PetShop之业务逻辑层设计
《解剖PetShop》系列之五
业务逻辑层(Business Logic Layer)无疑是系统架构中体现核心价值的部分。它的关注点主要集中在业务规则的制定、业务流程的实现等与业务需求有关的系统设计,也即是说它是与系统所应对的领域(Domain)逻辑有关,很多时候,我们也将业务逻辑层称为领域层。例如Martin Fowler在《Patterns of Enterprise Application Architecture》一书中,将整个架构分为三个主要的层:表示层、领域层和数据源层。作为领域驱动设计的先驱Eric Evans,对业务逻辑层作了更细致地划分,细分为应用层与领域层,通过分层进一步将领域逻辑与领域逻辑的解决方案分离。
五 PetShop之业务逻辑层设计
业务逻辑层在体系架构中的位置很关键,它处于数据访问层与表示层中间,起到了数据交换中承上启下的作用。由于层是一种弱耦合结构,层与层之间的依赖是向下的,底层对于上层而言是“无知”的,改变上层的设计对于其调用的底层而言没有任何影响。如果在分层设计时,遵循了面向接口设计的思想,那么这种向下的依赖也应该是一种弱依赖关系。因而在不改变接口定义的前提下,理想的分层式架构,应该是一个支持可抽取、可替换的“抽屉”式架构。正因为如此,业务逻辑层的设计对于一个支持可扩展的架构尤为关键,因为它扮演了两个不同的角色。对于数据访问层而言,它是调用者;对于表示层而言,它却是被调用者。依赖与被依赖的关系都纠结在业务逻辑层上,如何实现依赖关系的解耦,则是除了实现业务逻辑之外留给设计师的任务。
5.1 与领域专家合作
设计业务逻辑层最大的障碍不在于技术,而在于对领域业务的分析与理解。很难想象一个不熟悉该领域业务规则和流程的架构设计师能够设计出合乎客户需求的系统架构。几乎可以下定结论的是,业务逻辑层的设计过程必须有领域专家的参与。在我曾经参与开发的项目中,所涉及的领域就涵盖了电力、半导体、汽车等诸多行业,如果缺乏这些领域的专家,软件架构的设计尤其是业务逻辑层的设计就无从谈起。这个结论唯一的例外是,架构设计师同时又是该领域的专家。然而,正所谓“千军易得,一将难求”,我们很难寻觅到这样卓越出众的人才。
领域专家在团队中扮演的角色通常称为Business Consultor(业务咨询师),负责提供与领域业务有关的咨询,与架构师一起参与架构与数据库的设计,撰写需求文档和设计用例(或者用户故事User Story)。如果在测试阶段,还应该包括撰写测试用例。理想的状态是,领域专家应该参与到整个项目的开发过程中,而不仅仅是需求阶段。
领域专家可以是专门聘请的对该领域具有较深造诣的咨询师,也可以是作为需求提供方的客户。在极限编程(Extreme Programming)中,就将客户作为领域专家引入到整个开发团队中。它强调了现场客户原则。现场客户需要参与到计划游戏、开发迭代、编码测试等项目开发的各个阶段。由于领域专家与设计师以及开发人员组成了一个团队,贯穿开发过程的始终,就可以避免需求理解错误的情况出现。即使项目的开发与实际需求不符,也可以在项目早期及时修正,从而避免了项目不必要的延期,加强了对项目过程和成本的控制。正如Steve McConnell在构建活动的前期准备中提及的一个原则:发现错误的时间要尽可能接近引入该错误的时间。需求的缺陷在系统中潜伏的时间越长,代价就越昂贵。如果在项目开发中能够与领域专家充分的合作,就可以最大效果地规避这样一种恶性的链式反应。
传统的软件开发模型同样重视与领域专家的合作,但这种合作主要集中在需求分析阶段。例如瀑布模型,就非常强调早期计划与需求调研。然而这种未雨绸缪的早期计划方式,对架构师与需求调研人员的技能要求非常高,它强调需求文档的精确性,一旦分析出现偏差,或者需求发生变更,当项目开发进入设计阶段后,由于缺乏与领域专家沟通与合作的机制,开发人员估量不到这些错误与误差,因而难以及时作出修正。一旦这些问题像毒瘤一般在系统中蔓延开来,逐渐暴露在开发人员面前时,已经成了一座难以逾越的高山。我们需要消耗更多的人力物力,才能够修正这些错误,从而导致开发成本成数量级的增加,甚至于导致项目延期。当然还有一个好的选择,就是放弃整个项目。这样的例子不胜枚举,事实上,项目开发的“滑铁卢”,究其原因,大部分都是因为业务逻辑分析上出现了问题。
