深入剖析Spring(四):IOC核心思想(源码分析篇)
Spring框架能发展至今并成为最主流的框架必然有它的道理,对于我们学习者来说理应尽量的去汲取前辈们知识,我们不能被现今便捷的框架遮蔽了自己的双眼也许你离开了这些框架你可能什么都不是,因为我们已经是站在了巨人的肩膀上。
文章目录
- 一、 前言
- 二、IOC(Inversion of Control)
- 2.1 BeanFactory
- 2.2 BeanDefinition
- 2.3 BeanDefinitionReader
- 三、IOC初始化流程
- 四、基于配置文件的IOC容器初始化
- 4.1定位文件
- 4.2 获得文件路径
- 4.3启动
- 4.4创建容器
- 4.5载入配置路径
- 4.6分配路径处理策略
- 4.7解析配置文件路径
- 4.8读取文件配置
- 4.9准备文档对象
- 4.1.10分配解析策略
- 4.1.11将配置载入内存
- 4.1.12 载入
元素 - 4.1.13载入
元素 - 4.1.14载入
的子元素 - 4.1.15载入
- 的子元素
- 4.1.16 分配注册策略
- 4.1.17 向容器中注册
- 五、基于注解的IOC容器初始化
- 5.1定位Bean的扫描路径
- 5.2读取Annotation元数据
- 5.2.1 AnnotationConfigApplicationContext通过调用注解Bean定义读取器
- 5.2.2AnnotationScopeMetadataResolver解析作用域元数据
- 5.2.3AnnotationConfigUtils处理注解Bean定义类中的通用注解
- 5.2.4AnnotationConfigUtils根据注解Bean定义类中配置的作用域为其应用相应的代理策略
- 5.2.5 BeanDefinitionReaderUtils向容器注册Bean
- 5.3扫描指定包并解析为BeanDefinition
- 5.3.1ClassPathBeanDefinitionScanner扫描给定的包及其子包
- 5.3.2 ClassPathScanningCandidateComponentProvider扫描给定包及其子包的类
- 5.4 注册注解BeanDefinition
一、 前言
记录本系列的文章主要目的是为了自己的学习梳理,同时也希望各位业界的前辈们能够帮忙指点迷津。
本篇内容主要是理解一下IOC运行流程以及源码。
二、IOC(Inversion of Control)
控制反转:所谓控制反转就是将我们代码中需要实现的对象创建、依赖的代码,反转给容器来帮忙实现。要完成此操作必然需要一个容器,同时需要某种描述来让容器知道需要创建的对象与对象的关系,这个描述具体的体现就是 配 置 文 件 \color{#FF0000}{配置文件} 配置文件
既然说到了配置文件那我们来思考几个问题:
1.如何描述对象和对象的关系?
----> 我们从xml、properties、yml等语义话配置文件都可以表示?
2.文件存放在哪?
----> 可以存在classpath、filesystem、servletContext也可以是网络资源。
3.配置文件不同,我们如何统一解析?
----> 我们首先需要定义一个统一的对象定义,所有资源都需要转换成改定义格式。
2.1 BeanFactory
SpirngBean的创建是典型工厂模式,一系列的工厂模式,为IOC容器的开发和管理提供了许多便捷的基础服务,我们先来看看BeanFactory的类图看一看他们之间的关系,如下:
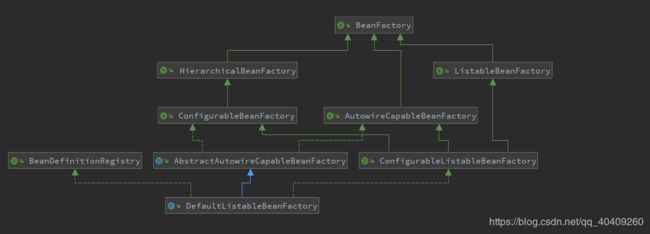
我们可以看到BeanFactory作为顶层的接口类,它的里面定义很多IOC容器的基本规范,它有三个重要的子类,AutowireCapableBeanFactory、HierarchicalBeanFactory 、ListableBeanFactory并且它们最终的实现类都是DefaultListableBeanFactory,他实现了所有的接口。
那为何要定义这么多的接口?
个人的理解是单一职责原则,每个接口都有他自己的使用场合,为了区分在Spring内部操作过程中对象的传递和转化的过程。说白了就是方便管理和维护。
比如说:ListableBeanFactory表示这些Bean是可序列化的,HierarchicalBeanFactory 表示这些Bean是有继承关系的,每个Bean也可能会有父类Bean。AutowireCapableBeanFactory 表示这些Bean的自动装配规则。这三个接口共用定义组成了Bean的集合、Bean之间的关系、以及Bean的行为。
我们来看看BeanFactory的源码:
public interface BeanFactory {
//转义标识符,如果需要得到工厂本身,需要转义
String FACTORY_BEAN_PREFIX = "&";
//根据bean的名字,获取在IOC容器中得到bean实例
Object getBean(String name) throws BeansException;
//根据bean的名字和Class类型来得到bean实例,增加了类型安全验证机制。
<T> T getBean(String name, @Nullable Class<T> requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
<T> T getBean(Class<T> requiredType) throws BeansException;
<T> T getBean(Class<T> requiredType, Object... args) throws BeansException;
//提供对bean的检索,看看是否在IOC容器有这个名字的bean
boolean containsBean(String name);
//并同时判断这个bean是不是单例
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
//判断是不是原型
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
/**
*
* 根据beanName判断是否有指定类型的匹配
* @param name beanName
* @param typeToMatch 需要匹配的目标类型
* 例如:
* name="time", typeToMatch=Date.Class
* 如果time类型是Date类型返回true
*/
boolean isTypeMatch(String name, ResolvableType typeToMatch) throws NoSuchBeanDefinitionException;
//同上一样
boolean isTypeMatch(String name, @Nullable Class<?> typeToMatch) throws NoSuchBeanDefinitionException;
//得到bean实例的Class类型
@Nullable
Class<?> getType(String name) throws NoSuchBeanDefinitionException;
//得到bean的别名,如果根据别名检索,那么其原名也会被检索出来
String[] getAliases(String name);
}
在BeanFactory中对IOC做了基本的行为定义,根本不关心你的Bean是如何定义和加载的。
而我们需要知道工厂是如何生产对象的,就需要看IOC的具体实现类,Spring也提供了许多IOC容器的实现,例如:GenericApplicationContext 、ClasspathXmlApplicationContext ,但是我们最常用的还是ApplicationContext,为什么呢?
ApplicationContext是spring提供的一个比较高级点的IOC容器,它除了能够提供IOC的基本功能外,还为用户提供了许多额外的功能扩展:
1、支持信息源,可以实现国际化。(实现MessageSource接口)
2、访问资源。(实现ResourcePatternResolver接口)
3、支持应用事件。(实现ApplicationEventPublisher接口)
这三点目前小编都还没有系统的接触到,先给大家看看,希望大佬能够提供一下资源( - -!),在此感谢
2.2 BeanDefinition
SpirngIOC管理了我们定义的各种Bean对象以及它们之间的相互关系,Bean对象在spring中是以BeanDefinition来描述的,在Spring容器启动的过程中,会将Bean解析成BeanDefinition结构,我们先来看看它的类图,如下:
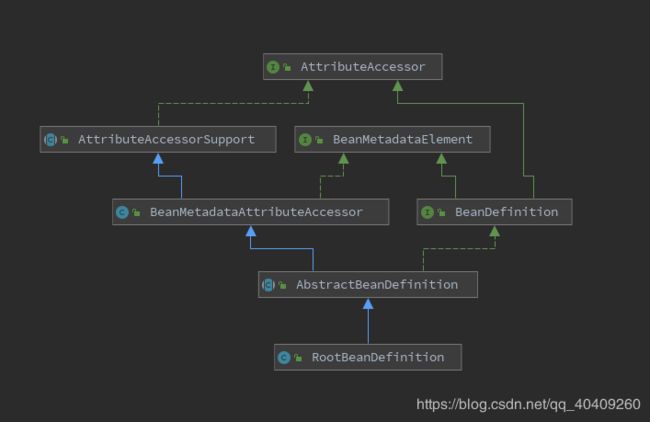
在这我解析一下BeanDefinition接口定义的属性,在接口内部定义了非常多的属性和方法,类名、scope、属性、构造函数参数列表、依赖的bean、是否是单例类、是否是懒加载之类的,本质就是将Bean封装到BeanDefinition中在后续操作中就是对BeanDefinition操作,可以根据里面的类名、构造函数、构造函数参数,使用反射进行对象创建。
2.3 BeanDefinitionReader
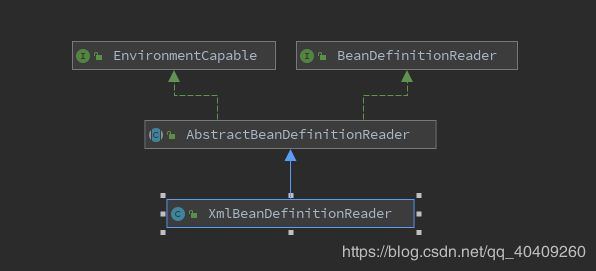
Bean的解析过程实际上还是比较复杂的,功能划分粒度很细,因为这个地方需要被扩展的地方很多,所以必须保证有足够的灵活性来面对不同的变化,Bean的解析本质上就是对Spring配置文件的解析。这个解析的过程通过BeanDefinitionReader来完成,我们来看看类图:
三、IOC初始化流程
在上一篇文章MVC介绍的DispatcherServlet类中,我们所有的初始化工作都是放在init()中完成,那么这个init()方法是谁的方法呢?往上追寻HttpServletBean类中找到了我们的答案:
public final void init() throws ServletException {
if (logger.isDebugEnabled()) {
logger.debug("Initializing servlet '" + getServletName() + "'");
}
// Set bean properties from init parameters.
