python车牌识别(包括SVM原理)
车牌识别
介绍
opencv数字图像处理,pca+svm车牌识别
说明
该小工程是我为了学习支持向量机算法作为练习的,但继SVM的理论后,更多的困难体在数字图像处理上,比如车牌检测,字符分割,不过在坚持下都已被解决,希望大家能加入一起体验机器学习与数字图像处理
车牌识别的流程:
1检测到车牌
2将车牌的字符分割出来
3字符逐个使用SVM模型识别
具体的原理(包括SVM超平面推导公式)位于文件夹“theory”,格式为word
安装教程
python3
安装需要的库即可:
numpy
pandas
opencv
scikit-learn
eg:pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
使用说明
首先可以直接运行demo.py,直接查看车牌识别的结果
作为学习,大家可以一步一步参与:
1.SVM:pixeltocsv将训练图片写入csv
svmtrain训练svm模型,其中用pca进行降维,模型保存为.m格式
loadsvm作为使用模型的接口
2.locate,车牌定位:高斯滤波,中值滤波;
Sobel算子边缘检测,二值化;
膨胀一次,腐蚀一次;
根据车牌长高比范围查找轮廓,将轮廓裁剪出来
3.spli,字符分割:反复滤波获得不含杂质(垂直投影不连续)的二值图像,
根据字符像素的脉冲信号起止分割字符
4.字符逐个使用SVM识别
注意如果是opencv版本差异带来的问题:
image_process,contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
改为
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)即可
由于训练集只有数字和英文,所以不能识别车牌的中文字符
demo结果
输入图片

字符分割后
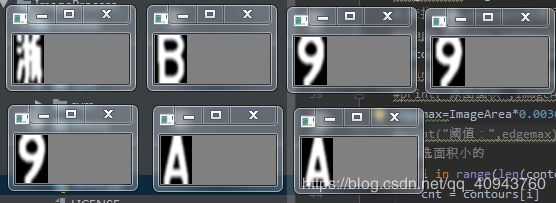
输出结果,数据集只有英文与数字,所以不识别中文
SVM原理:
首先,识别的方法是很多的,比如对于提取出来的一个个数字,用一个softmax网络就可以达到目的,CNN的正确率会更高,这个小小project选择svm进行分类主要是为了体验一下深度学习之前的最受好评的机器学习算法。
以下直接贴我写的文档内容,打字太累了:

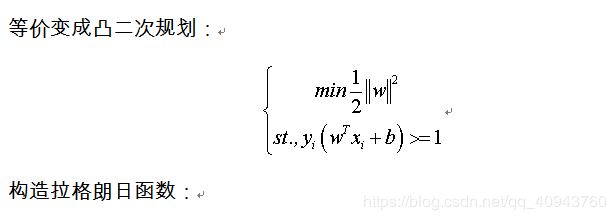



 做这个小项目的初衷是为了体验在深度学习出现前最流行的SVM,但是数字图像处理真的让我够头疼的,目前车牌字符分割上还存在一定问题,后续版本有待改进
做这个小项目的初衷是为了体验在深度学习出现前最流行的SVM,但是数字图像处理真的让我够头疼的,目前车牌字符分割上还存在一定问题,后续版本有待改进
车牌定位:
import cv2
import numpy as np
def preprocess(gray):
# # 直方图均衡化
# equ = cv2.equalizeHist(gray)
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
# 中值滤波
median = cv2.medianBlur(gaussian, 5)
#cv2.imshow('gaussian&media', median)
#cv2.waitKey(0)
# Sobel算子,X方向求梯度
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
# 二值化
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
#print("阈值:",ret)
#cv2.imshow('binary', binary)
#cv2.waitKey(0)
# 膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 7))
# 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蚀一次,去掉细节
erosion = cv2.erode(dilation, element1, iterations=1)
#cv2.imshow('erosion', erosion)
#cv2.waitKey(0)
# 再次膨胀,让轮廓明显一些
dilation2 = cv2.dilate(erosion, element2, iterations=3)
#cv2.imshow('dilation2', dilation2)
#cv2.waitKey(0)
return dilation2
def findPlateNumberRegion(img,ImageArea):
region = []
# 查找轮廓,contours记录了每一个闭合的轮廓索引
#image_process,contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#print("轮廓数:",len(contours))
#print("原图面积",ImageArea)
edge=ImageArea*0.016
#print("阈值:",edge)
# 筛选面积小的
for i in range(len(contours)):
cnt = contours[i]
# 计算该轮廓的面积
area = cv2.contourArea(cnt)
#print("面积:",area)
# 面积小的都筛选掉
if (area < edge):
continue
# 轮廓近似,作用很小
epsilon = 0.001 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 找到最小的矩形包围轮廓,该矩形可能有方向
#返回矩形的中心点坐标,长宽,旋转角度[-90,0)
rect = cv2.minAreaRect(cnt)
#print("rect is: ",rect)
# box是四个点的坐标
box = cv2.boxPoints(rect)
#取整
box = np.int0(box)
# 计算高和长
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 车牌正常情况下长高比在2.7-5之间
ratio = float(width) / float(height)
#print("ratio: ",ratio)
if (ratio > 5 or ratio < 2):
continue
region.append(box)
print("车牌区域:",region)
print("车牌个数:",len(region))
return region
def detect(img):
"""截取车牌"""
# 转化成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#输入图像面积
height, width = img.shape[:2]
ImageArea=height*width
# 形态学变换的预处理
dilation = preprocess(gray)
# 查找车牌区域
region = findPlateNumberRegion(dilation,ImageArea)