迭代式模型较之瀑布模型有很大地改进,因为它允许变更、优化系统需求,整个迭代过程实际上就是与领域专家的合作过程,通过向客户演示迭代所产生的系统功能,从而及时获取反馈,并逐一解决迭代演示中出现的问题,保证系统向着合乎客户需求的方向演化。因而,迭代式模型往往能够解决早期计划不足的问题,它允许在发现缺陷的时候,在需求变更的时候重新设计、重新编码并重新测试。
无论采用何种开发模型,与领域专家的合作都将成为项目成败与否的关键。这基于一个软件开发的普遍真理,那就是世界上没有不变的需求。一句经典名言是:“没有不变的需求,世上的软件都改动过3次以上,唯一一个只改动过两次的软件的拥有者已经死了,死在去修改需求的路上。”一语道尽了软件开发的残酷与艰辛!
那么应该如何加强与领域专家的合作呢?James Carey和Brent Carlson根据他们在参与的IBM SanFrancisco项目中获得的经验,提出了Innocent Questions模式,其意义即“改进领域专家和技术专家的沟通质量”。在一个项目团队中,如果我们没有一位既能担任首席架构师,同时又是领域专家的人选,那么加强领域专家与技术专家的合作就显得尤为重要了。毕竟,作为一个领域专家而言,可能并不熟悉软件设计方法学,也不具备面向对象开发和架构设计的能力,同样,大部分技术专家很有可能对该项目所涉及的业务领域仅停留在一知半解的地步。如果领域专家与技术专家不能有效沟通,则整个项目的前途就岌岌可危了。
Innocent Questions模式提出的解决方案包括:
(1)选用可以与人和谐相处的人员组建开发团队;
(2)清楚地定义角色和职权;
(3)明确定义需要的交互点;
(4)保持团队紧密;
(5)雇佣优秀的人。
事实上,这已经从技术的角度上升到对团队的管理层次了。就好比篮球运动一样,即使你的球队集合了五名世界上最顶尖最有天赋的球员,如果各自为战,要想取得比赛的胜利依旧是非常困难的。团队精神与权责分明才是取得胜利的保障,软件开发同样如此。
与领域专家合作的基础是保证开发团队中永远保留至少一名领域专家。他可以是系统的客户,第三方公司的咨询师,最理想是自己公司雇佣的专家。如果项目中缺乏这样的一个人,那么我的建议是去雇佣他,如果你不想看到项目遭遇“西伯利亚寒流”的话。
确定领域专家的角色任务与职责。必须要让团队中的每一个人明确领域专家在整个团队中究竟扮演什么样的角色,他的职责是什么。一个合格的领域专家必须对业务领域有足够深入的理解,他应该是一个能够俯瞰整个系统需求、总揽全局的人物。在项目开发过程中,将由他负责业务规则和流程的制定,负责与客户的沟通,需求的调研与讨论,并于设计师一起参与系统架构的设计。编档是领域专家必须参与的工作,无论是需求文档还是设计文档,以及用例的编写,领域专家或者提出意见,或者作为撰写的作者,至少他也应该是评审委员会的重要成员。
规范业务领域的术语和技术术语。领域专家和技术专家必须在保证不产生二义性的语义环境下进行沟通与交流。如果出现理解上的分歧,我们必须及时解决,通过讨论确立术语标准。很难想象两个语言不通的人能够相互合作愉快,解决的办法是加入一位翻译人员。在领域专家与技术专家之间搭建一座语义上的桥梁,使其能够相互理解、相互认同。还有一个办法是在团队内部开展培训活动。尤其对于开发人员而言,或多或少地了解一些业务领域知识,对于项目的开发有很大的帮助。在我参与过的半导体领域的项目开发,团队就专门邀请了半导体行业的专家就生产过程的业务逻辑进行了全方位的介绍与培训。正所谓“磨刀不误砍柴工”,虽然我们消费了培训的时间,但对于掌握了业务规则与流程的开发人员,却能够提升项目开发进度,总体上节约了开发成本。
