写在之前:
之所以写这篇技术贴,有个原因:
1、打算每周写一篇技术贴
2、项目中需要有一个身份证生成机制,不可避免需求省市区区码
3、贴到网上,希望大神看见了,指点一二
ps:本文主要讲解BeautifulSoup的使用
工具:
以python做为脚本语言 用到的模块有:requests、json、BeautifulSoup
如果没有这些模块,请自行安装
相关链接:
爬取的网址:http://www.stats.gov.cn/tjsj/tjbz/xzqhdm/201703/t20170310_1471429.html
BeautifulSoup官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id71
requests官方文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
思路:
——>requests 请求网络,获取html页面
——>BeautifulSoup 解析html,获取省市区、区码数据,并存储为dict格式
——>json 将dict格式数据转化为文件存储在本地
1、获取html数据:
1.1 要抓取的页面如下:

要获取的页面.png
1.2 请求网络的代码如下:
def get_html(url):
"""
通过url, 获取html
:param url:
:return:
"""
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Cookie": "AD_RS_COOKIE=20080918; _gscu_1771678062=066576034ufdv312; _trs_uv=kd0u_6_j85d1bg5; _gscs_1771678062=06738257f4bdcm95|pv:4; _gscbrs_1771678062=1; _trs_ua_s_1=ad1x_6_j86p20ki",
"Host": "www.stats.gov.cn",
"Pragma": "no-cache",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0"
}
r = requests.get(url, headers=headers)
r.encoding = 'utf-8' # 这行不要忘了,不然你的获取的html里面的中文都是乱码
html = r.text
return html
headers = {}这一坨里面的东西,是来自下面的位置,自己查看:
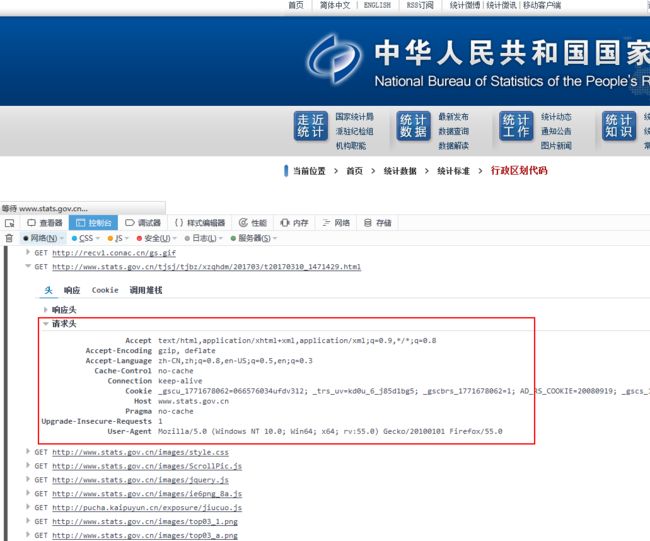
headers获取.png
2、解析html,直接贴代码,在代码里面讲解BeautifulSoup的使用。当然,只对用到的方法讲下,更多的知识请看官方文档。ps:因为是讲解,所以加了很多注释,代码也写的比较简单,请谅解:
def handle_html(html):
"""
处理html数据,获取想要的数据
:param html:
:return: code_dic:
"""
soup = BeautifulSoup(html, "lxml")
span_tags = soup.find_all("span", lang="EN-US")
# 创建soup对象,传入html数据,"lxml"为html解析器
# BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,创建的soup对象,可以理解为一个根结点
# 然后通过find_all方法,查找想要子节点,本次传的是span结点, lang="EN-US"为span的一个属性
# 意思就是说,查找 属性为lang="EN-US"的span结点,如果不理解,看官方文档
# 查找出来的结果,以list形式存储满足条件的span结点
code_dic = dict() # 创建空字典,存放遍历出来的数据,格式如下:
# {
# "110000": {
# "province_id": "",
# "provice_name": "",
# "city": {
# "110100":{
# "city_id": "",
# "city_name": "",
# "area": {
# "110101": {
# "area_id": "",
# "area_name": ""
# }
# }
# }
# }
# }
# }
for span in span_tags:
id_ = span.contents[0]
# 取出span里面的地区码, 如:110101
# contents是span里面的一个属性, 将span下子节点以列表的方式输出:
# 列表的第一个值存放的为 地区码
first_two = id_[0:2] # 取地区码前两位,代表 省
center_two = id_[2:4] # 取地区码中间两位,代表 市
latter_two = id_[-2:] # 取地区码后两间,代表 地区
if latter_two != "00":
"""地区"""
# 此处进行判断,后两位如果不是“00”,说明是地区码 精确到 地区
next_span = span.next_sibling # 获取当前span结点的兄弟结点,因为里面存储着地区名字
area_name = next_span.string.strip() # .string属性存储的是标签间的值is string
province_id = first_two + "0000" # 地区所在省 # 拼接当前地区的 省码
city_id = first_two + center_two + "00" # 拼接当前地区的 城市码
area_dic = code_dic[province_id]["city"][city_id]["area"] # 获取字典结构里面的 地区字段
# 下面这段,是一个安全判断,area_dic字典中应该没有该地区码的相关数据,一旦有,说明有地方出错了
if area_dic.get(id_) is not None:
print("area_dic error") # 打印一下出错的地方,方便查找
exit() # 退出程序
area_dic[id_] = {"area_id": id_, "area_name": area_name} # 走到这一步,说明没出错,然后把数据写入area_dic就可以了
continue # 跳出当前循环
elif center_two != "00":
"""城市"""
# 走到这一步,说明要判断的地区码,不是地区级别的,判断是否为市级地区码,如果是,将走如下代码:
next_span = span.next_sibling # 市级的城市名字,和地级的获取方式一样,也是存储在兄弟结点span中
city_name = next_span.string.strip()
province_id = first_two + "0000" # 当前城市所在省的省码
city_dic = code_dic[province_id]["city"] # 获取当前省下,存储城市的字典
if city_dic.get(id_) is not None: # 全安判断
print("city_dic error")
exit()
city_dic[id_] = {"city_id": id_, "city_name": city_name, "area": dict()} # 存储
continue # 跳出循环
else:
# 走到这一步,说明不是地级码,也不是市级码,只能是省级码了
if code_dic.get(id_) is not None: # 安全判断
print("city_dic error")
exit()
span_parent_next = span.parent.next_sibling
# 省的名字,不是存储在当前span的兄弟结点上,是在父结点的兄弟结点的子结点里面,有点绕... 大家可以看下html的那段代码就知道了
province_name = list(span_parent_next.descendants)[1].strip()
# .descendants 属性可以对所有属性span结点的子孙节点进行递归循环,返回的是迭代子对象,把他转化为list对象,取出里面的省名字
code_dic[id_] = {"province_id": id_, "province_name": province_name, "city": dict()} # 存储
continue # 跳出循环,这句其实多余了...不过我喜欢
return code_dic
3、获取了想要的数据后,就开始把它写入本地文件了,单独写一个方法,用于写操作的
# 这段很简单,我就不说了
def write_file_json(contents):
file_object = open('./area_2.json', 'w') # 放在当前目录下./area_2.json文件里,如果不存在,则创建
file_object.write(contents)
file_object.close()
4、然后在main函数里面组织下就可以了
def my_main():
html = get_html(URL) # 获取html
code_dic = handle_html(html) # 处理html,获取想要的数据
write_file_json(json.dumps(code_dic, ensure_ascii=False)) # 写入本地
6、然后运行下,看下得到的结果(得到的json数据,在线翻译了一下,不然没有格式):

结果.png
结语:
原创哦,如果有什么问题,大家可以提问