# 用绿线画出这些找到的轮廓
for boxf in region:
cv2.drawContours(img, [boxf], 0, (0, 0, 0), 2)
ys = [boxf[0, 1], boxf[1, 1], boxf[2, 1], boxf[3, 1]]
xs = [boxf[0, 0], boxf[1, 0], boxf[2, 0], boxf[3, 0]]
ys_sorted_index = np.argsort(ys)
xs_sorted_index = np.argsort(xs)
x1 = boxf[xs_sorted_index[0], 0]
x2 = boxf[xs_sorted_index[3], 0]
y1 = boxf[ys_sorted_index[0], 1]
y2 = boxf[ys_sorted_index[3], 1]
img_org2 = img.copy()
img_plate = img_org2[y1:y2, x1:x2]
#cv2.imshow('number plate', img_plate)
#cv2.imwrite("./plate.png",img_plate)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
return img_plate
if __name__ == '__main__':
imagePath = './car1.png'
img = cv2.imread(imagePath)
cv2.imshow('img', img)
plate=detect(img)字符分割:
import numpy as np
import cv2
def preprocess(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
# 中值滤波
median = cv2.medianBlur(gaussian, 5)
#cv2.imshow('gaussian&media', median)
#cv2.waitKey(0)
# 二值化
ret, binary = cv2.threshold(gaussian, 225, 255, cv2.THRESH_BINARY)
#ret, binary = cv2.threshold(sobel, 90, 255, cv2.THRESH_BINARY)
#print("阈值:",ret)
#cv2.imshow('binary', binary)
#cv2.waitKey(0)
# 膨胀和腐蚀操作的核函数
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 7))
# 膨胀一次,让轮廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蚀一次,去掉细节
erosion = cv2.erode(dilation, element1, iterations=1)
#cv2.imshow('erosion', erosion)
#cv2.waitKey(0)
dilation2 = cv2.dilate(erosion, element2, iterations=1)
#cv2.imshow('dilation2', dilation2)
#cv2.waitKey(0)
return binary,dilation2
def pickpoint(img):
height, width = img.shape[:2]
ImageArea=height*width
# 查找轮廓,contours记录了每一个闭合的轮廓索引
#image_process,contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#print("轮廓数:",len(contours))
#print("原图面积",ImageArea)
edgemax=ImageArea*0.0036
#print("阈值:",edgemax)
# 筛选面积小的
for i in range(len(contours)):
cnt = contours[i]
# 计算该轮廓的面积
area = cv2.contourArea(cnt)
#print("面积:",area)
# 面积小的都筛选掉
if (area < edgemax):
rect = cv2.minAreaRect(cnt)
#print("rect is: ", rect)
# box是四个点的坐标
box = cv2.boxPoints(rect)
box = np.int0(box)
#print("box",box)
img=cv2.drawContours(img, [box], -1, (0, 0, 255), thickness=-1)
#cv2.imshow("pick",img)
#cv2.waitKey(0)
#腐蚀一次
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
img = cv2.erode(img, element1, iterations=1)
#cv2.imshow("erimg", img)
#cv2.waitKey(0)
return img
def find_end(start,arg,black,white,width,black_max,white_max):
"""找到每个脉冲的终止"""
end=start+1
for m in range(start+1,width-1):
if (black[m] if arg else white[m])>(0.95*black_max if arg else 0.95*white_max):
end=m
break
return end
def cut(thresh,binary):
char=[]
white=[]
black=[]
height=thresh.shape[0]
width=thresh.shape[1]
print('height',height)
print('width',width)
white_max=0
black_max=0
#计算每一列的黑白像素总和
for i in range(width):
line_white=0
line_black=0
for j in range(height):
if thresh[j][i]==255:
line_white+=1
if thresh[j][i]==0:
line_black+=1
white_max=max(white_max,line_white)
black_max=max(black_max,line_black)
white.append(line_white)
black.append(line_black)
#print('white',white)
#print('black',black)
#arg为true表示黑底白字,False为白底黑字
arg=True
if black_max<white_max:
arg=False
n=1
while n<width-2:
n+=1
#判断是白底黑字还是黑底白字 0.05参数对应上面的0.95 可作调整