加强与客户的沟通。客户同时也可以作为团队的领域专家,极限编程的现场客户原则是最好的示例。但现实并不都如此的完美,在无法要求客户成为开发团队中的固定一员时,聘请或者安排一个专门的领域专家,加强与客户的沟通,就显得尤为重要。项目可以通过领域专家获得客户的及时反馈。而通过领域专家去了解变更了的需求,会在最大程度上减少需求误差的可能。
5.2 业务逻辑层的模式应用
Martin Fowler在《企业应用架构模式》一书中对领域层(即业务逻辑层)的架构模式作了整体概括,他将业务逻辑设计分为三种主要的模式:Transaction Script、Domain Model和Table Module。
Transaction Script模式将业务逻辑看作是一个个过程,是比较典型的面向过程开发模式。应用Transaction Script模式可以不需要数据访问层,而是利用SQL语句直接访问数据库。为了有效地管理SQL语句,可以将与数据库访问有关的行为放到一个专门的Gateway类中。应用Transaction Script模式不需要太多面向对象知识,简单直接的特性是该模式全部价值之所在。因而,在许多业务逻辑相对简单的项目中,应用Transaction Script模式较多。
Domain Model模式是典型的面向对象设计思想的体现。它充分考虑了业务逻辑的复杂多变,引入了Strategy模式等设计模式思想,并通过建立领域对象以及抽象接口,实现模式的可扩展性,并利用面向对象思想与身俱来的特性,如继承、封装与多态,用于处理复杂多变的业务逻辑。唯一制约该模式应用的是对象与关系数据库的映射。我们可以引入ORM工具,或者利用Data Mapper模式来完成关系向对象的映射。
与Domain Model模式相似的是Table Module模式,它同样具有面向对象设计的思想,唯一不同的是它获得的对象并非是单纯的领域对象,而是DataSet对象。如果为关系数据表与对象建立一个简单的映射关系,那么Domain Model模式就是为数据表中的每一条记录建立一个领域对象,而Table Module模式则是将整个数据表看作是一个完整的对象。虽然利用DataSet对象会丢失面向对象的基本特性,但它在为表示层提供数据源支持方面却有着得天独厚的优势。尤其是在.Net平台下,ADO.NET与Web控件都为Table Module模式提供了生长的肥沃土壤。
5.3 PetShop的业务逻辑层设计
PetShop在业务逻辑层设计中引入了Domain Model模式,这与数据访问层对于数据对象的支持是分不开的。由于PetShop并没有对宠物网上商店的业务逻辑进行深入,也省略了许多复杂细节的商务逻辑,因而在Domain Model模式的应用上并不明显。最典型地应该是对Order领域对象的处理方式,通过引入Strategy模式完成对插入订单行为的封装。关于这一点,我已在第27章有了详尽的描述,这里就不再赘述。
本应是系统架构设计中最核心的业务逻辑层,由于简化了业务流程的缘故,使得PetShop在这一层的设计有些乏善可陈。虽然在业务逻辑层中,针对B2C业务定义了相关的领域对象,但这些领域对象仅仅是完成了对数据访问层中数据对象的简单封装而已,其目的仅在于分离层次,以支持对各种数据库的扩展,同时将SQL语句排除在业务逻辑层外,避免了SQL语句的四处蔓延。
最能体现PetShop业务逻辑的除了对订单的管理之外,还包括购物车(Shopping Cart)与Wish List的管理。在PetShop的BLL模块中,定义了Cart类来负责相关的业务逻辑,定义如下:
[Serializable]
public class Cart
{
private Dictionary cartItems = new Dictionary ();
public decimal Total
{
get
{
decimal total = 0;
foreach (CartItemInfo item in cartItems.Values)
total += item.Price * item.Quantity;
return total;
}
}