PropertyValues pvs = new ServletConfigPropertyValues(getServletConfig(), this.requiredProperties);
if (!pvs.isEmpty()) {
try {
//定位资源
BeanWrapper bw = PropertyAccessorFactory.forBeanPropertyAccess(this);
//加载配置信息
ResourceLoader resourceLoader = new ServletContextResourceLoader(getServletContext());
bw.registerCustomEditor(Resource.class, new ResourceEditor(resourceLoader, getEnvironment()));
initBeanWrapper(bw);
bw.setPropertyValues(pvs, true);
}
catch (BeansException ex) {
if (logger.isErrorEnabled()) {
logger.error("Failed to set bean properties on servlet '" + getServletName() + "'", ex);
}
throw ex;
}
}
// 真正执行初始化逻辑的入口
initServletBean();
if (logger.isDebugEnabled()) {
logger.debug("Servlet '" + getServletName() + "' configured successfully");
}
}
我们发现了initServletBean()方法,在init()方法中,真正完成初始化容器动作的逻辑其实在initServletBean()方法中,我们追寻此方法,在FrameworkServlet中完成了对该方法的实现,请看源码:
protected final void initServletBean() throws ServletException {
getServletContext().log("Initializing Spring FrameworkServlet '" + getServletName() + "'");
if (this.logger.isInfoEnabled()) {
this.logger.info("FrameworkServlet '" + getServletName() + "': initialization started");
}
long startTime = System.currentTimeMillis();
try {
this.webApplicationContext = initWebApplicationContext();
initFrameworkServlet();
}
catch (ServletException ex) {
this.logger.error("Context initialization failed", ex);
throw ex;
}
catch (RuntimeException ex) {
this.logger.error("Context initialization failed", ex);
throw ex;
}
if (this.logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
this.logger.info("FrameworkServlet '" + getServletName() + "': initialization completed in " +
elapsedTime + " ms");
}
}
在此方法并没有过于复杂的逻辑,就不做啥解释了,我们发现有initWebAppplicationContext(),是不是有点熟悉的感觉?继续跟进
protected WebApplicationContext initWebApplicationContext() {
//先从ServletContext中获得父容器WebAppliationContext
WebApplicationContext rootContext =
WebApplicationContextUtils.getWebApplicationContext(getServletContext());
//声明子容器
WebApplicationContext wac = null;
//建立父、子容器之间的关联关系
if (this.webApplicationContext != null) {
// A context instance was injected at construction time -> use it
wac = this.webApplicationContext;
if (wac instanceof ConfigurableWebApplicationContext) {
ConfigurableWebApplicationContext cwac = (ConfigurableWebApplicationContext) wac;
if (!cwac.isActive()) {
// The context has not yet been refreshed -> provide services such as
// setting the parent context, setting the application context id, etc
if (cwac.getParent() == null) {
// The context instance was injected without an explicit parent -> set
// the root application context (if any; may be null) as the parent
cwac.setParent(rootContext);
}
//这个方法里面调用了AbatractApplication的refresh()方法
//refresh()方法是真正的IOC初始化的入口
//模板方法,规定IOC初始化基本流程
configureAndRefreshWebApplicationContext(cwac);
}
}
}
//先去ServletContext中查找Web容器的引用是否存在,并创建好默认的空IOC容器
if (wac == null) {
// No context instance was injected at construction time -> see if one
// has been registered in the servlet context. If one exists, it is assumed
// that the parent context (if any) has already been set and that the
// user has performed any initialization such as setting the context id
wac = findWebApplicationContext();
}
//给上一步创建好的IOC容器赋值
if (wac == null) {
// No context instance is defined for this servlet -> create a local one
wac = createWebApplicationContext(rootContext);
}
//触发onRefresh方法
if (!this.refreshEventReceived) {
// Either the context is not a ConfigurableApplicationContext with refresh
// support or the context injected at construction time had already been
// refreshed -> trigger initial onRefresh manually here.
onRefresh(wac);
}
if (this.publishContext) {
// Publish the context as a servlet context attribute.
String attrName = getServletContextAttributeName();
getServletContext().setAttribute(attrName, wac);
if (this.logger.isDebugEnabled()) {
this.logger.debug("Published WebApplicationContext of servlet '" + getServletName() +
"' as ServletContext attribute with name [" + attrName + "]");
}
}
return wac;
}
找到重点方法configureAndRefreshWebApplicationContext()跟进
protected void configureAndRefreshWebApplicationContext(ConfigurableWebApplicationContext wac) {
if (ObjectUtils.identityToString(wac).equals(wac.getId())) {
// The application context id is still set to its original default value
// -> assign a more useful id based on available information
if (this.contextId != null) {
wac.setId(this.contextId);
}
else {
// Generate default id...
wac.setId(ConfigurableWebApplicationContext.APPLICATION_CONTEXT_ID_PREFIX +
ObjectUtils.getDisplayString(getServletContext().getContextPath()) + '/' + getServletName());
}
}
wac.setServletContext(getServletContext());
wac.setServletConfig(getServletConfig());
wac.setNamespace(getNamespace());
wac.addApplicationListener(new SourceFilteringListener(wac, new ContextRefreshListener()));
// The wac environment's #initPropertySources will be called in any case when the context
// is refreshed; do it eagerly here to ensure servlet property sources are in place for
// use in any post-processing or initialization that occurs below prior to #refresh
ConfigurableEnvironment env = wac.getEnvironment();
if (env instanceof ConfigurableWebEnvironment) {
((ConfigurableWebEnvironment) env).initPropertySources(getServletContext(), getServletConfig());
}
postProcessWebApplicationContext(wac);
applyInitializers(wac);
wac.refresh();
}
观察以上两处代码在initWebApplicationContext()方法中调用了configAndRefreshWebApplicationContext()方法,在此方法中调用了refresh()方法,这个是真正启动IOC 容器的入口,IOC 容器初始化以后,最后调用了DispatcherServlet的onRefresh()方法,在onRefresh()方法中又是直接调用initStrategies()方法初始化SpringMVC的九大组件:
@Override
protected void onRefresh(ApplicationContext context) {
initStrategies(context);
}
/**
* Initialize the strategy objects that this servlet uses.
* May be overridden in subclasses in order to initialize further strategy objects.
*/
//初始化策略
protected void initStrategies(ApplicationContext context) {
//多文件上传的组件
initMultipartResolver(context);
//初始化本地语言环境
initLocaleResolver(context);
//初始化模板处理器
initThemeResolver(context);
//handlerMapping
initHandlerMappings(context);
//初始化参数适配器
initHandlerAdapters(context);
//初始化异常拦截器
initHandlerExceptionResolvers(context);
//初始化视图预处理器
initRequestToViewNameTranslator(context);
//初始化视图转换器
initViewResolvers(context);
//
initFlashMapManager(context);
}
四、基于配置文件的IOC容器初始化
4.1定位文件
IOC 容器的初始化包括BeanDefinition的Resource定位、加载和注册这三个基本的过程,在上文介绍了spring提供了很多IOC容器实现,我们就以ApplicationContext为例,因为我们最熟悉它使用的也最多,因为在web项目中使用的XmlWebApplicationContext以及ClasspathXmlApplicationContext
就来自这个体系。
ApplicationContext允许上下文嵌套,通过保持父上下文可以维持一个上下文体系。对于Bean的查找
可以在这个上下文体系中发生,首先检查当前上下文,其次是父上下文,逐级向上,这样为不同的Spring应用提供了一个共享的Bean定义环境。
ApplicationContext app = new ClassPathXmlApplicationContext("application.xml");
不知大家对此方法是否还有映像,在我们最初学习spring的时候就是通过此方法指定配置文件,然后来测试各种Bean的注入啊什么的。我们这里也从此深入。
查看其构造函数的调用
public ClassPathXmlApplicationContext(String configLocation) throws BeansException {
this(new String[] {configLocation}, true, null);
}
查看此重载方法
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
setConfigLocations(configLocations);
if (refresh) {
refresh();
}
}
也就是说实际上了是调用了此方法。
其实不光ClassPathXmlApplicationContext像还有 AnnotationConfigApplicationContext 、 FileSystemXmlApplicationContext 、XmlWebApplicationContext等都继承自父容器AbstractApplicationContext主要用到了装饰器模式和策略模式,最终都是调用refresh()方法。
4.2 获得文件路径
通 过分析ClassPathXmlApplicationContext的源代码可以知道 ,在创建
ClassPathXmlApplicationContext容器时,构造方法做以下两项重要工作:首先,调用父类容器的构造方法(super(parent)方法)为容器设置好Bean资源加载器。然后,再调用父类AbstractRefreshableConfigApplicationContext的setConfigLocations(configLocations)方法设置Bean配置信息的定位路径。通过追踪ClassPathXmlApplicationContext的继承体系 , 发现其父类的 类AbstractApplicationContext中初始化IOC容器所做的主要部分源码如下:
public abstract class AbstractApplicationContext extends DefaultResourceLoader
implements ConfigurableApplicationContext {
//静态初始化块,在整个容器创建过程中只执行一次
static {
//为了避免应用程序在Weblogic8.1关闭时出现类加载异常加载问题,加载IoC容
//器关闭事件(ContextClosedEvent)类
ContextClosedEvent.class.getName();
}
public AbstractApplicationContext() { this.resourcePatternResolver = getResourcePatternResolver(); }
public AbstractApplicationContext(@Nullable ApplicationContext parent) { this(); setParent(parent); }
//获取一个 Spring Source 的加载器用于读入 Spring Bean 配置信息
protected ResourcePatternResolver getResourcePatternResolver() { //AbstractApplicationContext 继承 DefaultResourceLoader,因此也是一个资源加载器 //Spring 资源加载器,其 getResource(String location)方法用于载入资源
return new PathMatchingResourcePatternResolver(this); }
/**省略以下代码*/
}
AbstractApplicationContext 的默认构造方法中有调用 PathMatchingResourcePatternResolver 的
构造方法创建Spring资源加载器:
public PathMatchingResourcePatternResolver(ResourceLoader resourceLoader) {
Assert.notNull(resourceLoader, "ResourceLoader must not be null");
//设置Spring的资源加载器
this.resourceLoader = resourceLoader;
}
在设置容器的资源加载器之后,接下来回到 ClassPathXmlApplicationContext构造方法中继续 执行setConfigLocations()方法通过调用其父类AbstractRefreshableConfigApplicationContext的方法进行对Bean配置信息的定位,该方法的源码如下:
//解析Bean定义资源文件的路径,处理多个资源文件字符串数组
public void setConfigLocations(@Nullable String... locations) {
if (locations != null) {
Assert.noNullElements(locations, "Config locations must not be null");
this.configLocations = new String[locations.length];
for (int i = 0; i < locations.length; i++) {
// resolvePath为同一个类中将字符串解析为路径的方法
this.configLocations[i] = resolvePath(locations[i]).trim();
}
}
else {
this.configLocations = null;
}
}
从这里我们可以知道我们可以使用字符串来配置多个SpringBean的配置信息,也可以使用字符串数组
即:
ClassPathResource res = new ClassPathResource("a.xml,b.xml");
ClassPathResource res =new ClassPathResource(new String[]{"a.xml","b.xml"});
至此,SpringIOC 容器在初始化时将配置的Bean配置信息定位为Spring封装的Resource完成。
4.3启动
上文提到过IOC的容器初始化真正的逻辑是在refresh() 中,而该又是实际上又是一个模板方法,只是规定了IOC启动的流程,具体的逻辑还是由其子类来实现的。它对 Bean 配置资源进行载入
ClassPathXmlApplicationContext 通过调用其父类 AbstractApplicationContext 的 refresh()函数启
动整个IOC 容器对Bean定义的载入过程,现在我们来详细看看refresh()中的逻辑处理:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//1、调用容器准备刷新的方法,获取容器的当时时间,同时给容器设置同步标识
prepareRefresh();
//2、告诉子类启动refreshBeanFactory()方法,Bean定义资源文件的载入从
//子类的refreshBeanFactory()方法启动
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//3、为BeanFactory配置容器特性,例如类加载器、事件处理器等
prepareBeanFactory(beanFactory);
try {
//4、为容器的某些子类指定特殊的BeanPost事件处理器
postProcessBeanFactory(beanFactory);
//5、调用所有注册的BeanFactoryPostProcessor的Bean
invokeBeanFactoryPostProcessors(beanFactory);
//6、为BeanFactory注册BeanPost事件处理器.
