一般按照voc数据集格式,采用六位数字编码,如000001.jpg、000002.jpg等。
Annotations----------这里是存放你对所有数据图片做的标注,每张照片的标注信息必须是xml格式。
lmageSets-----------该文件下有一个main文件,main文件下有四个txt文件,分别是train.txt、test.txt、trainval.txt、val.txt,里面都是存放的图片号码,当然,我们现在只关注训练,所以要将所有用做训练的图片号码放入train.txt中,一行一个编号。
这里需要说明一下,如果想训练一个比较好的模型,数据集的量一定要大,自己之前使用了一个1000多张的训练数据集,经过自己验证,无法训练出来一个好的分类器模型。当然,大家想自己制作数据集,并且做标注,这也是一个十分大的工程,具体如何做标注,大家可以参考其他博客。
当然,大家只需要修改voc2007数据集中的这三个文件即可,这样就可以避免一些更繁琐的步骤。
二、程序和环境编译
我的建议是大家在运行前,先理解faster-rcnn结构,然后去看它的python版本和matlab版本代码,最后在下载faster-rcnn-tf的程序,这样会让我们在修改的时候节省很多时间,同时,也让自己的思路清晰。对于faster-rcnn-tf的程序,在github上有很多,所以大家自己选择一个,最主要的文件夹如下图:

data-----------------这里是用来存放你的数据图片的
experiments------这个文件夹决定了你要采用什么样的方式去训练你的数据,大家都知道,faster-rcnn提供了两种训练方式:
1.交替训练(alt_opt)
2.近似联合训练(end-to-end)
这里我们就使用的是第二种,因为它速度更快,同时也能保证准确率,但是两者修改代码是不一样的。
lib--------------------存放python的接口文件,如需要数据读入等。
tools-----------------存放的是训练、测试等python文件,这里是我们的重点。
output是用来存放自己训练好的模型的,所以在未训练前,里面是空的。我建议大家要仔细阅读README.md文件,可以很好的帮助我们运行程序。
我们现在已经有程序代码了,然后我们现在先建立Cython环境
进入终端,我们找到Faster-rcnn-TF的文件夹

点击回车,如果大家之前的软件环境都有的话,这一步会完成编译。
之后,我们需要下载一个已经训练好的模型,用来测试它的demo.py(也就是例程),这里直接用它README.md中给的网站下载就可以了,然后把模型放在tools/model(新建model文件夹)文件夹中就可以,方便我们调用。另外,这个程序是基于voc2007数据集训练的,所以它训练的是21类,测试例程的模型也是区分21类物体的。

这里,对于model模型存放的位置,大家根据自己修改,另外,对于tensorflow版本的模型来讲,它由三个文件(后缀名为data-00000-of-00001、index、meta)组成,所以大家只需要写到ckpt即可。这里我使用的是自己训练好的一个模型,所以大家凑合看即可。如果demo.py运行顺利,我们就可以训练自己的数据模型了。
三、训练
1.替换数据。大家应该提前下好voc数据集,并保存在data/VOCdevkit2007下,那么替换数据就是将自己训练集的Annotations、lmageSets和JPEGlmages文件和原文件替换即可。大家替换数据后,一定要将data/cache中的pkl文件删除,不然不会获得修改后的数据。
2.修改代码
我们采用的是VGG16的网络以及近似联合训练,所以修改也依据此。
(1)lib/datatsets/pascal_voc.py
(2)lib/datasets/imdb.py
(3)lib/networks/VGGnet_train.py
同理,VGGnet_test.py修改同上
(4)为了大家测试demo.py的方便,所以大家也把tools/demo.py中的类别改成自己的类别
(5)修改迭代次数等参数
这里大家根据自己的计算,选择合适的迭代次数以及学习率等, 个人认为,初试学习率0.001,如果不收敛再减小一个量级,另外,70000次在gpu(看自己的gpu性能,我的是1080)上跑,也只是需要半天多的时间,所以还是可以接受的迭代次数,至于选择多少迭代次数合适,可以根据不同次数训练好的模型,测试验证。
首先在experiments/scripts/faster_rcnn_end2end.sh文件中修改迭代次数:
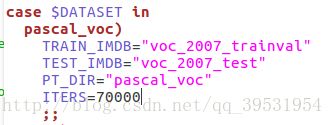 在ITERS中修改成自己想要的参数
在ITERS中修改成自己想要的参数
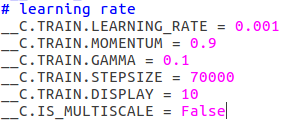
然后,我们进入lib/fast_rcnn/config.py,对config.py进行修改:
其中,第一项,就是学习率,STEPSIZE就是你对训练步长的修改,这里一定要小于等于前面训练文件的ITERS参数。其他大家可以选择保持一致,对于动量和伽马参数不用修改,当然,对于训练每隔多少次显示,大家根据自己情况修改,这里是10次一显示。
除此,我们可以修改batch的大小,
第一个参数是每次输入faster-rcnn网络中图片数量,第二个参数就是训练batch的大小。
还有关于模型保存问题:
这里,第一个参数是训练时,每迭代多少次保存一次模型;第二个参数是保存时模型的名字。
另外,大家要在训练的时候,可以将rpn检测目标设置为True,这个根据自己情况了
大家需要注意一点,就是修改py文件前,大家把它对应的pyc文件删掉,修改后再重新编译一下。上面的步骤都需要重新编译一下。
(6)接下来就可以输入训练命令了
进入你的Faster-rcnn文件夹,然后直接输入
./experiments/scripts/faster_rcnn_end2end.sh %DEVICE %DEVOCE_ID VGG16 pascal_voc
这里的%DEVICE 是你使用cpu还是gpu,当然,我是使用的gpu。%DEVICE_ID是你输入gpu的编号。
另外,可能会遇到文件夹权限低的问题,这里我有个提升文件夹权限的操作。
进入root权限,然后输入提升文件夹权限的命令
这样的话,你就可以使用训练命令了,当然,大家如果想了解这个指令的解释,可以直接去百度查。
第一次写博客,可能大家训练时还会有问题,可以留言,大家一起讨论。测试篇还在写,所以日后会更新。