Python爬取网络图片详解
大家好,本期将跟大家分享一下如何利用Python实现网络图片的爬取和存储。前面本人已经尝试过利用urlretrieve()方法爬取守望先锋官网所有英雄图片。今天本人要分享的是Python中的一个http库——requests库,并且通过举两个例子,来告诉大家如何利用requests库实现网络图片的爬取和存储。
实例一:爬取爱宠网上宠物狗图片
首先找到爱宠网网站,本文以爬取下面第一张卡迪根威尔士柯基的图片为例:
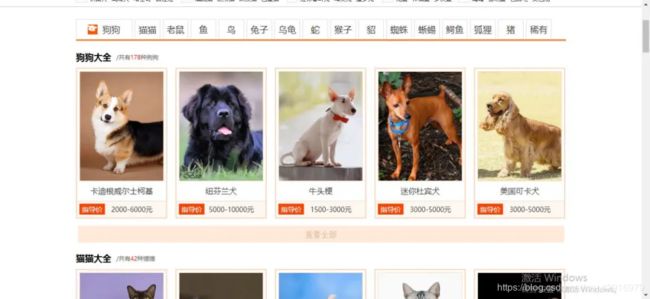
然后点击查看这只狗的详细信息如下:
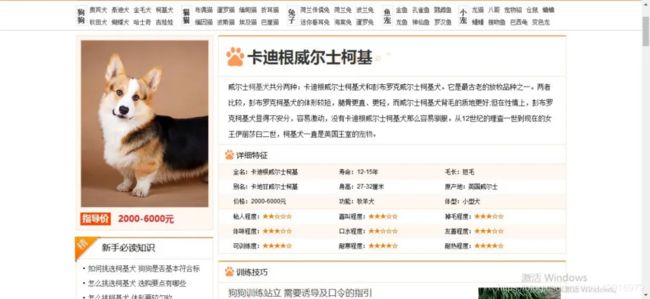
之后通过鼠标右键检查,找到该图片对应的url地址。
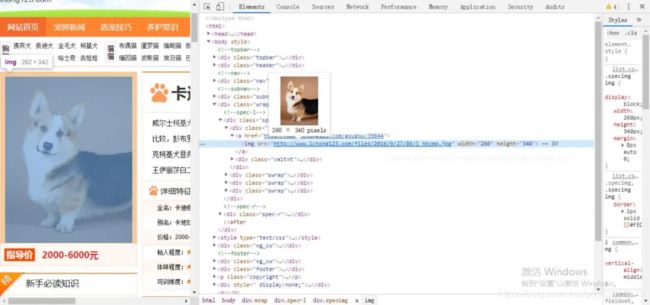
可以看到,该图片对应的url地址为:http://www.ichong123.com/files/2016/9/27/86/1_hkcmq.jpg。
下面将介绍如何使用requests库实现网页图片的爬取和存储。
首先,我们需要导入requests库。
import requests # 导入requests库
然后需要获取网页内容,这里我们可以先使用get()方法,返回一个服务资源的Response对象。
r = requests.get('http://www.ichong123.com/files/2016/9/27/86/1_hkcmq.jpg') # 获取网页内容
这里,我们可以用type函数查看一下变量r的类型:
type(r) # 查看变量类型
运行结果:
requests.models.Response
可以看到,变量r的类型为一个Response对象。
那么如何查看网页是否访问成功呢?可以通过检测请求的状态码,如果状态码为200,表示访问成功,如果为404,503等其它数字,说明访问失败。下面我们查看一下网页是否访问成功。
r.status_code # 检测请求的状态码
运行结果:
200
可以看到,状态码为200,说明网页访问成功。
为了实现图片的存储,我们还需导入os模块。os模块提供了丰富的方法用来处理文件和目录。本文假设爬取的网络图片存储在C:\Users\Lenovo\Desktop\图片目录下,可以通过以下几行代码实现。
path = 'C:\\Users\\Lenovo\\Desktop\\图片' # 图片存储位置
if not os.path.exists(path): # 检查桌面是否有一个名字为“图片”的文件夹,如果没有,就创建它
os.mkdir(path)
这样,本人电脑桌面就新建了一个名为图片的文件夹。
最后我们就可以使用Response对象的content属性爬取上述图片了。利用content属性,可以获取http响应内容的二进制形式,然后通过文件写入的方式,即可爬取该图片。
1with open(path + '\\dog.jpg', 'wb') as f: # 以写入方式打开文件
2 f.write(r.content) # 写入文件
3 f.close # 关闭文件
最后,我们发现,图片已经爬取成功,并给图片取名dog.jpg。

以下是完整代码:
import requests # 导入requests库
import os # 导入os模块
def down_pic(url, filename):
'''定义一个函数,用于下载网络图片,参数url为图片对应的url地址,filename为爬取图片名字'''