//BeanPostProcessor是Bean后置处理器,用于监听容器触发的事件
registerBeanPostProcessors(beanFactory);
//7、初始化信息源,和国际化相关.
initMessageSource();
//8、初始化容器事件传播器.
initApplicationEventMulticaster();
//9、调用子类的某些特殊Bean初始化方法
onRefresh();
//10、为事件传播器注册事件监听器.
registerListeners();
//11、初始化所有剩余的单例Bean
finishBeanFactoryInitialization(beanFactory);
//12、初始化容器的生命周期事件处理器,并发布容器的生命周期事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
//13、销毁已创建的Bean
destroyBeans();
//14、取消refresh操作,重置容器的同步标识。
cancelRefresh(ex);
throw ex;
}
finally {
//15、重设公共缓存
resetCommonCaches();
}
}
}
refresh()方法主要为 IOC 容器 Bean 的生命周期管理提供条件,Spring IOC 容器载入 Bean 配置信息
从 其 子 类 容 器 的 refreshBeanFactory() 方 法 启 动 , 所 以 整 个 refresh() 中ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();从这以后代码的
都是注册容器的信息源和生命周期事件,我们前面说的载入就是从这句代码开始启动。
refresh()方法的主要作用是:
在创建 IOC 容器前,如果已经有容器存在,则需要把已有的容器销毁和关闭,以保证在refresh之后使用的是新建立起来的 IOC容器。它类似于对IOC 容器的重启,在新建立好的容器中对容器进行初始化,对Bean配置资源进行载入。
4.4创建容器
obtainFreshBeanFactory()方法调用子类容器的 refreshBeanFactory()方法,启动容器载入Bean配置
信息的过程,代码如下:
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
//这里使用了委派设计模式,父类定义了抽象的refreshBeanFactory()方法,具体实现调用子类容器的refreshBeanFactory()方法
refreshBeanFactory();
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
AbstractApplicationContext 类中只抽象定义了 refreshBeanFactory()方法,容器真正调用的是 其子类 AbstractRefreshableApplicationContext 实现的 refreshBeanFactory()方法,方法的源 码如下:
protected final void refreshBeanFactory() throws BeansException {
//如果已经有容器,销毁容器中的bean,关闭容器
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//创建IOC容器
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
//对IOC容器进行定制化,如设置启动参数,开启注解的自动装配等
customizeBeanFactory(beanFactory);
//调用载入Bean定义的方法,主要这里又使用了一个委派模式,在当前类中只定义了抽象的loadBeanDefinitions方法,具体的实现调用子类容器
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
在这个方法中,先判断 BeanFactory 是否存在,如果存在则先销毁 beans并关闭beanFactory,接着
创建DefaultListableBeanFactory,并调用loadBeanDefinitions(beanFactory)装载bean定义。
4.5载入配置路径
上面类中AbstractRefreshableApplicationContext 中定义了抽象方法loadBeanDefinitions ,容器真正调用的是其子类 AbstractXmlApplicationContext 对该方法的实现,AbstractXmlApplicationContext
的主要源码如下:
protected abstract void loadBeanDefinitions(DefaultListableBeanFactory beanFactory)
throws BeansException, IOException;
loadBeanDefinitions() 方 法 同 样 是 抽 象 方 法 , 是 由 其 子 类 实 现 的 , 也 即 在
AbstractXmlApplicationContext中。
//实现父类抽象的载入Bean定义方法
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//创建XmlBeanDefinitionReader,即创建Bean读取器,并通过回调设置到容器中去,容 器使用该读取器读取Bean定义资源
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
//为Bean读取器设置Spring资源加载器,AbstractXmlApplicationContext的
//祖先父类AbstractApplicationContext继承DefaultResourceLoader,因此,容器本身也是一个资源加载器
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
//为Bean读取器设置SAX xml解析器
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
//当Bean读取器读取Bean定义的Xml资源文件时,启用Xml的校验机制
initBeanDefinitionReader(beanDefinitionReader);
//Bean读取器真正实现加载的方法
loadBeanDefinitions(beanDefinitionReader);
}
注意最后一行的调用
//Xml Bean读取器加载Bean定义资源
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
//获取Bean定义资源的定位
Resource[] configResources = getConfigResources();
if (configResources != null) {
//Xml Bean读取器调用其父类AbstractBeanDefinitionReader读取定位
//的Bean定义资源
reader.loadBeanDefinitions(configResources);
}
//如果子类中获取的Bean定义资源定位为空,则获取FileSystemXmlApplicationContext构造方法中setConfigLocations方法设置的资源
String[] configLocations = getConfigLocations();
if (configLocations != null) {
//Xml Bean读取器调用其父类AbstractBeanDefinitionReader读取定位
//的Bean定义资源
reader.loadBeanDefinitions(configLocations);
}
}
查看上方法中的getConfigResources()方法
//这里又使用了一个委托模式,调用子类的获取Bean定义资源定位的方法
//该方法在ClassPathXmlApplicationContext中进行实现
@Nullable
protected Resource[] getConfigResources() {
return null;
}
4.6分配路径处理策略
在XmlBeanDefinitionReader的抽象父类AbstractBeanDefinitionReader中定义了载入过程,loadBeanDefinitions()方法源码如下:
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
//获取在IoC容器初始化过程中设置的资源加载器
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
//将指定位置的Bean定义资源文件解析为Spring IOC容器封装的资源
//加载多个指定位置的Bean定义资源文件
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
//委派调用其子类XmlBeanDefinitionReader的方法,实现加载功能
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
//将指定位置的Bean定义资源文件解析为Spring IOC容器封装的资源
//加载单个指定位置的Bean定义资源文件
Resource resource = resourceLoader.getResource(location);
//委派调用其子类XmlBeanDefinitionReader的方法,实现加载功能
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
return loadCount;
}
}
//重载方法,调用loadBeanDefinitions(String);
@Override
public int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException {
Assert.notNull(locations, "Location array must not be null");
int counter = 0;
for (String location : locations) {
counter += loadBeanDefinitions(location);
}
return counter;
}
AbstractRefreshableConfigApplicationContext 的 loadBeanDefinitions(Resource…resources)方
法实际上是调用AbstractBeanDefinitionReader的loadBeanDefinitions()方法。
从对 AbstractBeanDefinitionReader 的 loadBeanDefinitions()方法源码分析可以看出该方法就做了
两件事:首先,调用资源加载器的获取资源方法resourceLoader.getResource(location),获取到要加载的资源。其次,真正执行加载功能是其子类 XmlBeanDefinitionReader 的 loadBeanDefinitions()方法。在loadBeanDefinitions()方法中调用了 AbstractApplicationContext的 getResources()方法,跟进去之后发现 getResources()方法其实定义在 ResourcePatternResolver 中,此时,我们有必要来看一下ResourcePatternResolver的全类图:
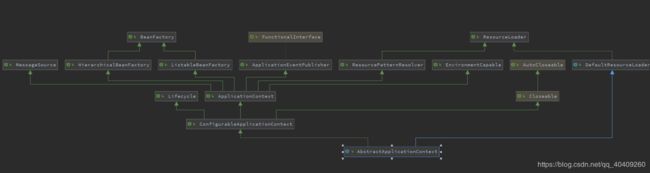
从上面可以看到 ResourceLoader 与 ApplicationContext 的继承关系,可以看出其实际调用的是DefaultResourceLoader中的getSource()方法定位 Resource ,因为ClassPathXmlApplicationContext 本身就是 DefaultResourceLoader 的实现类,所以此时又回到了ClassPathXmlApplicationContext中来
4.7解析配置文件路径
XmlBeanDefinitionReader通过调用ClassPathXmlApplicationContext 的父类DefaultResourceLoader的getResource()方法获取要加载的资源,其源码如下:
//获取Resource的具体实现方法
@Override
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
for (ProtocolResolver protocolResolver : this.protocolResolvers) {
Resource resource = protocolResolver.resolve(location, this);
if (resource != null) {
return resource;
}
}
//如果是类路径的方式,那需要使用ClassPathResource 来得到bean 文件的资源对象
if (location.startsWith("/")) {
return getResourceByPath(location);
}
else if (location.startsWith(CLASSPATH_URL_PREFIX)) {
return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
}
else {
try {
// 如果是URL方式,使用UrlResource 作为bean 文件的资源对象
URL url = new URL(location);
return (ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url));
}
catch (MalformedURLException ex) {
//如果既不是classpath标识,又不是URL标识的Resource定位,则调用
//容器本身的getResourceByPath方法获取Resource
return getResourceByPath(location);
}
}
}
DefaultResourceLoader 提供了 getResourceByPath()方法的实现,就是为了处理既不是 classpath
标识,又不是URL标识的Resource定位这种情况。
在 ClassPathResource中完成了对整个路径的解析。这样,就可以从类路径上对 IOC 配置文件进行加
载,当然我们可以按照这个逻辑从任何地方加载,在 Spring中我们看到它提供的各种资源抽象,比如
ClassPathResource、URLResource、FileSystemResource等来供我们使用。上面我们看到的是定位
Resource 的一个过程,而这只是加载过程的一部分。例如 FileSystemXmlApplication 容器就重写了
getResourceByPath()方法:
@Override protected Resource getResourceByPath(String path) {
if (path.startsWith("/")) { path = path.substring(1); }
//这里使用文件系统资源对象来定义 bean 文件
return new FileSystemResource(path); }
4.8读取文件配置
继续回到 XmlBeanDefinitionReader 的 loadBeanDefinitions(Resource resource)方法看到代表 bean 文件的资源定义以后的载入过程。
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
//将读入的XML资源进行特殊编码处理
return loadBeanDefinitions(new EncodedResource(resource));
}
//这里是载入XML形式Bean定义资源文件方法
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
//将资源文件转为InputStream的IO流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
//从InputStream中得到XML的解析源
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//这里是具体的读取过程
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
//关闭从Resource中得到的IO流
inputStream.close();
}
}
}
通过源码分析,载入 Bean配置信息的最后一步是将Bean配置信息转换为Document对象,该过程由
documentLoader()方法实现。
//从特定XML文件中实际载入Bean定义资源的方法
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//将XML文件转换为DOM对象,解析过程由documentLoader实现
Document doc = doLoadDocument(inputSource, resource);
//这里是启动对Bean定义解析的详细过程,该解析过程会用到Spring的Bean配置规则
return registerBeanDefinitions(doc, resource);
}
4.9准备文档对象
DocumentLoader将Bean配置资源转换成Document对象的源码如下:
//使用标准的JAXP将载入的Bean定义资源转换成document对象
@Override
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
//创建文件解析器工厂
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
//创建文档解析器
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
//解析Spring的Bean定义资源
return builder.parse(inputSource);
}
protected DocumentBuilderFactory createDocumentBuilderFactory(int validationMode, boolean namespaceAware)
throws ParserConfigurationException {
//创建文档解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(namespaceAware);
//设置解析XML的校验
if (validationMode != XmlValidationModeDetector.VALIDATION_NONE) {
factory.setValidating(true);
if (validationMode == XmlValidationModeDetector.VALIDATION_XSD) {
// Enforce namespace aware for XSD...
