Pandas-学习数据处理
欢迎转载,转载请注明出处: https://blog.csdn.net/qq_41709378/article/details/105374247
————————————————————————————————————————————————————
最近用pandas进行了不少数据处理,如果你是做大数据分析和测试的,那么这个是非常非常适合你!!
其实我们平时在做时序数据预测分析的时候,如果涉及到数据的读取和存储,那么利用pandas就会非常高效,希望大家可以踊跃的去尝试和探索pandas的巧妙!
学习链接:
官网: pandas.
中文网: pandas.
Pandas入门: pandas.
以下是本人学习pandas整理的思维导图:
思维导图-Pandas:
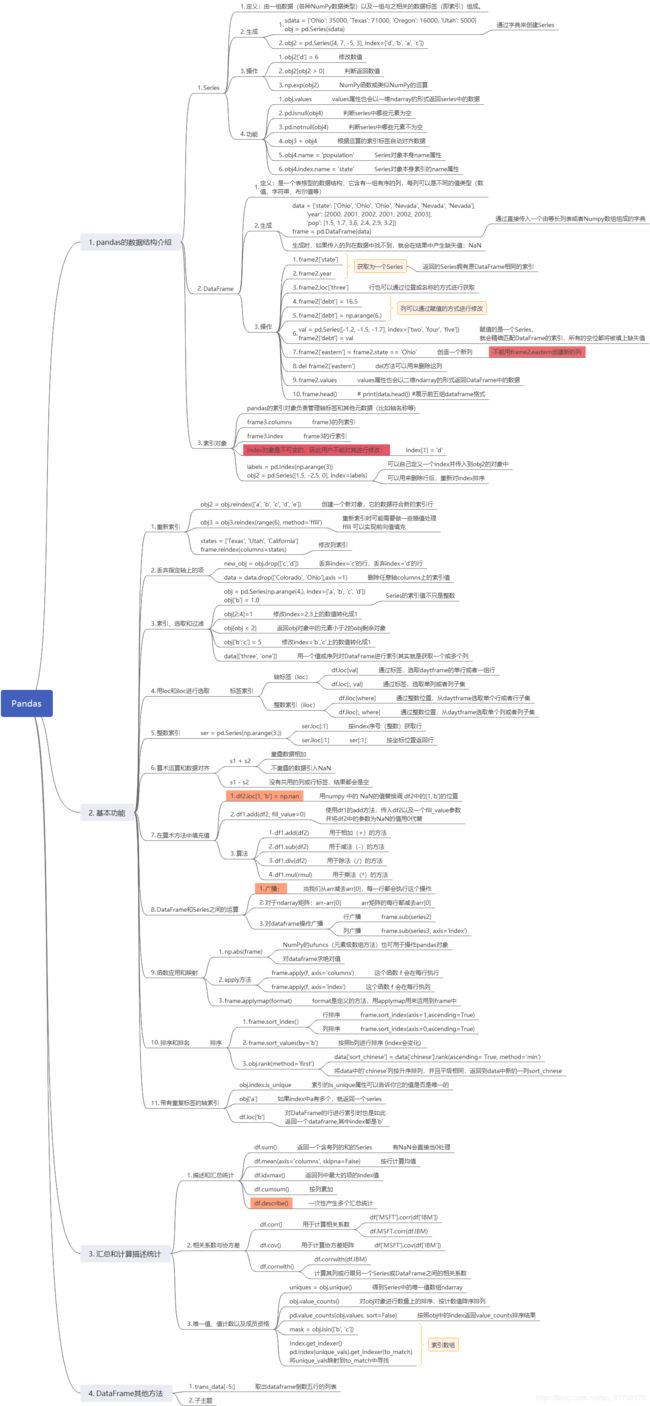
PS: 部分框架有待填充…
1. Pandas引入
1.1 特点:
使用 DataFrame.dtypes 可以查看每列的数据类型,Pandas默认可以读出int和float64,其它的都处理为object,需要转换格式的一般为日期时间。DataFrame.astype() 方法可对整个DataFrame或某一列进行数据格式转换,支持Python和NumPy的数据类型。
要使用pandas,你首先就得熟悉它的两个主要数据结构:Series和DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
1.1 pd.Series:
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据即可产生最简单的Series:
obj = pd.Series([4, 5, -1, 3])
print(obj)0 4
1 5
2 -1
3 3
dtype: int64制作一个pd.Series单列索引
val = pd.Series([-1.2,-1.5,-1.7],
index=['one','two','three'])
print(val)one -1.2
two -1.5
three -1.7
dtype: float641.1 pd.DataFrame:
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
创建DataFrame的办法有很多,最常用的一种是直接传入一个由等长列表或NumPy数组组成的字典:
data = {
'chinese': [75, 68, 54, 55, 59, 45, 61],
'english': [69, 85, 42, 57, 35, 63, 53],
'math': [36, 87, 59, 63, 92, 92, 76],
'name': ['a', 'b', 'c', 'd', 'e', 'e', 'f'],
'test': [1, 1, 1, 2, 2, 3, 1]
}
df = pd.DataFrame(data,columns=['chinese','english','math','name','test'])
print(df) chinese english math name test
0 75 69 36 a 1
1 68 85 87 b 1
2 54 42 59 c 1
3 55 57 63 d 2
4 59 35 92 e 2
5 45 63 92 e 3
6 61 53 76 f 1以上是简介pandas的两个主要数据结构,研究使用pandas进行数据清洗、规整、分析和可视化工具是一个漫长的过程。
2. 实战数据处理 PK Excel