public void SetQuantity(string itemId, int qty)
{
cartItems[itemId].Quantity = qty;
}
public int Count
{
get { return cartItems.Count; }
}
public void Add(string itemId)
{
CartItemInfo cartItem;
if (!cartItems.TryGetValue(itemId, out cartItem))
{
Item item = new Item();
ItemInfo data = item.GetItem(itemId);
if (data != null)
{
CartItemInfo newItem = new CartItemInfo(itemId, data.ProductName, 1, (decimal)data.Price, data.Name, data.CategoryId, data.ProductId);
cartItems.Add(itemId, newItem);
}
}
else
cartItem.Quantity++;
}
//其他方法略;
}
Cart类通过一个Dictionary对象来负责对购物车内容的存储,同时定义了Add、Remove、Clear等方法,来实现对购物车内容的管理。
在前面我提到PetShop业务逻辑层中的领域对象仅仅是完成对数据对象的简单封装,但这种分离层次的方法在架构设计中依然扮演了举足轻重的作用。以Cart类的Add()方法为例,在方法内部引入了PetShop.BLL.Item领域对象,并调用了Item对象的GetItem()方法。如果没有在业务逻辑层封装Item对象,而是直接调用数据访问层的Item数据对象,为保证层次间的弱依赖关系,就需要调用工厂对象的工厂方法来创建PetShop.IDAL.IItem接口类型对象。一旦数据访问层的Item对象被多次调用,就会造成重复代码,既不离于程序的修改与扩展,也导致程序结构生长为臃肿的态势。
此外,领域对象对数据访问层数据对象的封装,也有利于表示层对业务逻辑层的调用。在三层式架构中,表示层应该是对于数据访问层是“无知”的,这样既减少了层与层间的依赖关系,也能有效避免“循环依赖”的后果。
值得商榷的是Cart类的Total属性。其值的获取是通过遍历购物车集合,然后累加价格与商品数量的乘积。这里显然简化了业务逻辑,而没有充分考虑需求的扩展。事实上,这种获取购物车总价格的算法,在大多数情况下仅仅是其中的一种策略而已,我们还应该考虑折扣的情况。例如,当总价格超过100元时,可以给与顾客一定的折扣,这是与网站的促销计划相关的。除了给与折扣的促销计划外,网站也可以考虑赠送礼品的促销策略,因此我们有必要引入Strategy模式,定义接口IOnSaleStrategy:
public interface IOnSaleStrategy
{
decimal CalculateTotalPrice(Dictionary cartItems);
}
如此一来,我们可以为Cart类定义一个有参数的构造函数:
private IOnSaleStrategy m_onSale;
public Cart(IOnSaleStrategy onSale)
{
m_onSale = onSale;
}
那么Total属性就可以修改为:
public decimal Total
{
get {return m_onSale.CalculateTotalPrice(cartItems);}
}
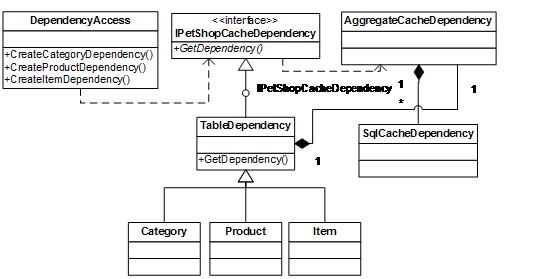
如此一来,就可以使得Cart类能够有效地支持网站推出的促销计划,也符合开-闭原则。同样的,这种设计方式也是Domain Model模式的体现。修改后的设计如图5-1所示:
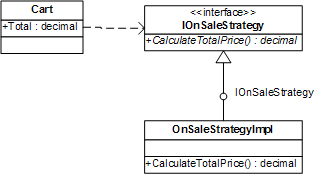
图5-1 引入Strategy模式