factory.setNamespaceAware(true);
try {
factory.setAttribute(SCHEMA_LANGUAGE_ATTRIBUTE, XSD_SCHEMA_LANGUAGE);
}
catch (IllegalArgumentException ex) {
ParserConfigurationException pcex = new ParserConfigurationException(
"Unable to validate using XSD: Your JAXP provider [" + factory +
"] does not support XML Schema. Are you running on Java 1.4 with Apache Crimson? " +
"Upgrade to Apache Xerces (or Java 1.5) for full XSD support.");
pcex.initCause(ex);
throw pcex;
}
}
}
return factory;
}
上面的解析过程是调用 JavaEE 标准的 JAXP 标准进行处理。至此 SpringIOC 容器根据定位的 Bean 配 置信息,将其加载读入并转换成为 Document 对象过程完成。接下来我们要继续分析 Spring IOC 容器 将载入的 Bean 配置信息转换为 Document 对象之后,是如何将其解析为 SpringIOC 管理的 Bean 对象 并将其注册到容器中的。
4.1.10分配解析策略
XmlBeanDefinitionReader 类中的 doLoadBeanDefinition()方法是从特定 XML 文件中实际载入 Bean 配置资源的方法,该方法在载入 Bean 配置资源之后将其转换为 Document 对象,接下来调用 registerBeanDefinitions() 启 动 Spring IOC 容 器 对 Bean定义的解析过程 ,registerBeanDefinitions()方法源码如下:
//按照Spring的Bean语义要求将Bean定义资源解析并转换为容器内部数据结构
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//得到BeanDefinitionDocumentReader来对xml格式的BeanDefinition解析
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//获得容器中注册的Bean数量
int countBefore = getRegistry().getBeanDefinitionCount();
//解析过程入口,这里使用了委派模式,BeanDefinitionDocumentReader只是个接口,
//具体的解析实现过程有实现类DefaultBeanDefinitionDocumentReader完成
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//统计解析的Bean数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
Bean配置资源的载入解析分为以下两个过程:
首先,通过调用 XML解析器将 Bean 配置信息转换得到 Document对象,但是这些 Document对象
并没有按照Spring的Bean规则进行解析。这一步是载入的过程
其次,在完成通用的 XML解析之后,按照 Spring Bean 的定义规则对 Document 对象进行解析,其
解 析 过 程 是 在 接 口 BeanDefinitionDocumentReader 的 实 现 类
DefaultBeanDefinitionDocumentReader中实现。
4.1.11将配置载入内存
BeanDefinitionDocumentReader 接 口 通 过 registerBeanDefinitions() 方 法 调 用 其 实 现 类
DefaultBeanDefinitionDocumentReader对Document对象进行解析,解析的代码如下:
//根据Spring DTD对Bean的定义规则解析Bean定义Document对象
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
//获得XML描述符
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
//获得Document的根元素
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
//--------------------------------------------------
protected void doRegisterBeanDefinitions(Element root) {
// Any nested elements will cause recursion in this method. In
// order to propagate and preserve default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
//具体的解析过程由BeanDefinitionParserDelegate实现,
//BeanDefinitionParserDelegate中定义了Spring Bean定义XML文件的各种元素
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//在解析Bean定义之前,进行自定义的解析,增强解析过程的可扩展性
preProcessXml(root);
//从Document的根元素开始进行Bean定义的Document对象
parseBeanDefinitions(root, this.delegate);
//在解析Bean定义之后,进行自定义的解析,增加解析过程的可扩展性
postProcessXml(root);
this.delegate = parent;
}
//创建BeanDefinitionParserDelegate,用于完成真正的解析过程
protected BeanDefinitionParserDelegate createDelegate(
XmlReaderContext readerContext, Element root, @Nullable BeanDefinitionParserDelegate parentDelegate) {
BeanDefinitionParserDelegate delegate = new BeanDefinitionParserDelegate(readerContext);
//BeanDefinitionParserDelegate初始化Document根元素
delegate.initDefaults(root, parentDelegate);
return delegate;
}
/**
* Parse the elements at the root level in the document:
* "import", "alias", "bean".
* @param root the DOM root element of the document
*/
//使用Spring的Bean规则从Document的根元素开始进行Bean定义的Document对象
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//Bean定义的Document对象使用了Spring默认的XML命名空间
if (delegate.isDefaultNamespace(root)) {
//获取Bean定义的Document对象根元素的所有子节点
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//获得Document节点是XML元素节点
if (node instanceof Element) {
Element ele = (Element) node;
//Bean定义的Document的元素节点使用的是Spring默认的XML命名空间
if (delegate.isDefaultNamespace(ele)) {
//使用Spring的Bean规则解析元素节点
parseDefaultElement(ele, delegate);
}
else {
//没有使用Spring默认的XML命名空间,则使用用户自定义的解//析规则解析元素节点
delegate.parseCustomElement(ele);
}
}
}
}
else {
//Document的根节点没有使用Spring默认的命名空间,则使用用户自定义的
//解析规则解析Document根节点
delegate.parseCustomElement(root);
}
}
//使用Spring的Bean规则解析Document元素节点
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//如果元素节点是导入元素,进行导入解析
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//如果元素节点是别名元素,进行别名解析
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//元素节点既不是导入元素,也不是别名元素,即普通的元素,
//按照Spring的Bean规则解析元素
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
/**
* Parse an "import" element and load the bean definitions
* from the given resource into the bean factory.
*/
//解析导入元素,从给定的导入路径加载Bean定义资源到Spring IoC容器中
protected void importBeanDefinitionResource(Element ele) {
//获取给定的导入元素的location属性
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
//如果导入元素的location属性值为空,则没有导入任何资源,直接返回
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
// Resolve system properties: e.g. "${user.dir}"
//使用系统变量值解析location属性值
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
Set<Resource> actualResources = new LinkedHashSet<>(4);
// Discover whether the location is an absolute or relative URI
//标识给定的导入元素的location是否是绝对路径
boolean absoluteLocation = false;
try {
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
catch (URISyntaxException ex) {
// cannot convert to an URI, considering the location relative
// unless it is the well-known Spring prefix "classpath*:"
//给定的导入元素的location不是绝对路径
}
// Absolute or relative?
//给定的导入元素的location是绝对路径
if (absoluteLocation) {
try {
//使用资源读入器加载给定路径的Bean定义资源
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");
}
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error(
"Failed to import bean definitions from URL location [" + location + "]", ele, ex);
}
}
else {
// No URL -> considering resource location as relative to the current file.
//给定的导入元素的location是相对路径
try {
int importCount;
//将给定导入元素的location封装为相对路径资源
Resource relativeResource = getReaderContext().getResource().createRelative(location);
//封装的相对路径资源存在
if (relativeResource.exists()) {
//使用资源读入器加载Bean定义资源
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
//封装的相对路径资源不存在
else {
//获取Spring IOC容器资源读入器的基本路径
String baseLocation = getReaderContext().getResource().getURL().toString();
//根据Spring IOC容器资源读入器的基本路径加载给定导入路径的资源
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");
}
}
catch (IOException ex) {
getReaderContext().error("Failed to resolve current resource location", ele, ex);
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",
ele, ex);
}
}
Resource[] actResArray = actualResources.toArray(new Resource[actualResources.size()]);
//在解析完元素之后,发送容器导入其他资源处理完成事件
getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}
/**
* Process the given alias element, registering the alias with the registry.
*/
//解析别名元素,为Bean向Spring IoC容器注册别名
protected void processAliasRegistration(Element ele) {
//获取别名元素中name的属性值
String name = ele.getAttribute(NAME_ATTRIBUTE);
//获取别名元素中alias的属性值
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
//别名元素的name属性值为空
if (!StringUtils.hasText(name)) {
getReaderContext().error("Name must not be empty", ele);
valid = false;
}
//别名元素的alias属性值为空
if (!StringUtils.hasText(alias)) {
getReaderContext().error("Alias must not be empty", ele);
valid = false;
}
if (valid) {
try {
//向容器的资源读入器注册别名
getReaderContext().getRegistry().registerAlias(name, alias);
}
catch (Exception ex) {
getReaderContext().error("Failed to register alias '" + alias +
"' for bean with name '" + name + "'", ele, ex);
}
//在解析完元素之后,发送容器别名处理完成事件
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
/**
* Process the given bean element, parsing the bean definition
* and registering it with the registry.
