Python爬虫实战练习(疫情数据获取)
- 一、国内疫情数据的爬取
- 1.1 获取响应
- 1.2 使用xpath解析数据
- 1.2.1 分析xpath解析的数据
- 1.2.2 再一次分析数据
- 1.3 json转化xpath数据类型
- 1.4 逐个获取我们需要的数据,并保存至Excel中
- 1.4.1 创建工作簿
- 1.4.2 创建工作表
- 1.4.3 写入数据至表中
- 1.4.4 数据保存
- 1.5 代码汇总
- 二、国外疫情数据的爬取
- 2.1 代码汇总
- 三、结果
一、国内疫情数据的爬取
1.1 获取响应
# 导入requests库
import requests
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)
# 查看响应的编码
print("编码:",response.encoding)
# 查看响应头
print(response.headers)
# 查看响应地址
print("地址:",response.url)
# 查看响应状态码,200表示请求成功
print("状态码:",response.status_code)
# 查看正确响应的结果,并与网页源代码比较一下,是否相同
result = response.text
print(result)
1.2 使用xpath解析数据
# 导入xpath库,如未安装在cmd里面输入pip install xpath即可
from lxml import etree # 将数据转化为树形态
# 生成HTML对象
html = etree.HTML(result)
result = html.xpath('//script[@type="application/json"]/text()')
1.2.1 分析xpath解析的数据
# 查看解析结果
print(result)
# 查看数据类型
print(type(result))
# 查看列表长度
print(len(result))
# 进一步提取列表中的数据
result = result[0]
1.2.2 再一次分析数据
# 查看上一步提取结果
print(result)
# 查看数据类型
print(type(result))
1.3 json转化xpath数据类型
使用json.loads()方法可以将字符串转换为Python的基本数据类型
# 导入Json库,此库无需安装
import json
result = json.loads(result)
# 查看结果
print(result)
# 查看数据类型
print(type(result))
# 获取字典中所有的键
print(result.keys())
# 查看每一个键对应的数据
print(result["page"])
# 查看每一个键对应的数据
print(result["component"])
# 查看每一个键对应的数据
print(result["bundle"])
# 查看每一个键对应的数据
print(result["version"])
通过查看这些键,可以得出result[“component”]才是我们需要的结果,但是探索还未结束,还要继续
result = result["component"]
# 查看结果
print(result)
# 查看数据类型
print(type(result))
# 查看列表长度
print(len(result))
# 提取列表中的数据
result = result[0]
# 查看数据
print(result)
# 查看数据类型
print(type(result))
# 获取所有的键值
print(result.keys())
从上面的结果中可以看到数据量特别的大,因此这里只查看我们需要的目标数据
# 查看所有键值
# for i in result.keys():
# print(i)
# print(result[i])
# print("*"*20)
# 查看当前数据更新时间
result['mapLastUpdatedTime']
# 中国当前时间的数据省市数据
# result['caseList']
# 国外数据更新时间
result["foreignLastUpdatedTime"]
# 国外数据
# result['caseOutsideList']
# 全球数据
# result["globalList"]
查看国内当前数据
result = result['caseList']
for each in result:
print(each)
print("--"*30)
各项数据总结:
| 类型 | 说明 |
|---|---|
| confirmed | 累计确诊人数 |
| died | 死亡人数 |
| crued | 治愈人数 |
| relativeTime | 时间 |
| confirmedRelative | 确诊增量 |
| diedRelative | 死亡增量 |
| curedRelative | 治愈增量 |
| curConfirm | 现有确诊 |
| curConfirmRelative | 现有确诊增量 |
| icuDisable | ID编号 |
| area | 省/直辖市/特别行政区 |
| subList | area的地级市 |
1.4 逐个获取我们需要的数据,并保存至Excel中
# 导入模块
import openpyxl
1.4.1 创建工作簿
wb = openpyxl.Workbook()
1.4.2 创建工作表
ws = wb.active
# 设置表的标题
ws.title = "国内疫情"
1.4.3 写入数据至表中
# 写入表头
ws.append(["省份","累计确诊","死亡","治愈"])
for each in result:
list_name = [each["area"],each["confirmed"],each["died"],each["crued"]]
# 如果为空则填充0
for i in list_name:
if i == "":
i = "0"
ws.append(list_name)
1.4.4 数据保存
wb.save('./data1.xlsx')
1.5 代码汇总
# 导入requests库
import requests
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)
# 查看正确响应的结果,并与网页源代码比较一下,是否相同
result = response.text
# 导入xpath库,如未安装在cmd里面输入pip install xpath即可
from lxml import etree # 将数据转化为树形态
