机器学习实战--住房月租金预测(1)
写在前面
上次分享的从0开始如何用一个月杀进机器学习比赛Top25%受到很多小伙伴的支持,今天继续分享这次比赛的收获。本文会讲解数据集的分析。话不多说,我们开始吧!
比赛分析
从机器学习模型的角度来说,这是一个典型的回归问题,其过程就是根据已有训练集进行训练,得到的模型再对测试进行测试。
常用算法:回归,树回归,GBDT,xgboost。整个过程如下图所示:
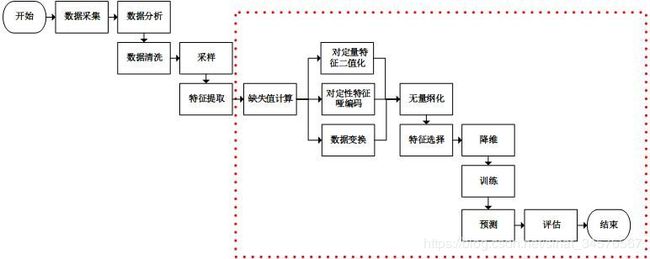
具体步骤:
一. 数据分析
1. 下载并加载数据
2. 了解每列数据的含义,数据的格式等,观察每个变量特征的意义以及对于问题的重要程度
3. 数据初步分析,通过绘图:初步了解数据之间的相关性,为构造特征工程以及模型建立做准备
二. 特征工程
将特征转换为模型可以辨别的类型(如处理缺失值,异常值处理,处理文本进行等)
三. 模型选择
1.根据目标函数确定学习类型,是无监督学习还是监督学习,是分类问题还是回归问题等选择合适的模型.
2.然后比较各个模型的分数,取效果较好的模型作为基础模型.
四. 模型融合
1. 最开始使用模型融合的方法来输出结果,最终的效果并不是特别好,所以自己还是选择了单模型。
2.看到了第一名开源的代码以后发现他们使用了多个模型的融合。
五. 修改特征和模型参数
1.可以通过添加或者修改特征,提高模型的上限.
2.通过修改模型的参数,使模型逼近上限
数据分析
数据集导入
首先使用pandas加载数据,使用pandas提供的head方法查看数据。
1# 导入相关 Python 库
2import warnings
3warnings.filterwarnings('ignore')#忽略一些警告
4import pandas as pd
5
6# 读取数据
7train = pd.read_csv('./train.csv')
8test = pd.read_csv('./test.csv')
9#使用head查看详细的数据
10train.head()

1train.info()

使用train.info()可以看出训练集共有196539个样本,算是一个比较小的数据集了,同样可以看出这个数据集中是存在缺失值的。使用describe()方法查看数据集的详细信息。

pandas给出了数值类型特征的数值信息,std是标准差,表示数据集的分布广度;三个百分数25、50、75是四分位点。
经过上面的分析数据集中存在中文,对接下来的操作会存在一定的影响,为了方便操作自己做了一个简单的替换并且删除无用的特征和自己暂时不方便处理的数据。
1# 导入相关 Python 库
2import warnings
3warnings.filterwarnings('ignore')#忽略一些警告
4
5import numpy as np
6import pandas as pd
7import seaborn as sns
8import matplotlib.pyplot as plt
9pd.set_option('display.max_columns', None)
10#%matplotlib inline
11# 读取数据
12columns = ['date', 'community','rent_apartment','floors','total_floors',
13 'sqft_living','house_orientation','living_status','bedrooms','halls','bathrooms',
14 'way_rent','area','local','subway_line','subway_station','subway_distance','renovated',
15 'price']
16
17train = pd.read_csv('./train.csv', names=columns)
18
19test_columns = ['id','date', 'community','rent_apartment','floors','total_floors',
20 'sqft_living','house_orientation','living_status','bedrooms','halls','bathrooms',
21 'way_rent','area','local','subway_line','subway_station','subway_distance','renovated']
22
23test = pd.read_csv('./test.csv', names=test_columns)
24test.drop(['id','date','house_orientation'], axis=1, inplace=True)
25
26# 删除日期(date)特征
27train.drop(['date','house_orientation'], axis=1, inplace=True)
特征提取
经过这次比赛自己感觉特征工程可能比选择哪种算法更加重要。接下来,我们就来研究一下哪些特征可能对模型训练有用。
所有特征相关度分析
1# 画出相关性热力图
2a = plt.subplots(figsize=(20, 12))#调整画布大小
3a = sns.heatmap(train_corr, vmax=.8, square=True)#画热力图 annot=True 显示系数

price 相关度特征排序
1# 寻找K个最相关的特征信息
2k = 10
3cols = train_corr.nlargest(k, 'price')['price'].index
4cm = np.corrcoef(train[cols].values.T)
5sns.set(font_scale=1.5)
6hm = plt.subplots(figsize=(20, 12))#调整画布大小
7hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
8plt.show()
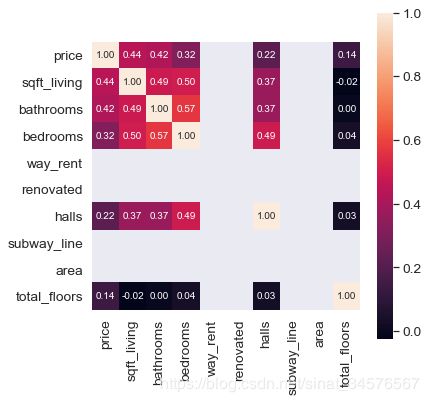
这个图好像有点尴尬,竟然残缺了这么多数据,一直没有去查这是什么原因造成的,有知道的小伙伴可以在留言区交流哦,虽然有残缺不过没有关系至少大致能够知道影响价格的几个重要特征。人们对于数值或许不够敏感,从上面的图看不出数据的特点,那么我们可以通过绘制直方图的形式将特征的数值分布展示出来。

Price 和相关变量之间的散点图
1sns.set()
2cols = [ 'price','sqft_living','bedrooms','bathrooms',
3 'halls']
4sns.pairplot(train[cols], size = 2.5)
5plt.show();

最后小声逼逼,个人觉着这些分析其实用处不是特别大,不知道小伙伴们有什么独特的见解,欢迎在留言区留言。
今天的介绍就到这,缺失值,离散点和异常值的处理将在下篇文章中更新,欢迎大家继续关注。第一次参加机器学习的比赛,也是第一次写比赛分享贴,希望大家多多交流。
【推荐阅读】
【LeetCode】汇总贴(NO.1-20)
打通Python学习的任督二脉
Python之禅