*/
//解析Bean定义资源Document对象的普通元素
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// BeanDefinitionHolder是对BeanDefinition的封装,即Bean定义的封装类
//对Document对象中元素的解析由BeanDefinitionParserDelegate实现
// BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
//向Spring IOC容器注册解析得到的Bean定义,这是Bean定义向IOC容器注册的入口
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
//在完成向Spring IOC容器注册解析得到的Bean定义之后,发送注册事件
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
通过上述 Spring IOC 容器对载入的 Bean 定义 Document 解析可以看出,我们使用 Spring 时,在
Spring配置文件中可以使用元素来导入 IOC 容器所需要的其他资源,Spring IOC 容器在解
析时会首先将指定导入的资源加载进容器中。使用别名时,SpringIOC 容器首先将别名元素所
定义的别名注册到容器中。
对于既不是元素,又不是元素的元素,即 Spring配置文件中普通的元素的
解析由BeanDefinitionParserDelegate 类的parseBeanDefinitionElement()方法来实现。这个解析的
过程非常复杂.其实对于xml的解析还是非常的复杂了。因此在上一篇文章中MVC使用中我们使用了properties文件代替了XML文件作为配置文件。望谅解。
4.1.12 载入元素
Bean 配置信息中的和元素解析在 DefaultBeanDefinitionDocumentReader 中已
经完成,对 Bean 配置信息中使用最多的元素交由 BeanDefinitionParserDelegate 来解析,
其解析实现的源码如下:
//解析元素的入口
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
/**
* Parses the supplied {@code } element. May return {@code null}
* if there were errors during parse. Errors are reported to the
* {@link org.springframework.beans.factory.parsing.ProblemReporter}.
*/
//解析Bean定义资源文件中的元素,这个方法中主要处理元素的id,name和别名属性
@Nullable
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
//获取元素中的id属性值
String id = ele.getAttribute(ID_ATTRIBUTE);
//获取元素中的name属性值
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//获取元素中的alias属性值
List<String> aliases = new ArrayList<>();
//将元素中的所有name属性值存放到别名中
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
//如果元素中没有配置id属性时,将别名中的第一个值赋值给beanName
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
//检查元素所配置的id或者name的唯一性,containingBean标识
//元素中是否包含子元素
if (containingBean == null) {
//检查元素所配置的id、name或者别名是否重复
checkNameUniqueness(beanName, aliases, ele);
}
//详细对元素中配置的Bean定义进行解析的地方
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
//如果元素中没有配置id、别名或者name,且没有包含子元素
//元素,为解析的Bean生成一个唯一beanName并注册
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
//如果元素中没有配置id、别名或者name,且包含了子元素
//元素,为解析的Bean使用别名向IOC容器注册
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
//为解析的Bean使用别名注册时,为了向后兼容
//Spring1.2/2.0,给别名添加类名后缀
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
//当解析出错时,返回null
return null;
}
只要使用过Spring,对Spring配置文件比较熟悉的人,通过对上述源码的分析,就会明白我们在Spring
配置文件中元素的中配置的属性就是通过该方法解析和设置到Bean中去的。
注意:在解析元素过程中没有创建和实例化 Bean 对象,只是创建了 Bean 对象的定义类
BeanDefinition,将元素中的配置信息设置到 BeanDefinition 中作为记录,当依赖注入时才
使用这些记录信息创建和实例化具体的Bean对象。上面方法中一些对一些配置如元信息(meta)、qualifier 等的解析,我们在Spring中配置时使用的也不多,我们在使用Spring的元素时,配置最多的是属性,因此我们下面继续分析源码,了解Bean的属性在解析时是如何设置的。
4.1.13载入元素
BeanDefinitionParserDelegate 在解析调用 parsePropertyElements()方法解析元
素中的属性子元素,解析源码如下:
//解析元素中的子元素
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {
//获取元素中所有的子元素
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//如果子元素是子元素,则调用解析子元素方法解析
if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {
parsePropertyElement((Element) node, bd);
}
}
}
//------------------------------------------
//解析元素
public void parsePropertyElement(Element ele, BeanDefinition bd) {
//获取元素的名字
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
if (!StringUtils.hasLength(propertyName)) {
error("Tag 'property' must have a 'name' attribute", ele);
return;
}
this.parseState.push(new PropertyEntry(propertyName));
try {
//如果一个Bean中已经有同名的property存在,则不进行解析,直接返回。
//即如果在同一个Bean中配置同名的property,则只有第一个起作用
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
//解析获取property的值
Object val = parsePropertyValue(ele, bd, propertyName);
//根据property的名字和值创建property实例
PropertyValue pv = new PropertyValue(propertyName, val);
//解析元素中的属性
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}
finally {
this.parseState.pop();
}
}
//--------------------------------
//解析获取property值
@Nullable
public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {
String elementName = (propertyName != null) ?
" element for property '" + propertyName + "'" :
" element" ;
// Should only have one child element: ref, value, list, etc.
//获取的所有子元素,只能是其中一种类型:ref,value,list,etc等
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//子元素不是description和meta属性
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// Child element is what we're looking for.
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
//当前元素包含有子元素
subElement = (Element) node;
}
}
}
//判断property的属性值是ref还是value,不允许既是ref又是value
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}
//如果属性是ref,创建一个ref的数据对象RuntimeBeanReference
//这个对象封装了ref信息
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
//一个指向运行时所依赖对象的引用
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
//设置这个ref的数据对象是被当前的property对象所引用
ref.setSource(extractSource(ele));
return ref;
}
//如果属性是value,创建一个value的数据对象TypedStringValue
//这个对象封装了value信息
else if (hasValueAttribute) {
//一个持有String类型值的对象
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
//设置这个value数据对象是被当前的property对象所引用
valueHolder.setSource(extractSource(ele));
return valueHolder;
}
//如果当前元素还有子元素
else if (subElement != null) {
//解析的子元素
return parsePropertySubElement(subElement, bd);
}
else {
// Neither child element nor "ref" or "value" attribute found.
//propery属性中既不是ref,也不是value属性,解析出错返回null
error(elementName + " must specify a ref or value", ele);
return null;
}
}
通过对上述源码的分析,我们可以了解在Spring配置文件中,元素中元素的相关
配置是如何处理的:
1、ref被封装为指向依赖对象一个引用。
2、value配置都会封装成一个字符串类型的对象。
3、ref和value都通过“解析的数据类型属性值.setSource(extractSource(ele));”方法将属性值/引用与所引用的属性关联起来。
在方法的最后对于元素的子元素通过 parsePropertySubElement ()方法解析,我们继续分析该方法的源码,了解其解析过程。
4.1.14载入的子元素
在 BeanDefinitionParserDelegate 类中的 parsePropertySubElement()方法对中的子元素解析,源码如下:
//解析元素中ref,value或者集合等子元素
@Nullable
public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd, @Nullable String defaultValueType) {
//如果没有使用Spring默认的命名空间,则使用用户自定义的规则解析内嵌元素
if (!isDefaultNamespace(ele)) {
return parseNestedCustomElement(ele, bd);
}
//如果子元素是bean,则使用解析元素的方法解析
else if (nodeNameEquals(ele, BEAN_ELEMENT)) {
BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);
if (nestedBd != null) {
nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);
}
return nestedBd;
}
//如果子元素是ref,ref中只能有以下3个属性:bean、local、parent
else if (nodeNameEquals(ele, REF_ELEMENT)) {
// A generic reference to any name of any bean.
//可以不再同一个Spring配置文件中,具体请参考Spring对ref的配置规则
String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);
boolean toParent = false;
if (!StringUtils.hasLength(refName)) {
// A reference to the id of another bean in a parent context.
//获取元素中parent属性值,引用父级容器中的Bean
refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);
toParent = true;
if (!StringUtils.hasLength(refName)) {
error("'bean' or 'parent' is required for element", ele);
return null;
}
}
if (!StringUtils.hasText(refName)) {
error(" element contains empty target attribute", ele);
return null;
}
//创建ref类型数据,指向被引用的对象
RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);
//设置引用类型值是被当前子元素所引用
ref.setSource(extractSource(ele));
return ref;
}
//如果子元素是,使用解析ref元素的方法解析
else if (nodeNameEquals(ele, IDREF_ELEMENT)) {
return parseIdRefElement(ele);
}
//如果子元素是,使用解析value元素的方法解析
else if (nodeNameEquals(ele, VALUE_ELEMENT)) {
return parseValueElement(ele, defaultValueType);
}
//如果子元素是null,为设置一个封装null值的字符串数据
else if (nodeNameEquals(ele, NULL_ELEMENT)) {
// It's a distinguished null value. Let's wrap it in a TypedStringValue
// object in order to preserve the source location.