# 生成HTML对象
html = etree.HTML(result)
result = html.xpath('//script[@type="application/json"]/text()')
result = result[0]
# 导入Json库,此库无需安装
import json
result = json.loads(result)
result = result["component"]
# 获取国内当前数据
result = result[0]['caseList']
# 导入模块
import openpyxl
# 创建工作簿
wb = openpyxl.Workbook()
# 创建工作表
ws = wb.active
# 设置表的标题
ws.title = "国内疫情"
# 写入表头
ws.append(["省份","累计确诊","死亡","治愈"])
# 写入各行
for each in result:
list_name = [each["area"],each["confirmed"],each["died"],each["crued"]]
# 如果为空则填充0
for i in list_name:
if i == "":
i = "0"
ws.append(list_name)
# 保存至excel中
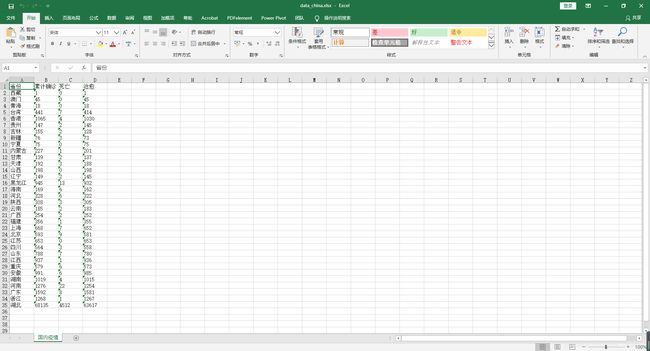
wb.save('./data_china.xlsx')
二、国外疫情数据的爬取
根据国内的方法,只需要将result[‘caseList’] 改为 result[“globalList”]即可
# 导入requests库
import requests
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)
# 查看正确响应的结果,并与网页源代码比较一下,是否相同
result = response.text
# 导入xpath库,如未安装在cmd里面输入pip install xpath即可
from lxml import etree # 将数据转化为树形态
# 生成HTML对象
html = etree.HTML(result)
result = html.xpath('//script[@type="application/json"]/text()')
result = result[0]
# 导入Json库,此库无需安装
import json
result = json.loads(result)
result = result["component"]
# 获取国外当前数据
result = result[0]
result = result["globalList"]
# 查看国外数据
# print(result)
# 可以发现结果为一个列表且长度为8
print(type(result),len(result))
# 通过遍历并分析这个列表,发现这里是以七大洲和钻石公主号邮轮构成的这个列表
for i in result:
print(i)
print("-"*50)
以每个洲以及邮轮分别创建一个表,来存储各个州的各个国家的数据
# 导入模块
import openpyxl
# 创建工作簿
wb = openpyxl.Workbook()
for each in result:
title = each["area"] # 获取各州名
ws = wb.create_sheet(title) # 根据名称创建多个工作表
ws.append(["国家","累计确诊","死亡","治愈"]) # 写入表头至新建的表
for country in each["subList"]: # 可以从原始数据中看到各个国家的数据在"subList"键中
list_name = [country["country"],country["confirmed"],country["died"],country["crued"]]
for i in list_name:
if i == "":
i = "0"
ws.append(list_name)
# 保存至excel中
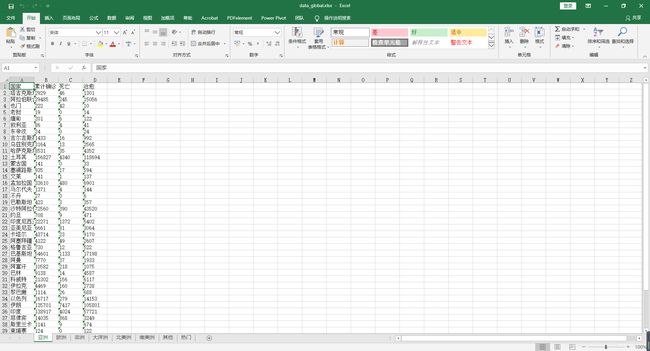
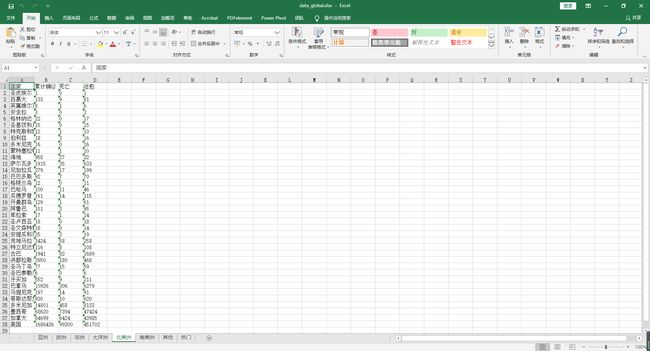
wb.save('./data_global.xlsx')
2.1 代码汇总
# 导入requests库
import requests
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia"
response = requests.get(url)
# 查看正确响应的结果,并与网页源代码比较一下,是否相同
result = response.text
# 导入xpath库,如未安装在cmd里面输入pip install xpath即可
from lxml import etree # 将数据转化为树形态
# 生成HTML对象
html = etree.HTML(result)
result = html.xpath('//script[@type="application/json"]/text()')
result = result[0]
# 导入Json库,此库无需安装
import json
result = json.loads(result)
result = result["component"]
# 获取国外当前数据
result = result[0]
result = result["globalList"]
# 导入模块
import openpyxl
# 创建工作簿
wb = openpyxl.Workbook()
for each in result:
title = each["area"] # 获取各州名
ws = wb.create_sheet(title) # 根据名称创建多个工作表
ws.append(["国家","累计确诊","死亡","治愈"]) # 写入表头至新建的表
for country in each["subList"]: # 可以从原始数据中看到各个国家的数据在"subList"键中
list_name = [country["country"],country["confirmed"],country["died"],country["crued"]]
for i in list_name:
if i == "":
i = "0"
ws.append(list_name)
# 保存至excel中
wb.save('./data_global.xlsx')
三、结果