作为一个B2C的电子商务架构,它所涉及的业务领域已为大部分设计师与开发人员所熟悉,因而在本例中,与领域专家的合作显得并不那么重要。然而,如果我们要开发一个成功的电子商务网站,与领域专家的合作仍然是必不可少的。以订单的管理而言,如果考虑复杂的商业应用,就需要管理订单的跟踪(Tracking),与网上银行的合作,账户安全性,库存管理,物流管理,以及客户关系管理(CRM)。整个业务过程却涵盖了诸如电子商务、银行、物流、客户关系学等诸多领域,如果没有领域专家的参与,业务逻辑层的设计也许会“败走麦城”。
5.4 与数据访问层的通信
业务逻辑层需要与数据访问层通信,利用数据访问层访问数据库,因此业务逻辑层与数据访问层之间就存在依赖关系。在数据访问层引入接口程序集以及数据工厂的设计前提下,能够做到两者间关系为弱依赖。我们从业务逻辑层的引用程序集中可以看到,BLL模块并没有引用SQLServerDAL和OracleDAL程序集。在业务逻辑层中,有关数据访问层中数据对象的调用,均利用多态原理定义了抽象的接口类型对象,然后利用工厂对象的工厂方法创建具体的数据对象。如PetShop.BLL.PetShop领域对象所示:
namespace PetShop.BLL
{
public class Product
{
//根据工厂对象创建IProduct接口类型实例;
private static readonly IProduct dal = PetShop.DALFactory.DataAccess.CreateProduct();
//调用IProduct对象的接口方法GetProductByCategory();
public IList
GetProductsByCategory(string category)
{
// 如果为空则新建List对象;
if(string.IsNullOrEmpty(category))
return new List ();
// 通过数据访问层的数据对象访问数据库;
return dal.GetProductsByCategory(category);
}
//其他方法略;
}
}
在领域对象Product类中,利用数据访问层的工厂类DALFactory.DataAccess创建PetShop.IDAL.IProduct类型的实例,如此就可以解除对具体程序集SQLServerDAL或OracleDAL的依赖。只要PetShop.IDAL的接口方法不变,即使修改了IDAL接口模块的具体实现,都不会影响业务逻辑层的实现。这种松散的弱耦合关系,才能够最大程度地支持架构的可扩展。
领域对象Product实际上还完成了对数据对象Product的封装,它们暴露在外的接口方法是一致地,正是通过封装,使得表示层可以完全脱离数据库以及数据访问层,表示层的调用者仅需要关注业务逻辑层的实现逻辑,以及领域对象暴露的接口和调用方式。事实上,只要设计合理,规范了各个层次的接口方法,三层式架构的设计完全可以分离开由不同的开发人员同时开发,这就可以有效地利用开发资源,缩短项目开发周期。
5.5 面向接口设计
也许是业务逻辑比较简单地缘故,在业务逻辑层的设计中,并没有秉承在数据访问层中面向接口设计的思想。除了完成对插入订单策略的抽象外,整个业务逻辑层仅以BLL模块实现,没有为领域对象定义抽象的接口。因而PetShop的表示层与业务逻辑层就存在强依赖关系,如果业务逻辑层中的需求发生变更,就必然会影响表示层的实现。唯一可堪欣慰的是,由于我们采用分层式架构将用户界面与业务领域逻辑完全分离,一旦用户界面发生更改,例如将B/S架构修改为C/S架构,那么业务逻辑层的实现模块是可以完全重用的。
然而,最理想的方式仍然是面向接口设计。根据第28章对ASP.NET缓存的分析,我们可以将表示层App_Code下的Proxy类与Utility类划分到业务逻辑层中,并修改这些静态类为实例类,并将这些类中与业务领域有关的方法抽象为接口,然后建立如数据访问层一样的抽象工厂。通过“依赖注入”方式,解除与具体领域对象类的依赖,使得表示层仅依赖于业务逻辑层的接口程序集以及工厂模块。