TypedStringValue nullHolder = new TypedStringValue(null);
nullHolder.setSource(extractSource(ele));
return nullHolder;
}
//如果子元素是,使用解析array集合子元素的方法解析
else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {
return parseArrayElement(ele, bd);
}
//如果子元素是,使用解析list集合子元素的方法解析
else if (nodeNameEquals(ele, LIST_ELEMENT)) {
return parseListElement(ele, bd);
}
//如果子元素是,使用解析set集合子元素的方法解析
else if (nodeNameEquals(ele, SET_ELEMENT)) {
return parseSetElement(ele, bd);
}
//如果子元素是
else if (nodeNameEquals(ele, MAP_ELEMENT)) {
return parseMapElement(ele, bd);
}
//如果子元素是,使用解析props集合子元素的方法解析
else if (nodeNameEquals(ele, PROPS_ELEMENT)) {
return parsePropsElement(ele);
}
//既不是ref,又不是value,也不是集合,则子元素配置错误,返回null
else {
error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);
return null;
}
}
通过上述源码分析,我们明白了在Spring配置文件中,对元素中配置的array、list、set、map、prop 等各种集合子元素的都通过上述方法解析,生成对应的数据对象,比如 ManagedList、ManagedArray、ManagedSet 等,这些Managed类是 Spring对象BeanDefiniton的数据封装,对集合数据类型的具体解析有各自的解析方法实现,解析方法的命名非常规范,一目了然,我们对集合元素的解析方法进行源码分析,了解其实现过程。
4.1.15载入的子元素
在 BeanDefinitionParserDelegate 类中的 parseListElement()方法就是具体实现解析元素中的集合子元素,源码如下:
//解析集合子元素
public List<Object> parseListElement(Element collectionEle, @Nullable BeanDefinition bd) {
//获取元素中的value-type属性,即获取集合元素的数据类型
String defaultElementType = collectionEle.getAttribute(VALUE_TYPE_ATTRIBUTE);
//获取集合元素中的所有子节点
NodeList nl = collectionEle.getChildNodes();
//Spring中将List封装为ManagedList
ManagedList<Object> target = new ManagedList<>(nl.getLength());
target.setSource(extractSource(collectionEle));
//设置集合目标数据类型
target.setElementTypeName(defaultElementType);
target.setMergeEnabled(parseMergeAttribute(collectionEle));
//具体的元素解析
parseCollectionElements(nl, target, bd, defaultElementType);
return target;
}
//----------------------------------------------------
//具体解析集合元素,、和都使用该方法解析
protected void parseCollectionElements(
NodeList elementNodes, Collection<Object> target, @Nullable BeanDefinition bd, String defaultElementType) {
//遍历集合所有节点
for (int i = 0; i < elementNodes.getLength(); i++) {
Node node = elementNodes.item(i);
//节点不是description节点
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT)) {
//将解析的元素加入集合中,递归调用下一个子元素
target.add(parsePropertySubElement((Element) node, bd, defaultElementType));
}
}
}
对SpringBean配置信息转换的Document对象中的元素层层解析,SpringIOC现在已经将XML形式定义的Bean配置信息转换为SpringIOC所识别的数据结构——BeanDefinition,它是 Bean配置信息中配置的POJO对象在SpringIOC容器中的映射,我们可以通过AbstractBeanDefinition为入口,看到了IOC容器进行索引,查询和操作。通过 Spring IOC 容器对 Bean 配置资源的解析后,IOC 容器大致完成了管理 Bean 对象的准备工作,即初始化过程,但是最为重要的依赖注入还没有发生,现在在IOC 容器中 BeanDefinition存储的只是一些静态信息,接下来需要向容器注册Bean定义信息才能全部完成IOC 容器的初始化过程
4.1.16 分配注册策略
我们继续跟踪程序的执行顺序,接下来我们来分析DefaultBeanDefinitionDocumentReader对Bean定义转换的Document对象解析的流程中,在其parseDefaultElement()方法中完成对Document对象的解析后得到封装BeanDefinition的BeanDefinitionHold对象,然后调用BeanDefinitionReaderUtils的registerBeanDefinition()方法向IOC容器注册解析的 Bean,
BeanDefinitionReaderUtils的注册的源码如下:
//将解析的BeanDefinitionHold注册到容器中
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
//获取解析的BeanDefinition的名称
String beanName = definitionHolder.getBeanName();
//向IOC容器注册BeanDefinition
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
//如果解析的BeanDefinition有别名,向容器为其注册别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
当调用BeanDefinitionReaderUtils向 IOC 容器注册解析的BeanDefinition时,真正完成注册功能的是DefaultListableBeanFactory。
4.1.17 向容器中注册
DefaultListableBeanFactory 中使用一个 HashMap 的集合对象存放 IOC 容器中注册解析的
BeanDefinition,向IOC 容器注册的主要源码如下:
//存储注册信息的BeanDefinition
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
//向IOC容器注册解析的BeanDefiniton
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
//校验解析的BeanDefiniton
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
//注册的过程中需要线程同步,以保证数据的一致性
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
//检查是否有同名的BeanDefinition已经在IOC容器中注册
if (oldBeanDefinition != null || containsSingleton(beanName)) {
//重置所有已经注册过的BeanDefinition的缓存
resetBeanDefinition(beanName);
}
}
至此,Bean配置信息中配置的Bean被解析过后,已经注册到IOC 容器中,被容器管理起来,真正完成了 IOC 容器初始化所做的全部工作。现在 IOC 容器中已经建立了整个 Bean 的配置信息,这些BeanDefinition信息已经可以使用,并且可以被检索, IOC 容器的作用就是对这些注册的Bean定义信息进行处理和维护。这些的注册的 Bean定义信息是IOC 容器控制反转的基础,正是有了这些注册的数据,容器才可以进行依赖注入。
五、基于注解的IOC容器初始化
关于注解的IOC初始化相比较XML来说,在这也简单记录一下
5.1定位Bean的扫描路径
在 Spring 中管理注解 Bean 定义的容器有两个 :AnnotationConfigApplicationContext 和
AnnotationConfigWebApplicationContex。这两个类是专门处理Spring 注解方式配置的容器,直接依赖于注解作为容器配置信息来源的 IOC 容器。AnnotationConfigWebApplicationContext AnnotationConfigApplicationContext 的 Web版本,两者的用法以及对注解的处理方式几乎没有差别。现在我们以AnnotationConfigApplicationContext为例看看它的部分源码:
public class AnnotationConfigApplicationContext extends GenericApplicationContext implements AnnotationConfigRegistry {
//保存一个读取注解的Bean定义读取器,并将其设置到容器中
private final AnnotatedBeanDefinitionReader reader;
//保存一个扫描指定类路径中注解Bean定义的扫描器,并将其设置到容器中
private final ClassPathBeanDefinitionScanner scanner;
/**
* Create a new AnnotationConfigApplicationContext that needs to be populated
* through {@link #register} calls and then manually {@linkplain #refresh refreshed}.
*/
//默认构造函数,初始化一个空容器,容器不包含任何 Bean 信息,需要在稍后通过调用其register()
//方法注册配置类,并调用refresh()方法刷新容器,触发容器对注解Bean的载入、解析和注册过程
public AnnotationConfigApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
/**
* Create a new AnnotationConfigApplicationContext with the given DefaultListableBeanFactory.
* @param beanFactory the DefaultListableBeanFactory instance to use for this context
*/
public AnnotationConfigApplicationContext(DefaultListableBeanFactory beanFactory) {
super(beanFactory);
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
/**
* Create a new AnnotationConfigApplicationContext, deriving bean definitions
* from the given annotated classes and automatically refreshing the context.
* @param annotatedClasses one or more annotated classes,
* e.g. {@link Configuration @Configuration} classes
*/
//最常用的构造函数,通过将涉及到的配置类传递给该构造函数,以实现将相应配置类中的Bean自动注册到容器中
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
register(annotatedClasses);
refresh();
}
/**
* Create a new AnnotationConfigApplicationContext, scanning for bean definitions
* in the given packages and automatically refreshing the context.
* @param basePackages the packages to check for annotated classes
*/
//该构造函数会自动扫描以给定的包及其子包下的所有类,并自动识别所有的Spring Bean,将其注册到容器中
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
/**
* {@inheritDoc}
* Delegates given environment to underlying {@link AnnotatedBeanDefinitionReader}
* and {@link ClassPathBeanDefinitionScanner} members.
*/
@Override
public void setEnvironment(ConfigurableEnvironment environment) {
super.setEnvironment(environment);
this.reader.setEnvironment(environment);
this.scanner.setEnvironment(environment);
}
/**
* Provide a custom {@link BeanNameGenerator} for use with {@link AnnotatedBeanDefinitionReader}
* and/or {@link ClassPathBeanDefinitionScanner}, if any.
* Default is {@link org.springframework.context.annotation.AnnotationBeanNameGenerator}.
*
Any call to this method must occur prior to calls to {@link #register(Class...)}
* and/or {@link #scan(String...)}.
* @see AnnotatedBeanDefinitionReader#setBeanNameGenerator
* @see ClassPathBeanDefinitionScanner#setBeanNameGenerator
*/
//为容器的注解Bean读取器和注解Bean扫描器设置Bean名称产生器
public void setBeanNameGenerator(BeanNameGenerator beanNameGenerator) {
this.reader.setBeanNameGenerator(beanNameGenerator);
this.scanner.setBeanNameGenerator(beanNameGenerator);
getBeanFactory().registerSingleton(
AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR, beanNameGenerator);
}
/**
* Set the {@link ScopeMetadataResolver} to use for detected bean classes.
* The default is an {@link AnnotationScopeMetadataResolver}.
*
Any call to this method must occur prior to calls to {@link #register(Class...)}
* and/or {@link #scan(String...)}.
*/
//为容器的注解Bean读取器和注解Bean扫描器设置作用范围元信息解析器
public void setScopeMetadataResolver(ScopeMetadataResolver scopeMetadataResolver) {
this.reader.setScopeMetadataResolver(scopeMetadataResolver);
this.scanner.setScopeMetadataResolver(scopeMetadataResolver);
}
//---------------------------------------------------------------------
// Implementation of AnnotationConfigRegistry
//---------------------------------------------------------------------
/**
* Register one or more annotated classes to be processed.
* Note that {@link #refresh()} must be called in order for the context
* to fully process the new classes.
* @param annotatedClasses one or more annotated classes,
* e.g. {@link Configuration @Configuration} classes
* @see #scan(String...)
* @see #refresh()
*/
//为容器注册一个要被处理的注解Bean,新注册的Bean,必须手动调用容器的
//refresh()方法刷新容器,触发容器对新注册的Bean的处理
public void register(Class<?>... annotatedClasses) {
Assert.notEmpty(annotatedClasses, "At least one annotated class must be specified");
this.reader.register(annotatedClasses);
}
/**
* Perform a scan within the specified base packages.
* Note that {@link #refresh()} must be called in order for the context
* to fully process the new classes.
* @param basePackages the packages to check for annotated classes
* @see #register(Class...)