if(white[n] if arg else black[n])>(0.05*white_max if arg else 0.05*black_max):
start=n
end=find_end(start,arg,black,white,width,black_max,white_max)
n=end
if end-start>5:
cj=binary[1:height,start:end]
#左右填充
cjwidth = cj.shape[1]
cjheight=cj.shape[0]
cj=cv2.copyMakeBorder(cj,0,0,int(cjwidth*0.2),int(cjwidth*0.2),cv2.BORDER_CONSTANT, value=0)
#上下裁剪,因为要适应到数据集
cjwidth = cj.shape[1]
length=int(cjheight*0.25)
cj=cj[length:cjheight-length,0:cjwidth]
#平滑
cj = cv2.GaussianBlur(cj, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
# 均值平滑
cj = cv2.blur(cj, (3, 5))
#直方图均衡化
cj=cv2.equalizeHist(cj)
#二值化扩大亮度
ret, cj = cv2.threshold(cj, 60, 255, cv2.THRESH_BINARY)
cj = cv2.GaussianBlur(cj, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
cj = cv2.blur(cj, (3, 5))
char.append(cj)
#print("result/%s.jpg" % (n))
#cv2.imshow('cutlicense',cj)
#cv2.waitKey(0)
return char
if __name__ == '__main__':
imagePath = './plate.png'
img = cv2.imread(imagePath)
cv2.imshow('img', img)
binary,dilation2=preprocess(img)
thresh=pickpoint(dilation2)
charlist=cut(thresh,binary)
cv2.waitKey(0)
cv2.destroyAllWindows()SVM训练:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn import svm
from sklearn.externals import joblib
import time
from sklearn.utils import shuffle
if __name__ =="__main__":
data = pd.read_csv('./train.csv')
data = shuffle(data)
train_num = 5000
test_num = 7000
train_data = data.values[0:train_num,1:]
train_label = data.values[0:train_num,0]
test_data = data.values[train_num:test_num,1:]
test_label = data.values[train_num:test_num,0]
t = time.time()
#PCA降维
pca = PCA(n_components=0.8, whiten=True)
print('start pca...')
train_x = pca.fit_transform(train_data)
test_x = pca.transform(test_data)
print(train_x.shape)
# svm训练
print('start svc...')
svc = svm.SVC(kernel = 'rbf', C = 10)
svc.fit(train_x,train_label)
pre = svc.predict(test_x)
#保存模型
joblib.dump(svc, 'model.m')
joblib.dump(pca, 'pca.m')
# 计算准确率
score = svc.score(test_x, test_label)
"""
start pca...
(5000, 21)
start svc...
准确率:0.980500,花费时间:1.99s
"""
print(u'准确率:%f,花费时间:%.2fs' % (score, time.time() - t))Demo:
import locate.locateplate as locateplate
import split.splitarea as splitarea
import svm.loadsvc as loadsvc
import cv2
class Demo():
def __init__(self,img_path,svc_path,pca_path):
self.img_path=img_path
self.svc_path=svc_path
self.pca_path=pca_path
def run(self):
#车牌定位
img = cv2.imread(self.img_path)
cv2.imshow("car",img)
plate=locateplate.detect(img)
#字符分割
binary,dilation=splitarea.preprocess(plate)
thresh = splitarea.pickpoint(dilation)
charlist = splitarea.cut(thresh,binary)
#加载svm模型
svc, pca = loadsvc.load_model(self.svc_path,self.pca_path)
string=[]
#每个字符进行识别
for i in range(len(charlist)):
name="result{}".format(str(i))
cv2.imshow(name,charlist[i])
#没有中文数据集,所以不进行识别中文
if(i==0):
continue
char=cv2.resize(charlist[i], (20, 20), interpolation=cv2.INTER_CUBIC)
test=char.reshape(1,400)
test_x = pca.transform(test)
pre = svc.predict(test_x)
string.append(loadsvc.nameindex(pre))
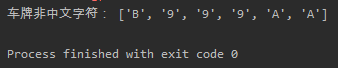
print("车牌非中文字符:",string)
cv2.waitKey(0)
if __name__ == '__main__':
img_path="./valimg/car.jpg"
svc_path="./svm/model.m"
pca_path="./svm/pca.m"
platedemo=Demo(img_path,svc_path,pca_path)
platedemo.run()能和大家一起学习很开心,Bye~