2.1 Pandas处理excel数据:
1:在利用pandas模块进行操作前,可以先引入这个模块,如下:
import pandas as pd读取Excel文件的两种方式
#方法一:默认读取第一个表单
df1 = pd.read_excel(path) # path为文件路径
data=df.head() # 默认读取前5行的数据#方法二:通过指定表单名的方式来读取
df2 = pd.read_excel(path,sheet_name='student') # 可以通过sheet_name来指定读取的表单
data=df.head() # 默认读取前5行的数据更多参数设置可以参考:
def read_excel(io,
sheet_name=0, # 工作表名称
header=0, # 指定作为列名的行
names=None, # 要使用的列名列表
index_col=None, # 指定列为索引列
parse_cols=None,
usecols=None, # int或list,默认为None
squeeze=False, # 如果解析的数据只包含一列,则返回一个Series
dtype=None, # 列的类型名称或字典
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None, # 省略指定行数的数据,从第一行开始
nrows=None,
na_values=None,
keep_default_na=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0, # 省略指定行数的数据,从尾部数的行开始
convert_float=True,
mangle_dupe_cols=True,
**kwds):其余参数不常使用,不做补充。
2:读取指定的单行,数据会存在列表里面
df = pd.read_excel(path) # 默认读取到这个Excel的第一个表单
data = df.ix[0].values # 0表示第一行 读取数据并不包含表头。3:读取指定的多行,数据会存在列表里面
df = pd.read_excel(path)
data=df.ix[[1,2]].values # 读取指定多行,在ix[]里面嵌套列表指定行数4:读取指定的行列,获取具体的值
df = pd.read_excel(path)
data = df.ix[1,2] # 读取第一行第二列的值5:读取指定的多行多列值:
df=pd.read_excel(path)
data = df.ix[[0,1],['日期', '销售件数']].values # 读取第一行第二行的日期以及销售件数列的值6:获取所有行的指定列
df = pd.read_excel('path')
data = df.ix[:,['日期','销售件数']].values #读所有行的日期以及销售件数列的值除了使用 pd.ix(),还使用pd.iloc()、pd.loc(),具体索引方式可以参照原文上的学习链接。
2.2 案例实战:
用excel做数据匹配的任务时,由于数据量很大,对excel中不同Sheet处理显得很麻烦,因此想到用pyhton中pandas模块对excel不同Sheet的数据进行操作。
任务:
实现excel中不同Sheet,按列数据匹配及填补工作。
具体过程是:Sheet1中有2017-11-11至2019-03-12中部分时间段的销量件数,我们将这部分时间段的数据匹配到Sheet2中2017-11-11至2019-03-12对应的位置并填补,Sheet2中未填补的数据进行补0。
数据:
为了方便学习,我上传了数据:
百度网盘链接: 点我获取excel数据.