* @see #refresh()
*/
//扫描指定包路径及其子包下的注解类,为了使新添加的类被处理,必须手动调用
//refresh()方法刷新容器
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
this.scanner.scan(basePackages);
}
}
通过上面的源码分析,我们可以看啊到Spring对注解的处理分为两种方式:
1)、直接将注解Bean注册到容器中可以在初始化容器时注册;也可以在容器创建之后手动调用注册方法向容器注册,然后通过手动刷新容器,使得容器对注册的注解Bean进行处理。
2)、通过扫描指定的包及其子包下的所有类在初始化注解容器时指定要自动扫描的路径,如果容器创建以后向给定路径动态添加了注解Bean,则需要手动调用容器扫描的方法,然后手动刷新容器,使得容器对所注册的Bean进行处理。
接下来,将会对两种处理方式详细分析其实现过程。
5.2读取Annotation元数据
当创建注解处理容器时,如果传入的初始参数是具体的注解Bean定义类时,注解容器读取并注册
5.2.1 AnnotationConfigApplicationContext通过调用注解Bean定义读取器
AnnotatedBeanDefinitionReader的register()方法向容器注册指定的注解Bean,注解Bean定义读取器向容器注册注解Bean的源码如下:
//注册多个注解Bean定义类
public void register(Class<?>... annotatedClasses) {
for (Class<?> annotatedClass : annotatedClasses) {
registerBean(annotatedClass);
}
}
//注册一个注解Bean定义类
public void registerBean(Class<?> annotatedClass) {
doRegisterBean(annotatedClass, null, null, null);
}
//Bean定义读取器注册注解Bean定义的入口方法
@SuppressWarnings("unchecked")
public void registerBean(Class<?> annotatedClass, Class<? extends Annotation>... qualifiers) {
doRegisterBean(annotatedClass, null, null, qualifiers);
}
//Bean定义读取器向容器注册注解Bean定义类
@SuppressWarnings("unchecked")
public void registerBean(Class<?> annotatedClass, String name, Class<? extends Annotation>... qualifiers) {
doRegisterBean(annotatedClass, null, name, qualifiers);
}
//Bean定义读取器向容器注册注解Bean定义类
<T> void doRegisterBean(Class<T> annotatedClass, @Nullable Supplier<T> instanceSupplier, @Nullable String name,
@Nullable Class<? extends Annotation>[] qualifiers, BeanDefinitionCustomizer... definitionCustomizers) {
//根据指定的注解Bean定义类,创建Spring容器中对注解Bean的封装的数据结构
AnnotatedGenericBeanDefinition abd = new AnnotatedGenericBeanDefinition(annotatedClass);
if (this.conditionEvaluator.shouldSkip(abd.getMetadata())) {
return;
}
abd.setInstanceSupplier(instanceSupplier);
//解析注解Bean定义的作用域,若@Scope("prototype"),则Bean为原型类型;
//若@Scope("singleton"),则Bean为单态类型
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(abd);
//为注解Bean定义设置作用域
abd.setScope(scopeMetadata.getScopeName());
//为注解Bean定义生成Bean名称
String beanName = (name != null ? name : this.beanNameGenerator.generateBeanName(abd, this.registry));
//处理注解Bean定义中的通用注解
AnnotationConfigUtils.processCommonDefinitionAnnotations(abd);
//如果在向容器注册注解Bean定义时,使用了额外的限定符注解,则解析限定符注解。
//主要是配置的关于autowiring自动依赖注入装配的限定条件,即@Qualifier注解
//Spring自动依赖注入装配默认是按类型装配,如果使用@Qualifier则按名称
if (qualifiers != null) {
for (Class<? extends Annotation> qualifier : qualifiers) {
//如果配置了@Primary注解,设置该Bean为autowiring自动依赖注入装//配时的首选
if (Primary.class == qualifier) {
abd.setPrimary(true);
}
//如果配置了@Lazy注解,则设置该Bean为非延迟初始化,如果没有配置,
//则该Bean为预实例化
else if (Lazy.class == qualifier) {
abd.setLazyInit(true);
}
//如果使用了除@Primary和@Lazy以外的其他注解,则为该Bean添加一
//个autowiring自动依赖注入装配限定符,该Bean在进autowiring
//自动依赖注入装配时,根据名称装配限定符指定的Bean
else {
abd.addQualifier(new AutowireCandidateQualifier(qualifier));
}
}
}
for (BeanDefinitionCustomizer customizer : definitionCustomizers) {
customizer.customize(abd);
}
//创建一个指定Bean名称的Bean定义对象,封装注解Bean定义类数据
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(abd, beanName);
//根据注解Bean定义类中配置的作用域,创建相应的代理对象
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//向IOC容器注册注解Bean类定义对象
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, this.registry);
}
从上面的源码我们可以看出,注册注解Bean定义类的基本步骤:
a、需要使用注解元数据解析器解析注解Bean中关于作用域的配置。
b、使用 AnnotationConfigUtils 的 processCommonDefinitionAnnotations()方法处理注解 Bean 定义类中通用的注解。
c、使用AnnotationConfigUtils的applyScopedProxyMode()方法创建对于作用域的代理对象。
d、通过BeanDefinitionReaderUtils向容器注册Bean。
下面我们继续分析这4步的具体实现过程
5.2.2AnnotationScopeMetadataResolver解析作用域元数据
AnnotationScopeMetadataResolver 通过 resolveScopeMetadata()方法解析注解 Bean 定义类的作用域元信息,即判断注册的Bean是原生类型(prototype)还是单态(singleton)类型,其源码如下:
//解析注解Bean定义类中的作用域元信息
@Override
public ScopeMetadata resolveScopeMetadata(BeanDefinition definition) {
ScopeMetadata metadata = new ScopeMetadata();
if (definition instanceof AnnotatedBeanDefinition) {
AnnotatedBeanDefinition annDef = (AnnotatedBeanDefinition) definition;
//从注解Bean定义类的属性中查找属性为”Scope”的值,即@Scope注解的值
//annDef.getMetadata().getAnnotationAttributes()方法将Bean
//中所有的注解和注解的值存放在一个map集合中
AnnotationAttributes attributes = AnnotationConfigUtils.attributesFor(
annDef.getMetadata(), this.scopeAnnotationType);
//将获取到的@Scope注解的值设置到要返回的对象中
if (attributes != null) {
metadata.setScopeName(attributes.getString("value"));
//获取@Scope注解中的proxyMode属性值,在创建代理对象时会用到
ScopedProxyMode proxyMode = attributes.getEnum("proxyMode");
//如果@Scope的proxyMode属性为DEFAULT或者NO
if (proxyMode == ScopedProxyMode.DEFAULT) {
//设置proxyMode为NO
proxyMode = this.defaultProxyMode;
}
//为返回的元数据设置proxyMode
metadata.setScopedProxyMode(proxyMode);
}
}
//返回解析的作用域元信息对象
return metadata;
}
5.2.3AnnotationConfigUtils处理注解Bean定义类中的通用注解
AnnotationConfigUtils 类的 processCommonDefinitionAnnotations()在向容器注册 Bean 之前,首先对注解Bean定义类中的通用Spring 注解进行处理,源码如下:
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
//处理Bean定义中通用注解
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);
//如果Bean定义中有@Lazy注解,则将该Bean预实例化属性设置为@lazy注解的值
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
else if (abd.getMetadata() != metadata) {
lazy = attributesFor(abd.getMetadata(), Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
}
//如果Bean定义中有@Primary注解,则为该Bean设置为autowiring自动依赖注入装配的首选对象
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
//如果Bean定义中有@ DependsOn注解,则为该Bean设置所依赖的Bean名称,
//容器将确保在实例化该Bean之前首先实例化所依赖的Bean
AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);
if (dependsOn != null) {
abd.setDependsOn(dependsOn.getStringArray("value"));
}
if (abd instanceof AbstractBeanDefinition) {
AbstractBeanDefinition absBd = (AbstractBeanDefinition) abd;
AnnotationAttributes role = attributesFor(metadata, Role.class);
if (role != null) {
absBd.setRole(role.getNumber("value").intValue());
}
AnnotationAttributes description = attributesFor(metadata, Description.class);
if (description != null) {
absBd.setDescription(description.getString("value"));
}
}
}
//根据作用域为Bean应用引用的代码模式
static BeanDefinitionHolder applyScopedProxyMode(
ScopeMetadata metadata, BeanDefinitionHolder definition, BeanDefinitionRegistry registry) {
//获取注解Bean定义类中@Scope注解的proxyMode属性值
ScopedProxyMode scopedProxyMode = metadata.getScopedProxyMode();
//如果配置的@Scope注解的proxyMode属性值为NO,则不应用代理模式
if (scopedProxyMode.equals(ScopedProxyMode.NO)) {
return definition;
}
//获取配置的@Scope注解的proxyMode属性值,如果为TARGET_CLASS
//则返回true,如果为INTERFACES,则返回false
boolean proxyTargetClass = scopedProxyMode.equals(ScopedProxyMode.TARGET_CLASS);
//为注册的Bean创建相应模式的代理对象
return ScopedProxyCreator.createScopedProxy(definition, registry, proxyTargetClass);
}
5.2.4AnnotationConfigUtils根据注解Bean定义类中配置的作用域为其应用相应的代理策略
AnnotationConfigUtils 类的 applyScopedProxyMode()方法根据注解 Bean 定义类中配置的作用域@Scope注解的值,为Bean定义应用相应的代理模式,主要是在Spring 面向切面编程(AOP)中使用。源码如下:
//根据作用域为Bean应用引用的代码模式
static BeanDefinitionHolder applyScopedProxyMode(
ScopeMetadata metadata, BeanDefinitionHolder definition, BeanDefinitionRegistry registry) {
//获取注解Bean定义类中@Scope注解的proxyMode属性值
ScopedProxyMode scopedProxyMode = metadata.getScopedProxyMode();
//如果配置的@Scope注解的proxyMode属性值为NO,则不应用代理模式
if (scopedProxyMode.equals(ScopedProxyMode.NO)) {
return definition;
}
//获取配置的@Scope注解的proxyMode属性值,如果为TARGET_CLASS
//则返回true,如果为INTERFACES,则返回false
boolean proxyTargetClass = scopedProxyMode.equals(ScopedProxyMode.TARGET_CLASS);
//为注册的Bean创建相应模式的代理对象
return ScopedProxyCreator.createScopedProxy(definition, registry, proxyTargetClass);
}
5.2.5 BeanDefinitionReaderUtils向容器注册Bean
BeanDefinitionReaderUtils 主要是校验 BeanDefinition 信息,然后将 Bean 添加到容器中一个管理BeanDefinition的HashMap中。
5.3扫描指定包并解析为BeanDefinition
当创建注解处理容器时,如果传入的初始参数是注解Bean定义类所在的包时,注解容器将扫描给定的包及其子包,将扫描到的注解Bean定义载入并注册。
5.3.1ClassPathBeanDefinitionScanner扫描给定的包及其子包
AnnotationConfigApplicationContext 通 过 调 用 类 路 径 Bean 定 义 扫 描 器ClassPathBeanDefinitionScanner扫描给定包及其子包下的所有类,主要源码如下:
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider {
//创建一个类路径Bean定义扫描器
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this(registry, true);
}
//为容器创建一个类路径Bean定义扫描器,并指定是否使用默认的扫描过滤规则。
//即Spring默认扫描配置:@Component、@Repository、@Service、@Controller
//注解的Bean,同时也支持JavaEE6的@ManagedBean和JSR-330的@Named注解
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters) {
this(registry, useDefaultFilters, getOrCreateEnvironment(registry));
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//为容器设置加载Bean定义的注册器
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
//为容器设置资源加载器
setResourceLoader(resourceLoader);
}
//调用类路径Bean定义扫描器入口方法
public int scan(String... basePackages) {
//获取容器中已经注册的Bean个数
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
//启动扫描器扫描给定包
doScan(basePackages);
// Register annotation config processors, if necessary.