r = requests.get(url) # 获取网页内容
path = 'C:\\Users\\Lenovo\\Desktop\\图片' # 爬取图片待存储目录
if not os.path.exists(path): # 判断桌面是否有一个名称为“图片”的文件夹,如果没有,就创建它
os.mkdir(path) # 爬取图片
with open(path + '\\' + filename, 'wb') as f:
f.write(r.content) # 以二进制形式写入文件
f.close # 关闭文件
if __name__ == '__main__':
url = 'http://www.ichong123.com/files/2016/9/27/86/1_hkcmq.jpg' # 图片对应的url地址
down_pic(url, 'dog.jpg') # 调用函数
实例二:爬取抖音视频
爬取视频的方法跟上述一样,首先需要找到视频对应的url地址,然后替换即可。本文尝试爬取本人一位同学在抖音发布的关于王者荣耀的视频,此人操作、意识一流,号称××大学第一关羽,是一位时常在王者荣耀大神观战出没的男子,一位集颜值与实力于一身的明星级人物,他就是放学都别走灬(为他打个广告)。
如何爬取呢?只需修改实例一代码中的少量内容,即可实现抖音视频的爬取,以下是完整代码:
import requests # 导入requests库
import os # 导入os模块
def down_video(url, filename):
'''定义一个函数,用于下载抖音视频,参数url为视频对应的url地址,filename为爬取视频名字'''
r = requests.get(url) # 获取网页内容
path = 'C:\\Users\\Lenovo\\Desktop\\抖音' # 爬取视频待存储目录
if not os.path.exists(path): # 判断桌面是否有一个名称为“抖音”的文件夹,如果没有,就创建它
os.mkdir(path)
# 爬取视频
with open(path + '\\' + filename, 'wb') as f:
f.write(r.content) # 以二进制形式写入文件
f.close # 关闭文件
if __name__ == '__main__':
url = 'http://v26-dy.ixigua.com/142e8e004651705cc784f5866ff348bf/5ee1be37/video/tos/hxsy/tos-hxsy-ve-0015/45b6077ce7594c8cb542d9271cbd396c/?a=1128&br=11061&bt=3687&cr=0&cs=0&dr=0&ds=3&er=&l=20200611121613010014040037000724BB&lr=aweme&mime_type=video_mp4&qs=0&rc=M3Rwajd5c3Y6czMzZ2kzM0ApNWk4ZjhoZ2U4NzhnOGU4O2duLjZvM25vanJfLS0vLS9zczMuYDAwMi4zMGE0Xi9iMi46Yw%3D%3D&vl=&vr=' # 视频对应的url地址
down_video(url, '××大学第一关羽.mp4') # 调用函数
由于视频无法上传,大家可自行下载。
好了,以上就是本期内容,谢谢您的阅读!
往期精彩:
Python基础(一)| 变量与数据类型
Python基础(二)| 列表
Python基础(三)| 元组
想要学习更多?欢迎关注本人公众号:Python无忧