提取码:v83d
实践过程:
1:导入模块
在实现上述案例时,要到导入两个模块
import pandas as pd
from openpyxl import load_workbook #在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells 重要!!!2:匹配过程
运用for循环遍历Sheet1中的"时间"列,同时与Sheet2中完整的"时间"列进行匹配,对匹配到的时间,传入对应的销售件数。
path = 'D:/Python/Python_learning/HBUT/预处理/data1.xlsx'
df1 = pd.read_excel(path, sheet_name='Sheet1') # 可以通过sheet_name来指定读取的表单
df2 = pd.read_excel(path, sheet_name='Sheet2') # 可以通过sheet_name来指定读取的表单
# 时间匹配对应的数据写入到新的列表中
for i in range(df1.shape[0]):
data_time = df1.iloc[i, 0] # 获取时间
data_number = df1.iloc[i, 1] # 获取销量
data_loc = df2[ df2['日期'] == data_time ].index.tolist()
#将data_loc赋值到Sheet2中
df2.iloc[data_loc[0], 1] = data_number #对应的销量转入到时间列表中
df2['销售件数'] = df2['销售件数'].fillna(value = 0) # 将NaN转换成0最后fillna(value = 0)实现的"销售件数"列缺失值补0
3:防止excel中原有Sheets数据被覆盖
运用book,和writer方法可以避免在使用pandas的to_excel写入到已经存在的excel表格中,原有数据的几张sheet被无情的删除。(ps:本人尝试过很多次,真香)
book = load_workbook(path)
writer = pd.ExcelWriter(path, engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df2.to_excel(writer, "Sheet2", columns=['日期','销售件数'],index=False)
writer.save()3:错误诊断
在使用pandas的to_excel写入到已经存在的excel表格中难免会遇到几个经典的错误:
Traceback (most recent call last):
File "D:/Python/Python_learning/HBUT/预处理/c1.py", line 39, in <module>
writer.save()
File "D:\Python\bao1\lib\site-packages\pandas\io\excel.py", line 1228, in save
return self.book.save(self.path)
File "D:\Python\bao1\lib\site-packages\openpyxl\workbook\workbook.py", line 409, in save
save_workbook(self, filename)
File "D:\Python\bao1\lib\site-packages\openpyxl\writer\excel.py", line 292, in save_workbook
archive = ZipFile(filename, 'w', ZIP_DEFLATED, allowZip64=True)
File "D:\Python\bao1\lib\zipfile.py", line 1009, in __init__
self.fp = io.open(file, filemode)
PermissionError: [Errno 13] Permission denied: 'D:/Python/Python_learning/HBUT/预处理/data1.xlsx'
莫慌,这个错误很常见。
原因是:你未关闭excel文件,关闭excel,重新尝试
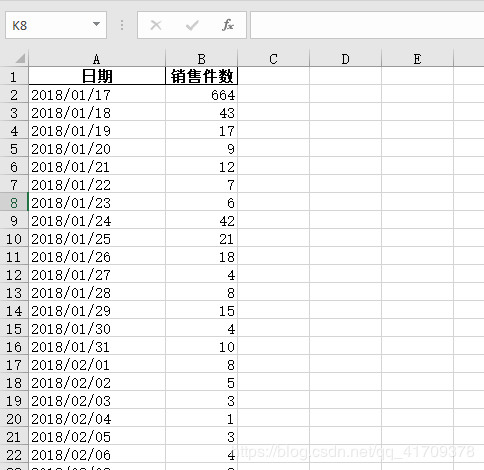
4:结果展示
Sheet1数据:
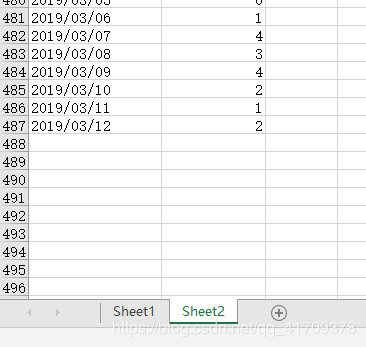
填补完Sheet2的数据:


5:完整代码
# -*- coding: utf-8 -*-
# @Time : 2020/4/3 18:10
# @Author : Zudy
# @FileName: c1.py
'''
1.时间匹配写入到另外的文件中
2.用pandas的to_excel来写入到已经存在的excel表格,但是发现不用的几张sheet被删除
'''
import pandas as pd
from openpyxl import load_workbook
path = 'D:/Python/Python_learning/HBUT/预处理/data1.xlsx'
df1 = pd.read_excel(path, sheet_name='Sheet1')#可以通过sheet_name来指定读取的表单
df2 = pd.read_excel(path, sheet_name='Sheet2')#可以通过sheet_name来指定读取的表单
#时间匹配对应的数据写入到新的列表中
for i in range(df1.shape[0]):
data_time = df1.iloc[i, 0] #获取时间
data_number = df1.iloc[i, 1] #获取销量
data_loc = df2[ df2['日期'] == data_time ].index.tolist()
#将data_loc赋值到Sheet2中
df2.iloc[data_loc[0], 1] = data_number #对应的销量转入到时间列表中
#将NaN转换成0
df2['销售件数'] = df2['销售件数'].fillna(value = 0)
#运用book,和writer方法可以避免用pandas的to_excel来写入到已经存在的excel表格,但是发现不用的几张sheet被删除
book = load_workbook(path)
writer = pd.ExcelWriter(path, engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df2.to_excel(writer, "Sheet2", columns=['日期','销售件数'],index=False)
writer.save()后续我会长时期与数据处理与分析接触,也会慢慢学习用python实现机器学习的其他模块。
欢迎学习交流…