//注册注解配置(Annotation config)处理器
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
//返回注册的Bean个数
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
//类路径Bean定义扫描器扫描给定包及其子包
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
//创建一个集合,存放扫描到Bean定义的封装类
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//遍历扫描所有给定的包
for (String basePackage : basePackages) {
//调用父类ClassPathScanningCandidateComponentProvider的方法
//扫描给定类路径,获取符合条件的Bean定义
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//遍历扫描到的Bean
for (BeanDefinition candidate : candidates) {
//获取Bean定义类中@Scope注解的值,即获取Bean的作用域
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
//为Bean设置注解配置的作用域
candidate.setScope(scopeMetadata.getScopeName());
//为Bean生成名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//如果扫描到的Bean不是Spring的注解Bean,则为Bean设置默认值,
//设置Bean的自动依赖注入装配属性等
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//如果扫描到的Bean是Spring的注解Bean,则处理其通用的Spring注解
if (candidate instanceof AnnotatedBeanDefinition) {
//处理注解Bean中通用的注解,在分析注解Bean定义类读取器时已经分析过
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//根据Bean名称检查指定的Bean是否需要在容器中注册,或者在容器中冲突
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
//根据注解中配置的作用域,为Bean应用相应的代理模式
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
//向容器注册扫描到的Bean
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
}
类路径Bean定义扫描器ClassPathBeanDefinitionScanner主要通过findCandidateComponents()方法调用其父类ClassPathScanningCandidateComponentProvider类来扫描获取给定包及其子包下的类。
5.3.2 ClassPathScanningCandidateComponentProvider扫描给定包及其子包的类
ClassPathScanningCandidateComponentProvider 类的 findCandidateComponents()方法具体实现扫描给定类路径包的功能,主要源码如下:
public class ClassPathScanningCandidateComponentProvider implements EnvironmentCapable, ResourceLoaderAware {
//保存过滤规则要包含的注解,即Spring默认的@Component、@Repository、@Service、
//@Controller注解的Bean,以及JavaEE6的@ManagedBean和JSR-330的@Named注解
private final List<TypeFilter> includeFilters = new LinkedList<>();
//保存过滤规则要排除的注解
private final List<TypeFilter> excludeFilters = new LinkedList<>();
//构造方法,该方法在子类ClassPathBeanDefinitionScanner的构造方法中被调用
public ClassPathScanningCandidateComponentProvider(boolean useDefaultFilters) {
this(useDefaultFilters, new StandardEnvironment());
}
public ClassPathScanningCandidateComponentProvider(boolean useDefaultFilters, Environment environment) {
//如果使用Spring默认的过滤规则,则向容器注册过滤规则
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(null);
}
//向容器注册过滤规则
@SuppressWarnings("unchecked")
protected void registerDefaultFilters() {
//向要包含的过滤规则中添加@Component注解类,注意Spring中@Repository
//@Service和@Controller都是Component,因为这些注解都添加了@Component注解
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
//获取当前类的类加载器
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
//向要包含的过滤规则添加JavaEE6的@ManagedBean注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.debug("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
//向要包含的过滤规则添加@Named注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.debug("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
//扫描给定类路径的包
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
//创建存储扫描到的类的集合
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
for (TypeFilter filter : this.includeFilters) {
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from "+ filter);
}
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (String type : types) {
//为指定资源获取元数据读取器,元信息读取器通过汇编(ASM)读//取资源元信息
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
//如果扫描到的类符合容器配置的过滤规则
if (isCandidateComponent(metadataReader)) {
//通过汇编(ASM)读取资源字节码中的Bean定义元信息
AnnotatedGenericBeanDefinition sbd = new AnnotatedGenericBeanDefinition(
metadataReader.getAnnotationMetadata());
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Using candidate component class from index: " + type);
}
candidates.add(sbd);
}
else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + type);
}
}
}
else {
if (traceEnabled) {
logger.trace("Ignored because matching an exclude filter: " + type);
}
}
}
}
//判断元信息读取器读取的类是否符合容器定义的注解过滤规则
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
//如果读取的类的注解在排除注解过滤规则中,返回false
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
//如果读取的类的注解在包含的注解的过滤规则中,则返回ture
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
//如果读取的类的注解既不在排除规则,也不在包含规则中,则返回false
return false;
}
}
5.4 注册注解BeanDefinition
AnnotationConfigWebApplicationContext 是 AnnotationConfigApplicationContext 的 Web 版,
它们对于注解 Bean 的注册和扫描是基本相同的,但AnnotationConfigWebApplicationContext
对注解Bean 定义的载入稍有不同,AnnotationConfigWebApplicationContext 注入注解Bean定义源码如下:
//载入注解Bean定义资源
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) {
//为容器设置注解Bean定义读取器
AnnotatedBeanDefinitionReader reader = getAnnotatedBeanDefinitionReader(beanFactory);
//为容器设置类路径Bean定义扫描器
ClassPathBeanDefinitionScanner scanner = getClassPathBeanDefinitionScanner(beanFactory);
//获取容器的Bean名称生成器
BeanNameGenerator beanNameGenerator = getBeanNameGenerator();
//为注解Bean定义读取器和类路径扫描器设置Bean名称生成器
if (beanNameGenerator != null) {
reader.setBeanNameGenerator(beanNameGenerator);
scanner.setBeanNameGenerator(beanNameGenerator);
beanFactory.registerSingleton(AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR, beanNameGenerator);
}
//获取容器的作用域元信息解析器
ScopeMetadataResolver scopeMetadataResolver = getScopeMetadataResolver();
//为注解Bean定义读取器和类路径扫描器设置作用域元信息解析器
if (scopeMetadataResolver != null) {
reader.setScopeMetadataResolver(scopeMetadataResolver);
scanner.setScopeMetadataResolver(scopeMetadataResolver);
}
if (!this.annotatedClasses.isEmpty()) {
if (logger.isInfoEnabled()) {
logger.info("Registering annotated classes: [" +
StringUtils.collectionToCommaDelimitedString(this.annotatedClasses) + "]");
}
reader.register(this.annotatedClasses.toArray(new Class<?>[this.annotatedClasses.size()]));
}
if (!this.basePackages.isEmpty()) {
if (logger.isInfoEnabled()) {
logger.info("Scanning base packages: [" +
StringUtils.collectionToCommaDelimitedString(this.basePackages) + "]");
}
scanner.scan(this.basePackages.toArray(new String[this.basePackages.size()]));
}
//获取容器定义的Bean定义资源路径
String[] configLocations = getConfigLocations();
//如果定位的Bean定义资源路径不为空
if (configLocations != null) {
for (String configLocation : configLocations) {
try {
//使用当前容器的类加载器加载定位路径的字节码类文件
Class<?> clazz = ClassUtils.forName(configLocation, getClassLoader());
if (logger.isInfoEnabled()) {
logger.info("Successfully resolved class for [" + configLocation + "]");
}
reader.register(clazz);
}
catch (ClassNotFoundException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Could not load class for config location [" + configLocation +
"] - trying package scan. " + ex);
}
//如果容器类加载器加载定义路径的Bean定义资源失败
//则启用容器类路径扫描器扫描给定路径包及其子包中的类
int count = scanner.scan(configLocation);
if (logger.isInfoEnabled()) {
if (count == 0) {
logger.info("No annotated classes found for specified class/package [" + configLocation + "]");
}
else {
logger.info("Found " + count + " annotated classes in package [" + configLocation + "]");
}
}
}
}
}
}
以上就是解析和注入注解配置资源的全过程分析。
我们总结一下以上内容:
1、初始化的入口在容器实现中的refresh()调用来完成。
2、对Bean定义载入IOC容器使用的方法是loadBeanDefinition(),其中的大致过程如下:通过 ResourceLoader来完成资源文件位置的定位,DefaultResourceLoader是默认的实现,同时上下文本身就给出了ResourceLoader的实现,可以从类路径,文件系统,URL等方式来定为资源位置。如果是XmlBeanFactory 作为 IOC容器,那么需要为它指定 Bean定义的资源,也 就 是 说 Bean定义文件时通过抽象成 Resource来被IOC容器处理的 ,容器通过BeanDefinitionReader 来完成定义信息的解析和Bean信息的注册 , 往往使用的是XmlBeanDefinitionReader 来 解 析 Bean 的 XML 定 义 文 件 - 实 际 的 处 理 过 程 是 委 托 给BeanDefinitionParserDelegate 来完成的,从而得到 bean 的定义信息,这些信息在 Spring 中使用BeanDefinition对象来表示-这个名字可以让我们想到loadBeanDefinition(),registerBeanDefinition()这些相关方法。它们都是为处理BeanDefinitin服务的,容器解析得到 BeanDefinition 以后,需要把它在 IOC 容器中注册,这由 IOC 实现BeanDefinitionRegistry 接口来实现。注册过程就是在IOC 容器内部维护的一个 HashMap 来保存得到的 BeanDefinition 的过程。这个 HashMap 是 IOC 容器持有Bean信息的场所,以后对Bean的操作都是围绕这个HashMap来实现的。然后我们就可以通过BeanFactory和ApplicationContext来享受到Spring IOC的服务了,在使用IOC容器的时候,我们注意到除了少量粘合代码,绝大多数以正确IOC 风格编写的应用程序代码完全不用关心如何到达工厂,因为容器将把这些对象与容器管理的其他对象钩在一起。基本的策略是把工厂放到已
知的地方,最好是放在对预期使用的上下文有意义的地方,以及代码将实际需要访问工厂的地方。 Spring本身提供了对声明式载入web应用程序用法的应用程序上下文,并将其存储在ServletContext中的框架实现。
对于IOC 整理就以上这些就介绍这么多,如果发现有补充的地方,我会继续添加,同时希望各位看过的伙伴们如果发现了问题能够及时批评指正,在此感谢。
上一篇:深入剖析Spring(三):MVC核心思想
下一篇:深入剖析Spring(五):IOC核心思想(代码篇)