那么,这样的设计是否有“过度设计”的嫌疑呢?我们需要依据业务逻辑的需求情况而定。此外,如果我们需要引入缓存机制,为领域对象创建代理类,那么为领域对象建立接口,就显得尤为必要。我们可以建立一个专门的接口模块IBLL,用以定义领域对象的接口。以Product领域对象为例,我们可以建立IProduct接口:
public interface IProduct
{
IList GetProductByCategory(string category);
IList GetProductByCategory(string[] keywords);
ProductInfo GetProduct(string productId);
}
在BLL模块中可以引入对IBLL程序集的依赖,则领域对象Product的定义如下:
public class Product:IProduct
{
public IList GetProductByCategory(string category) { //实现略; }
public IList GetProductByCategory(string[] keywords) { //实现略; }
public ProductInfo GetProduct(string productId) { //实现略; }
}
然后我们可以为代理对象建立专门的程序集BLLProxy,它不仅引入对IBLL程序集的依赖,同时还将依赖于BLL程序集。此时代理对象ProductDataProxy的定义如下:
using PetShop.IBLL;
using PetShop.BLL;
namespace PetShop.BLLProxy
{
public class ProductDataProxy:IProduct
{
public IList GetProductByCategory(string category)
{
Product product = new Product();
//其他实现略;
}
public IList GetProductByCategory(string[] keywords) { //实现略; }
public ProductInfo GetProduct(string productId) { //实现略; }
}
}
如此的设计正是典型的Proxy模式,其类结构如图5-2所示:
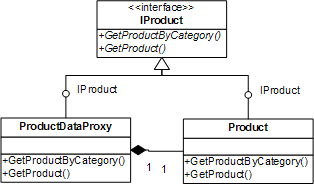
图5-2 Proxy模式
参照数据访问层的设计方法,我们可以为领域对象及代理对象建立抽象工厂,并在web.config中配置相关的配置节,然后利用反射技术创建具体的对象实例。如此一来,表示层就可以仅仅依赖PetShop.IBLL程序集以及工厂模块,如此就可以解除表示层与具体领域对象之间的依赖关系。表示层与修改后的业务逻辑层的关系如图5-3所示:
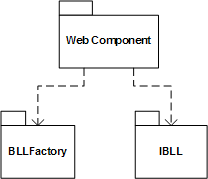
图5-3 修改后的业务逻辑层与表示层的关系
图5-4则是PetShop 4.0原有设计的层次关系图:

图5-4 PetShop 4.0中表示层与业务逻辑层的关系
通过比较图5-3与图5-4,虽然后者不管是模块的个数,还是模块之间的关系,都相对更加简单,然而Web Component组件与业务逻辑层之间却是强耦合的,这样的设计不利于应对业务扩展与需求变更。通过引入接口模块IBLL与工厂模块BLLFactory,解除了与具体模块BLL的依赖关系。这种设计对于业务逻辑相对比较复杂的系统而言,更符合面向对象的设计思想,有利于我们建立可抽取、可替换的“抽屉”式三层架构。








![[收藏]PetShop之业务逻辑层设计_第1张图片](http://img.e-com-net.com/image/info8/2950fd33fc824085aab8a2d678972158.gif)